1. 引言
Apache Spark 是一个开源的集群计算框架。它为 Scala、Java、Python 和 R 提供了优雅的开发 API,让开发者能够在 HDFS、Cassandra、HBase、S3 等多种数据源上执行各类数据密集型任务。
历史上,Hadoop 的 MapReduce 在某些迭代式和交互式计算任务中效率低下,这直接催生了 Spark 的诞生。使用 Spark,在内存中运行逻辑可比 Hadoop 快两个数量级,在磁盘上也能快一个数量级——简单粗暴地说,就是性能碾压。
2. Spark 架构
Spark 应用在集群上以独立进程集合运行,如下图所示:
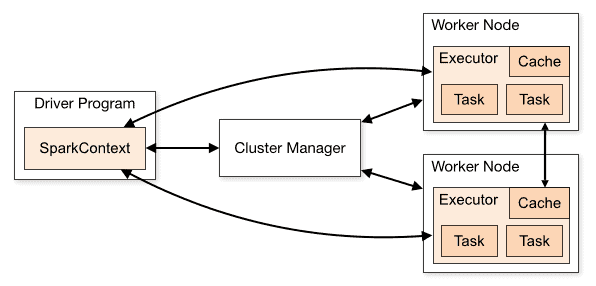
这些进程由主程序(称为驱动程序)中的 SparkContext 对象协调。SparkContext 连接到多种集群管理器(如 Spark 独立集群管理器、Mesos 或 YARN),由它们跨应用分配资源。
连接建立后,Spark 会在集群节点上获取执行器(Executor),这些进程负责运行计算并存储应用数据。接着,Spark 将应用代码(通过传递给 SparkContext 的 JAR 或 Python 文件定义)发送到执行器。最后,SparkContext 向执行器发送任务执行。
3. 核心组件
下图清晰展示了 Spark 的不同组件:
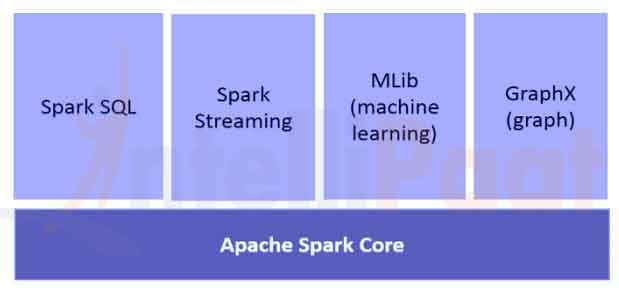
3.1. Spark Core
Spark Core 组件负责所有基础 I/O 功能、集群任务调度与监控、任务分发、与存储系统的网络通信、容错恢复以及高效的内存管理。
与 Hadoop 不同,Spark 通过一种称为 RDD(弹性分布式数据集)的特殊数据结构,避免将共享数据存储在 Amazon S3 或 HDFS 等中间存储中。
弹性分布式数据集(RDD)是不可变的、分区的记录集合,支持并行操作和容错的内存计算。
RDD 支持两种操作:
- 转换(Transformation):从现有 RDD 生成新 RDD 的函数。转换器以 RDD 为输入,输出一个或多个 RDD。转换具有惰性特性,即只有在调用动作(Action)时才会执行
- 动作(Action):转换操作创建 RDD,但当我们需要处理实际数据集时,就会执行动作。因此,动作是返回非 RDD 值的 Spark RDD 操作。动作结果会存储到驱动程序或外部存储系统
动作是将数据从执行器发送回驱动程序的方式之一。执行器是负责执行任务的代理,而驱动程序则是协调工作节点和任务执行的 JVM 进程。常见的 Spark 动作包括 count() 和 collect()。
3.2. Spark SQL
Spark SQL 是用于结构化数据处理的 Spark 模块,主要用于执行 SQL 查询。DataFrame 是 Spark SQL 的核心抽象——在 Spark 中,DataFrame 是按命名列组织的分布式数据集合。
Spark SQL 支持从 Hive、Avro、Parquet、ORC、JSON 和 JDBC 等多种数据源获取数据。借助 Spark 引擎,它还能扩展到数千节点和多小时查询,并提供完整的查询中容错能力。
3.3. Spark Streaming
Spark Streaming 是核心 Spark API 的扩展,支持对实时数据流进行可扩展、高吞吐量、容错的流处理。数据可从 Kafka、Flume、Kinesis 或 TCP 套接字等多种源接入。
处理后的数据可推送到文件系统、数据库和实时仪表板。
3.4. Spark MLlib
MLlib 是 Spark 的机器学习(ML)库,旨在使实用机器学习可扩展且易用。它提供以下高层工具:
- 机器学习算法:分类、回归、聚类和协同过滤等常见学习算法
- 特征工程:特征提取、转换、降维和选择
- 管道工具:构建、评估和调优 ML 管道的工具
- 持久化:保存和加载算法、模型和管道
- 实用工具:线性代数、统计、数据处理等
3.5. Spark GraphX
GraphX 是用于图和图并行计算的组件。高层来看,GraphX 通过引入新的图抽象扩展了 Spark RDD:一种附加了顶点和边属性的有向多重图。
为支持图计算,GraphX 暴露了一组基础操作符(如 subgraph、joinVertices 和 aggregateMessages)。此外,GraphX 还包含不断增长的图算法和构建器集合,以简化图分析任务。
4. Spark "Hello World" 示例
理解核心组件后,我们来实现一个简单的基于 Maven 的 Spark 项目——词频统计。我们将以本地模式运行 Spark,所有组件(主节点、执行节点或独立集群管理器)都在同一台机器上运行。
4.1. Maven 配置
在 pom.xml 中添加 Spark 相关依赖:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
⚠️ 注意:版本需与 Spark 安装版本匹配,否则可能踩坑。
4.2. 词频统计——Spark 任务
编写 Spark 任务处理文本文件,输出单词及其出现次数:
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = ctx.textFile(args[0], 1);
JavaRDD<String> words
= lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
JavaPairRDD<String, Integer> ones
= words.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> counts
= ones.reduceByKey((Integer i1, Integer i2) -> i1 + i2);
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?, ?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
}
核心步骤解析:
- 将本地文本文件路径作为参数传递给 Spark 任务
- SparkContext 是 Spark 的主入口点,通过 SparkConf 描述应用配置
- 使用
textFile将文本文件读取为 JavaRDD - 通过
flatMap将每行拆分为单词并扁平化 - 用
mapToPair将每个单词映射为 (单词, 1) 的元组 - 通过
reduceByKey聚合相同单词的计数 - 最后执行
collect动作获取结果并打印
4.3. 执行 Spark 任务
用 Maven 构建项目,在 target 目录生成 apache-spark-1.0-SNAPSHOT.jar。提交词频统计任务:
${spark-install-dir}/bin/spark-submit --class com.baeldung.WordCount
--master local ${WordCount-MavenProject}/target/apache-spark-1.0-SNAPSHOT.jar
${WordCount-MavenProject}/src/main/resources/spark_example.txt
✅ 替换路径:
${spark-install-dir}:Spark 安装目录${WordCount-MavenProject}:Maven 项目目录
提交后后台执行流程:
- 驱动程序中的 SparkContext 连接到集群管理器(本地独立模式)
- 集群管理器分配资源
- Spark 在集群节点上获取执行器进程
- 应用代码(JAR 文件)发送到执行器
- SparkContext 向执行器发送任务
最终结果返回驱动程序,输出词频统计:
Hello 1
from 2
Baeldung 2 # 原文中的 Baledung 应为 Baeldung
Keep 1
Learning 1
Spark 1
Bye 1
5. 总结
本文介绍了 Apache Spark 的架构和核心组件,并通过词频统计示例演示了 Spark 任务的开发与执行。Spark 的高性能和统一数据处理能力使其成为大数据领域的利器。
完整源码可在 GitHub 获取,如有问题可联系 spark-dev@example.com。