1. 引言
本文将带你深入理解如何使用 Apache Druid 处理事件驱动数据。我们将从事件数据的基本概念讲起,逐步剖析 Druid 的架构设计,并动手搭建一个本地环境,完成从数据摄入、存储到查询的完整数据流水线。
通过本教程,你不仅能掌握 Druid 的核心机制,还能为后续构建高性能、低延迟的实时分析系统打下坚实基础。文中涉及的数据摄入、查询优化和集群部署等环节,都是生产环境中常见的关键点,踩坑预警 ⚠️。
2. 基本概念
在深入 Druid 的内部机制之前,先明确两个核心概念:事件数据和 Druid 本身。这些是构建现代实时分析系统的基石。
2.1. 什么是事件数据?
事件数据指的是 在特定时间点发生的某个状态变化所生成的信息记录。这类数据在当今系统中无处不在 —— 从传统的应用日志、用户行为埋点,到物联网设备的传感器上报,本质都是事件流。
它们的特点是:
- ✅ 高并发、大规模持续产生
- ✅ 结构化或半结构化(如 JSON)
- ✅ 天然带有时间戳
- ✅ 支撑实时监控、用户画像、自动化决策等场景
在事件驱动架构(Event-Driven Architecture)中,事件数据更是核心载体,驱动着系统的异步通信与状态流转。
2.2. 什么是 Apache Druid?
Apache Druid 是 一个专为事件数据设计的实时分析型数据库,主打“高吞吐摄入 + 低延迟查询”。它于 2011 年启动,2015 年正式成为 Apache 顶级项目。
其核心优势包括:
- ✅ 实时数据摄入(支持 Kafka、Kinesis 等流式源)
- ✅ 毫秒级 OLAP 查询响应
- ✅ 高可用、分布式架构
- ✅ 支持海量历史数据与实时数据的统一查询
Druid 在 BI 分析、用户行为分析、监控告警等场景中被广泛使用。名字“Druid”寓意其架构灵活,能“变身”适应不同数据问题。
3. Druid 架构
Druid 是一个 基于 Java 开发的列式、分布式数据存储系统,专为高性能事件数据分析而生。它能高效处理大规模事件数据,并支持任意维度的切片(slice-and-dice)分析。
下面我们拆解其核心架构组件。
3.1. 数据存储设计
Druid 的数据组织方式是其高性能的关键。理解其存储结构,有助于合理设计数据摄入策略。
- 数据源(datasource):逻辑上类似于关系型数据库的“表”,是数据的顶层容器。
- 分块(chunk):默认按时间范围对数据源进行分区,例如每小时一个 chunk。
- 段(segment):每个 chunk 可进一步拆分为一个或多个 segment,每个 segment 是一个独立的文件,包含多行数据。
一个 datasource 可能包含从几个到数百万个 segment。
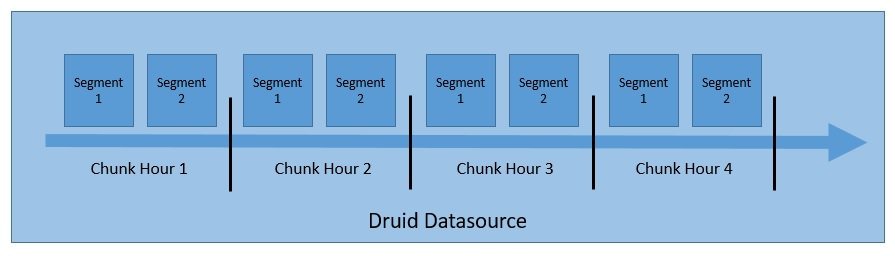
图:Druid 数据存储结构示意图
3.2. 核心进程(Processes)
Druid 采用多进程、分布式架构,各组件职责分离,可独立横向扩展。
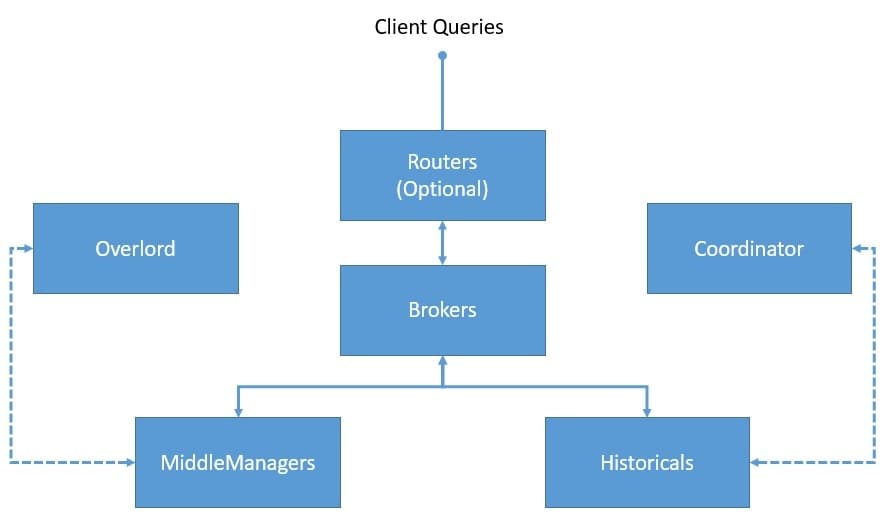
图:Druid 核心进程示意图
各进程职责如下:
- ✅ Coordinator:管理 segment 的加载与卸载,协调 Historical 节点。
- ✅ Overlord:任务调度中心,接收并分发数据摄入任务。
- ✅ Broker:查询入口,接收查询请求,路由到包含目标 segment 的节点。
- ✅ Router(可选):统一入口,可将请求路由到 Broker 或 Overlord,提供访问隔离。
- ✅ Historical:存储并提供已持久化的 segment 查询服务。
- ✅ MiddleManager:执行数据摄入任务的工作节点,任务在独立的 Peon JVM 中运行,实现资源隔离。
3.3. 外部依赖
Druid 集群正常运行依赖以下外部系统:
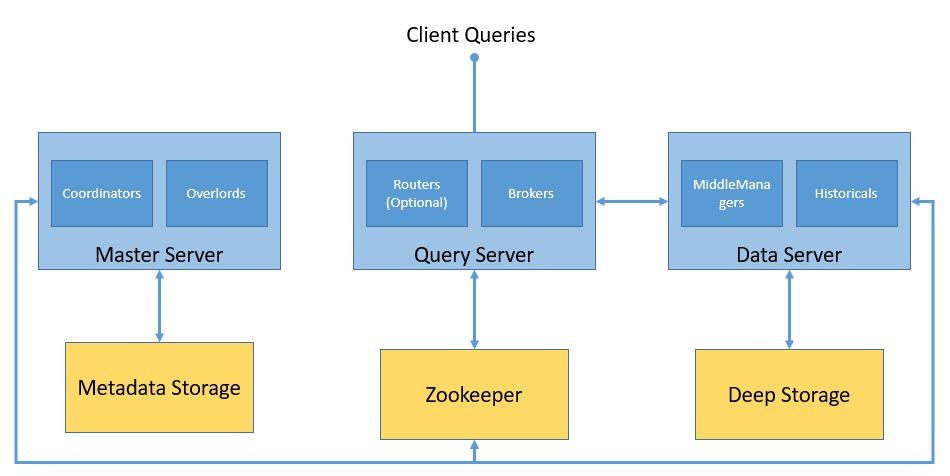
图:Druid 集群整体架构
- Deep Storage:持久化存储所有摄入的数据(如 S3、HDFS),用于备份和节点间数据传输,不直接响应查询。
- Metadata Storage:存储系统元数据,如 segment 信息、任务状态。通常使用 MySQL、PostgreSQL 等关系型数据库。
- Zookeeper:管理集群协调状态,负责 Leader 选举、服务发现、分布式锁等。
4. Druid 环境搭建
Druid 本是为生产环境设计的分布式集群,但搭建完整的生产级集群较为复杂。对于学习和测试,官方提供了 Docker 快速部署方案。
⚠️ 注意:Druid 仅支持 Unix-like 系统(Linux/macOS),不支持原生 Windows。但通过 Docker,我们可以在 Windows 上运行。
快速部署步骤
克隆官方仓库并进入 Docker 目录:
git clone https://github.com/apache/druid.git cd druid/distribution/docker确保存在
environment配置文件(用于设置环境变量)。启动集群:
docker-compose up该命令会启动包含所有 Druid 进程及外部依赖(ZK、Metadata DB)的容器。
访问控制台:
http://localhost:8888
💡 提示:Druid 对内存要求较高,建议为 Docker 分配至少 8GB 内存。
5. 数据摄入
数据摄入(Ingestion)是构建 Druid 数据流水线的第一步。Druid 支持多种摄入方式,以适应不同场景。
5.1. 数据模型
我们使用 Druid 官方示例数据集:wikiticker-2015-09-12-sampled.json.gz,记录了维基百科的编辑事件。样例数据如下:
{
"time": "2015-09-12T02:10:26.679Z",
"channel": "#pt.wikipedia",
"cityName": null,
"comment": "Houveram problemas na última edição e tive de refazê-las, junto com as atualizações da página.",
"countryIsoCode": "BR",
"countryName": "Brazil",
"isAnonymous": true,
"isMinor": false,
"isNew": false,
"isRobot": false,
"isUnpatrolled": true,
"metroCode": null,
"namespace": "Main",
"page": "Catarina Muniz",
"regionIsoCode": null,
"regionName": null,
"user": "181.213.37.148",
"delta": 197,
"added": 197,
"deleted": 0
}
在 Druid 中,数据字段分为三类:
- ✅ 时间戳(Timestamp):必须字段,用于时间分区。本例中为
time字段。 - ✅ 维度(Dimensions):用于分组(GROUP BY)、过滤(WHERE)的字段,原样存储。
- ✅ 指标(Metrics):用于聚合计算(如 SUM、COUNT)的字段,默认以聚合形式存储。
5.2. 摄入方式
Druid 支持两大类数据摄入模式:
| 模式 | 适用场景 | 特点 |
|---|---|---|
| 流式摄入(Streaming Ingestion) | 实时数据流(如 Kafka) | 低延迟,持续摄入 |
| 批处理摄入(Batched Ingestion) | 静态文件(如 HDFS、本地文件) | 简单直接,适合离线数据 |
5.3. 定义任务配置
本例使用 原生批处理摄入(Native Batch Ingestion),通过 JSON 任务配置定义摄入逻辑。
创建文件 wikipedia-index.json:
{
"type" : "index_parallel",
"spec" : {
"dataSchema" : {
"dataSource" : "wikipedia",
"dimensionsSpec" : {
"dimensions" : [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
{ "name": "added", "type": "long" },
{ "name": "deleted", "type": "long" },
{ "name": "delta", "type": "long" }
]
},
"timestampSpec": {
"column": "time",
"format": "iso"
},
"metricsSpec" : [],
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none",
"intervals" : ["2015-09-12/2015-09-13"],
"rollup" : false
}
},
"ioConfig" : {
"type" : "index_parallel",
"inputSource" : {
"type" : "local",
"baseDir" : "quickstart/tutorial/",
"filter" : "wikiticker-2015-09-12-sampled.json.gz"
},
"inputFormat" : {
"type": "json"
},
"appendToExisting" : false
},
"tuningConfig" : {
"type" : "index_parallel",
"maxRowsPerSegment" : 5000000,
"maxRowsInMemory" : 25000
}
}
}
配置要点说明:
dataSource: 数据源名称为wikipediatimestampSpec: 指定time字段为时间戳dimensions: 定义了多个维度字段,added、deleted、delta显式声明为 long 类型metricsSpec: 本例未使用指标聚合rollup: 关闭,保留原始事件粒度inputSource: 从本地目录读取压缩 JSON 文件segmentGranularity: 按天分区
✅ 注意:该示例数据文件已内置在 Druid Docker 镜像的
quickstart/tutorial/目录下,无需手动下载。
5.4. 提交摄入任务
通过 HTTP 接口向 Overlord 提交任务:
curl -X POST \
-H 'Content-Type:application/json' \
-d @wikipedia-index.json \
http://localhost:8081/druid/indexer/v1/task
✅ 成功提交后,返回任务 ID。可通过 Druid 控制台(http://localhost:8088)查看任务状态和 segment 加载情况。
5.5. 高级摄入概念
Roll-up(数据聚合)
在摄入时对具有相同维度和时间戳的行进行预聚合,可大幅减少存储空间和提升查询性能。但会损失明细数据,需权衡使用。
二级分区(Secondary Partitioning)
除时间分区外,可基于高基数维度(如 user_id)进行二次分区,提升查询局部性,减少扫描范围。
6. 数据查询
数据摄入完成后,即可进行查询。Druid 支持多种查询方式。
6.1. 原生查询(Native Queries)
使用 JSON 格式的原生查询,直接与 Broker 交互。
创建 simple_query_native.json:
{
"queryType" : "topN",
"dataSource" : "wikipedia",
"intervals" : ["2015-09-12/2015-09-13"],
"granularity" : "all",
"dimension" : "page",
"metric" : "count",
"threshold" : 10,
"aggregations" : [
{
"type" : "count",
"name" : "count"
}
]
}
执行查询:
curl -X POST \
-H 'Content-Type:application/json' \
-d @simple_query_native.json \
http://localhost:8888/druid/v2?pretty
返回结果示例:
[ {
"timestamp" : "2015-09-12T00:46:58.771Z",
"result" : [ {
"count" : 33,
"page" : "Wikipedia:Vandalismusmeldung"
}, {
"count" : 28,
"page" : "User:Cyde/List of candidates for speedy deletion/Subpage"
}, ... ]
} ]
6.2. Druid SQL
Druid 提供了 SQL 接口,底层会自动转换为原生查询。
创建 simple_query_sql.json:
{
"query":"SELECT page, COUNT(*) AS counts FROM wikipedia WHERE \"__time\" BETWEEN TIMESTAMP '2015-09-12 00:00:00' AND TIMESTAMP '2015-09-13 00:00:00' GROUP BY page ORDER BY counts DESC LIMIT 10"
}
⚠️ 注意:SQL 字符串必须在一行内,避免换行。
执行查询:
curl -X POST \
-H 'Content-Type:application/json' \
-d @simple_query_sql.json \
http://localhost:8888/druid/v2/sql
结果与原生查询一致,但语法更友好。
6.3. 常见查询类型
| 查询类型 | 用途 | 示例 |
|---|---|---|
| TopN | 获取某维度下指标最高的 N 条记录 | 本文示例 |
| Timeseries | 按时间序列返回聚合值 | 每日编辑总数 |
| GroupBy | 按维度分组返回聚合结果 | 按国家分组统计编辑数 |
| Scan | 扫描原始数据(不推荐用于大结果集) | 导出明细 |
| Search | 全文搜索维度值 | 搜索包含“Corbyn”的页面 |
6.4. 高级查询特性
- ✅ Join 与 Lookup:支持维度表关联,但建议在摄入时做 ETL 预关联,避免运行时 Join 影响性能。
- ✅ 多租户(Multitenancy):通过独立数据源或分区实现租户隔离。
- ✅ 查询缓存(Query Caching):支持 Segment 级和结果级缓存,可配置为内存或外部存储(如 Redis),显著提升重复查询性能。
7. 语言绑定(Java Client)
虽然 Druid 原生使用 JSON,但复杂查询用 Java 构建更方便。社区提供了 druidry 库。
Maven 依赖
<dependency>
<groupId>in.zapr.druid</groupId>
<artifactId>druidry</artifactId>
<version>2.14</version>
</dependency>
构建 TopN 查询
DateTime startTime = new DateTime(2015, 9, 12, 0, 0, 0, DateTimeZone.UTC);
DateTime endTime = new DateTime(2015, 9, 13, 0, 0, 0, DateTimeZone.UTC);
Interval interval = new Interval(startTime, endTime);
Granularity granularity = new SimpleGranularity(PredefinedGranularity.ALL);
DruidDimension dimension = new SimpleDimension("page");
TopNMetric metric = new SimpleMetric("count");
DruidTopNQuery query = DruidTopNQuery.builder()
.dataSource("wikipedia")
.dimension(dimension)
.threshold(10)
.topNMetric(metric)
.granularity(granularity)
.aggregators(Arrays.asList(new LongSumAggregator("count", "count")))
.intervals(Collections.singletonList(interval))
.build();
// 转为 JSON 发送
ObjectMapper mapper = new ObjectMapper();
String queryJson = mapper.writeValueAsString(query);
这样就能在 Java 应用中动态构建复杂查询,避免拼接 JSON 字符串的麻烦。
8. 总结
本文带你完成了 Druid 的入门之旅:
- 理解了事件数据与 Druid 的定位
- 搭建了本地 Docker 集群
- 实践了批处理数据摄入
- 掌握了原生查询与 SQL 两种查询方式
- 了解了 Java 客户端的使用
Druid 的能力远不止于此。在生产环境中,你还需要深入:
- ✅ 流式摄入(Kafka + Supervisor)
- ✅ 高级 TuningConfig 调优
- ✅ 集群容量规划与监控
- ✅ 安全与权限控制
建议从官方文档和真实业务场景出发,逐步探索 Druid 的更多可能性。