1. 简介
本文将带你了解 Apache Nutch 的核心功能和使用方法。Apache Nutch 是一个开箱即用的网络爬虫工具,能与 Apache 生态系统中的其他工具(如 Apache Hadoop 和 Apache Solr)无缝集成。
2. 安装配置 Nutch
使用 Nutch 前需先下载最新版本。访问 https://nutch.apache.org/download/ 获取二进制包(当前最新版为 1.20),解压到合适目录。
解压后需配置 User-Agent,编辑 conf/nutch-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>http.agent.name</name>
<value>MyNutchCrawler</value>
</property>
</configuration>
此配置使所有 HTTP 请求使用 MyNutchCrawler 作为 User-Agent。实际值应根据你的爬虫需求调整。
3. 爬取第一个网站
安装完成后即可开始爬取 URL。Nutch 的爬取过程分为多个阶段,提供高度灵活性。整个流程通过 bin/nutch 命令行工具控制。
3.1. 注入种子 URL
爬取前需先注入种子 URL。创建包含 URL 的文本文件,通过 inject 命令注入爬取数据库:
$ mkdir -p urls
$ echo https://www.baeldung.com > urls/seed.txt
$ bin/nutch inject crawl/crawldb urls
将 https://www.baeldung.com 注入到 crawl/crawldb 数据库(首次运行会自动创建)。验证数据库内容:
$ bin/nutch readdb crawl/crawldb -dump crawl/log
$ cat crawl/log/part-r-00000
https://www.baeldung.com/ Version: 7
Status: 1 (db_unfetched)
Fetch time: Sat May 18 09:31:09 BST 2024
Modified time: Thu Jan 01 01:00:00 GMT 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata:
✅ 确认数据库中有一个未抓取的 URL。
3.2. 生成爬取分段
下一步是生成爬取分段,使用 generate 命令:
$ bin/nutch generate crawl/crawldb crawl/segments
.....
2024-05-18 09:48:00,281 INFO o.a.n.c.Generator [main] Generator: Partitioning selected urls for politeness.
2024-05-18 09:48:01,288 INFO o.a.n.c.Generator [main] Generator: segment: crawl/segments/20240518100617
2024-05-18 09:48:02,645 INFO o.a.n.c.Generator [main] Generator: finished, elapsed: 3890 ms
生成了新分段 crawl/segments/20240518100617(名称为时间戳)。默认生成所有待抓取 URL 的分段数据。可通过 -topN 参数限制数量:
$ bin/nutch generate crawl/crawldb crawl/segments -topN 20
查看分段状态:
$ bin/nutch readseg -list crawl/segments/20240518100617
NAME GENERATED FETCHER START FETCHER END FETCHED PARSED
20240518100617 1 ? ? ? ?
⚠️ 显示有 1 个 URL 但尚未抓取。
3.3. 抓取与解析 URL
分段生成后即可抓取 URL,使用 fetch 命令:
$ bin/nutch fetch crawl/segments/20240518100617
启动多线程抓取器处理所有待抓取 URL。再次查看分段:
$ bin/nutch readseg -list crawl/segments/20240518100617
NAME GENERATED FETCHER START FETCHER END FETCHED PARSED
20240518100617 1 2024-05-18T10:11:16 2024-05-18T10:11:16 1 ?
✅ URL 已抓取但未解析。使用 parse 命令解析:
$ bin/nutch parse crawl/segments/20240518100617
解析完成后查看分段:
$ bin/nutch readseg -list crawl/segments/20240518100617
NAME GENERATED FETCHER START FETCHER END FETCHED PARSED
20240518100617 1 2024-05-18T10:11:16 2024-05-18T10:11:16 1 1
3.4. 更新爬取数据库
最后一步是更新爬取数据库。通过 updatedb 命令合并解析数据并注入新发现的 URL:
$ bin/nutch updatedb crawl/crawldb crawl/segments/20240518100617
查看数据库统计:
$ bin/nutch readdb crawl/crawldb -stats
2024-05-18 10:21:42,675 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics start: crawl/crawldb
2024-05-18 10:21:44,344 INFO o.a.n.c.CrawlDbReader [main] Statistics for CrawlDb: crawl/crawldb
2024-05-18 10:21:44,344 INFO o.a.n.c.CrawlDbReader [main] TOTAL urls: 59
.....
2024-05-18 10:21:44,352 INFO o.a.n.c.CrawlDbReader [main] status 1 (db_unfetched): 58
2024-05-18 10:21:44,352 INFO o.a.n.c.CrawlDbReader [main] status 2 (db_fetched): 1
2024-05-18 10:21:44,352 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics: done
数据库现在有 59 个 URL(1 个已抓取,58 个待抓取)。
3.5. 生成反向链接数据库
可额外维护反向链接数据库。使用 invertlinks 命令:
$ bin/nutch invertlinks crawl/linkdb crawl/segments/20240518100617
⚠️ 注意:此数据库仅包含跨域链接(不同域名间的链接)。
3.6. 再次爬取
发现 58 个新 URL 后可重复流程。重新生成分段并执行完整流程:
$ bin/nutch generate crawl/crawldb crawl/segments
$ bin/nutch fetch crawl/segments/20240518102556
$ bin/nutch parse crawl/segments/20240518102556
$ bin/nutch updatedb crawl/crawldb crawl/segments/20240518102556
$ bin/nutch invertlinks crawl/linkdb crawl/segments/20240518102556
本次抓取耗时更长(因 URL 数量增加)。查看最终统计:
$ bin/nutch readdb crawl/crawldb -stats
2024-05-18 10:33:15,671 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics start: crawl/crawldb
2024-05-18 10:33:17,344 INFO o.a.n.c.CrawlDbReader [main] Statistics for CrawlDb: crawl/crawldb
2024-05-18 10:33:17,344 INFO o.a.n.c.CrawlDbReader [main] TOTAL urls: 900
.....
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] status 1 (db_unfetched): 841
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] status 2 (db_fetched): 52
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] status 3 (db_gone): 1
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] status 4 (db_redir_temp): 1
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] status 5 (db_redir_perm): 5
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics: done
共 900 个 URL(52 个已抓取)。❌ 部分未处理因是图片/JSON 等非网页资源。
4. 限制域名
当前爬虫会跟踪所有 URL,可能导致爬取范围过大。例如数据库中包含:
www.baeldung.comcourses.baeldung.comgithub.comwww.linkedin.com
Nutch 提供内置过滤机制。编辑 conf/regex-urlfilter.txt,每行规则以 -(排除)或 +(包含)开头。默认末尾规则 +. 会包含所有 URL。
修改为仅允许目标域名:
- +.
+ +^https?://www\.baeldung\.com
⚠️ 规则仅对新爬取生效。清理数据后重新运行两轮:
$ bin/nutch readdb crawl/crawldb -stats
2024-05-18 17:57:34,921 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics start: crawl/crawldb
2024-05-18 17:57:36,595 INFO o.a.n.c.CrawlDbReader [main] Statistics for CrawlDb: crawl/crawldb
2024-05-18 17:57:36,596 INFO o.a.n.c.CrawlDbReader [main] TOTAL urls: 670
.....
2024-05-18 17:57:36,607 INFO o.a.n.c.CrawlDbReader [main] status 1 (db_unfetched): 613
2024-05-18 17:57:36,607 INFO o.a.n.c.CrawlDbReader [main] status 2 (db_fetched): 51
2024-05-18 17:57:36,607 INFO o.a.n.c.CrawlDbReader [main] status 4 (db_redir_temp): 1
2024-05-18 17:57:36,607 INFO o.a.n.c.CrawlDbReader [main] status 5 (db_redir_perm): 5
2024-05-18 17:57:36,607 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics: done
✅ URL 数量从 900 降至 670(过滤了 230 个外部链接)。
5. 使用 Solr 索引
爬取数据需通过搜索引擎查询,Nutch 原生支持 Apache Solr。首先启动 Solr 服务(参考 Solr 快速指南),创建集合:
# 在 Solr 安装目录执行
$ bin/solr create -c nutch
配置 Nutch 连接 Solr,编辑 conf/nutch-site.xml:
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.solr.store.SolrStore</value>
</property>
<property>
<name>solr.server.url</name>
<value>http://localhost:8983/solr/nutch</value>
</property>
使用 index 命令索引数据:
# 在 Nutch 安装目录执行
bin/nutch index crawl/crawldb/ -linkdb crawl/linkdb/ crawl/segments/20240518100617 -filter -normalize -deleteGone
2024-05-19 11:12:12,502 INFO o.a.n.i.s.SolrIndexWriter [pool-5-thread-1] Indexing 1/1 documents
2024-05-19 11:12:12,502 INFO o.a.n.i.s.SolrIndexWriter [pool-5-thread-1] Deleting 0 documents
2024-05-19 11:12:13,730 INFO o.a.n.i.IndexingJob [main] Indexer: number of documents indexed, deleted, or skipped:
2024-05-19 11:12:13,732 INFO o.a.n.i.IndexingJob [main] Indexer: 1 indexed (add/update)
2024-05-19 11:12:13,732 INFO o.a.n.i.IndexingJob [main] Indexer: finished, elapsed: 2716 ms
每次爬取后需对新分段执行索引。在 Solr 中查询索引数据:
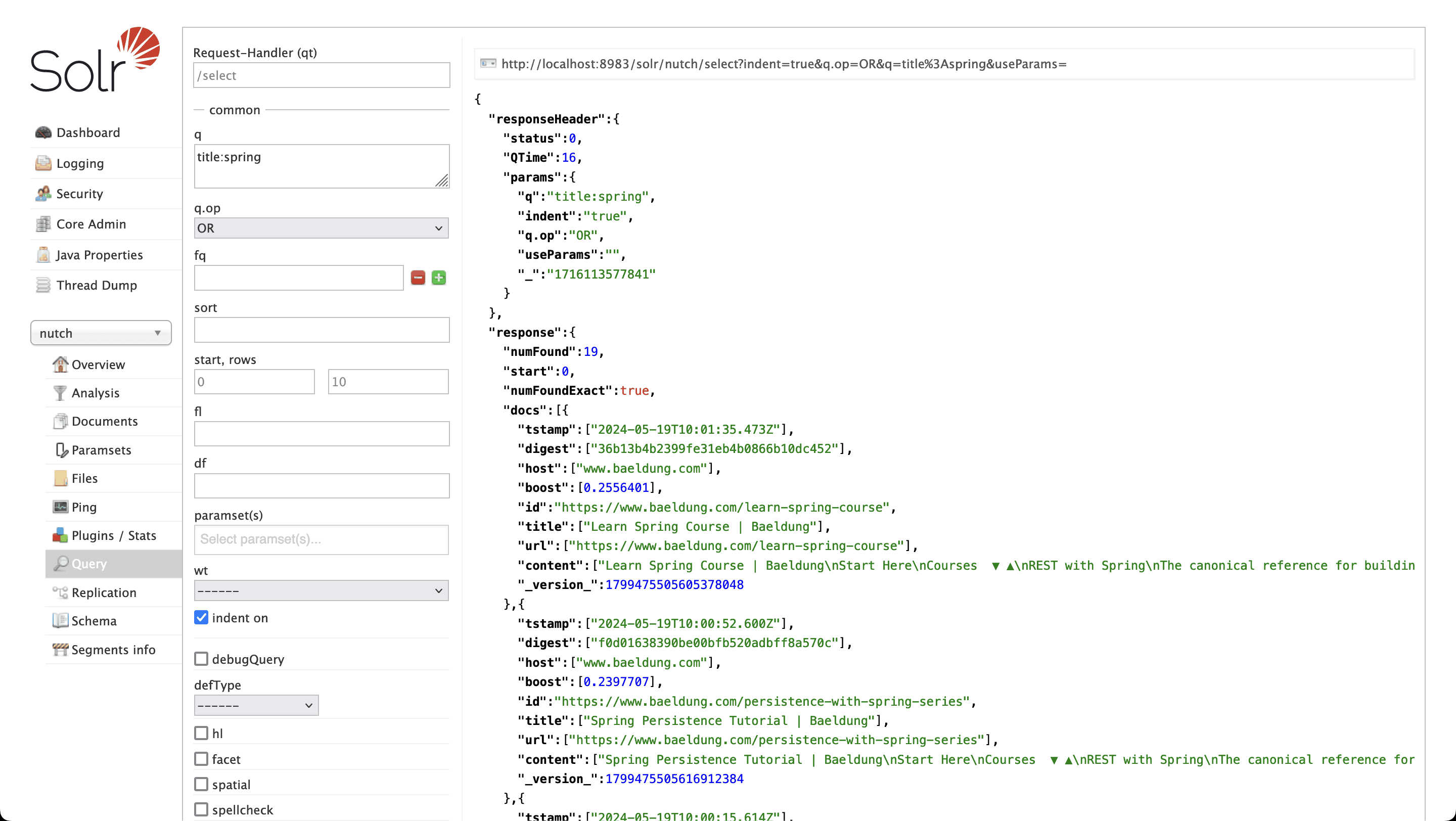
✅ 搜索标题含 "Spring" 的页面返回 19 个结果。
6. 自动化爬取流程
手动执行多步骤较繁琐,**Nutch 提供自动化脚本 bin/crawl**。可自动完成所有步骤,包括:
- 注入种子 URL
- 多轮爬取
- 索引到 Solr
示例:执行两轮爬取并索引:
$ ./bin/crawl -i -s urls crawl 2
参数说明:
-i:索引到配置的搜索引擎-s urls:种子 URL 目录crawl:爬取数据存储目录2:爬取轮数
在配置好 nutch-site.xml 和 regex-urlfilter.txt 的干净环境中运行,结果与手动执行完全一致。
7. 总结
本文介绍了 Nutch 的基础用法:安装配置、网站爬取、Solr 索引及流程自动化。但这仅是 Nutch 功能的冰山一角,建议进一步探索其高级特性。