1. 概述
Apache Cassandra 是一款开源的 NoSQL 分布式数据库,以高可用性和可扩展性著称。为实现高可用,Cassandra 通过跨集群复制数据来保障服务连续性。本文将深入探讨 Cassandra 如何在数据复制过程中提供一致性控制机制。
2. 数据复制
数据复制指将每行数据存储在多个节点中,核心目的是提升可靠性和容错能力。当任意节点故障时,复制策略能确保数据在其他节点依然可用。
复制因子(RF) 决定了集群中存储副本的节点数量。Cassandra 提供两种复制策略:
- SimpleStrategy:适用于单数据中心单机架拓扑。Cassandra 先通过分区器确定目标节点,再按顺时针方向在环中其他节点放置副本。
- NetworkTopologyStrategy:适用于多数据中心多机架场景。可为每个数据中心设置不同的复制因子,并在数据中心内跨机架分配副本以最大化可用性。
3. 一致性级别
一致性反映数据副本的同步程度。在分布式系统中实现数据一致性极具挑战性。Cassandra 优先保障可用性而非强一致性,允许根据业务场景灵活调整一致性级别,多数场景采用最终一致性模型。
下面分析读写操作中一致性级别的影响:
4. 写操作的一致性级别(CL)
写操作的一致性级别规定:协调节点需收到多少副本节点的确认响应,才能向客户端返回成功。需注意:确认节点数(由CL决定)与存储副本的节点数(由RF决定)通常不同。
例如:当 CL=ONE 且 RF=3 时,只需一个副本节点确认写成功,但 Cassandra 会在后台异步将数据复制到其他两个节点。
常用写一致性级别:
- ONE:仅需一个副本节点确认,写操作速度最快。
- QUORUM:需超过半数(51%)的副本节点确认(跨所有数据中心)。
- LOCAL_QUORUM:仅需协调节点所在数据中心的超过半数副本确认,避免跨数据中心通信延迟。
- ALL:需所有副本节点确认。写操作最慢,且任一副本节点故障都会导致失败,生产环境慎用。
一致性级别可在单次查询或全局配置,下图展示了写操作中 CL 的示例:
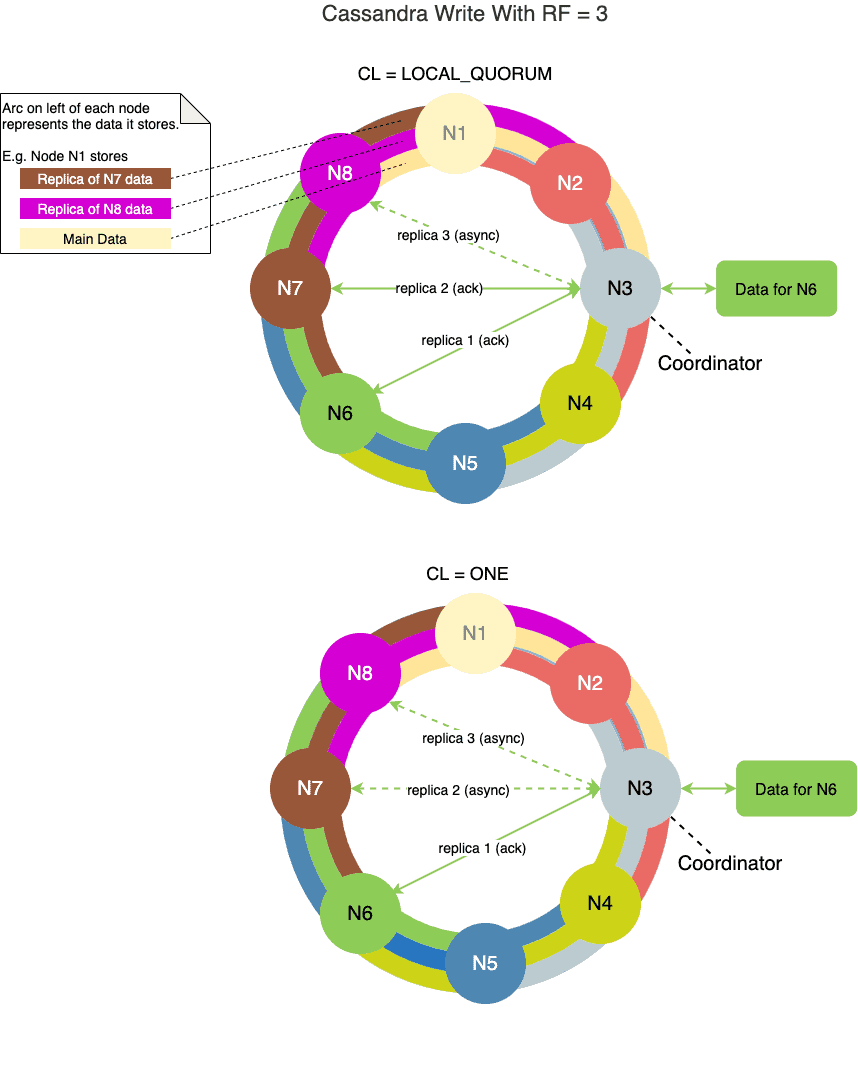
5. 读操作的一致性级别(CL)
读操作的一致性级别规定:协调节点需收到多少副本节点的最新一致数据响应,才能向客户端返回结果。
常用读一致性级别:
- ONE:仅需一个副本节点返回数据,读取速度最快。
- QUORUM:需超过半数的副本节点响应(跨所有数据中心),跨数据中心通信会导致延迟增加。
- LOCAL_QUORUM:仅需协调节点所在数据中心的超过半数副本响应,避免跨数据中心延迟。
- ALL:需所有副本节点响应。读操作最慢,任一副本节点故障都会导致失败,生产环境慎用。
下图展示了读操作中 CL 的示例:
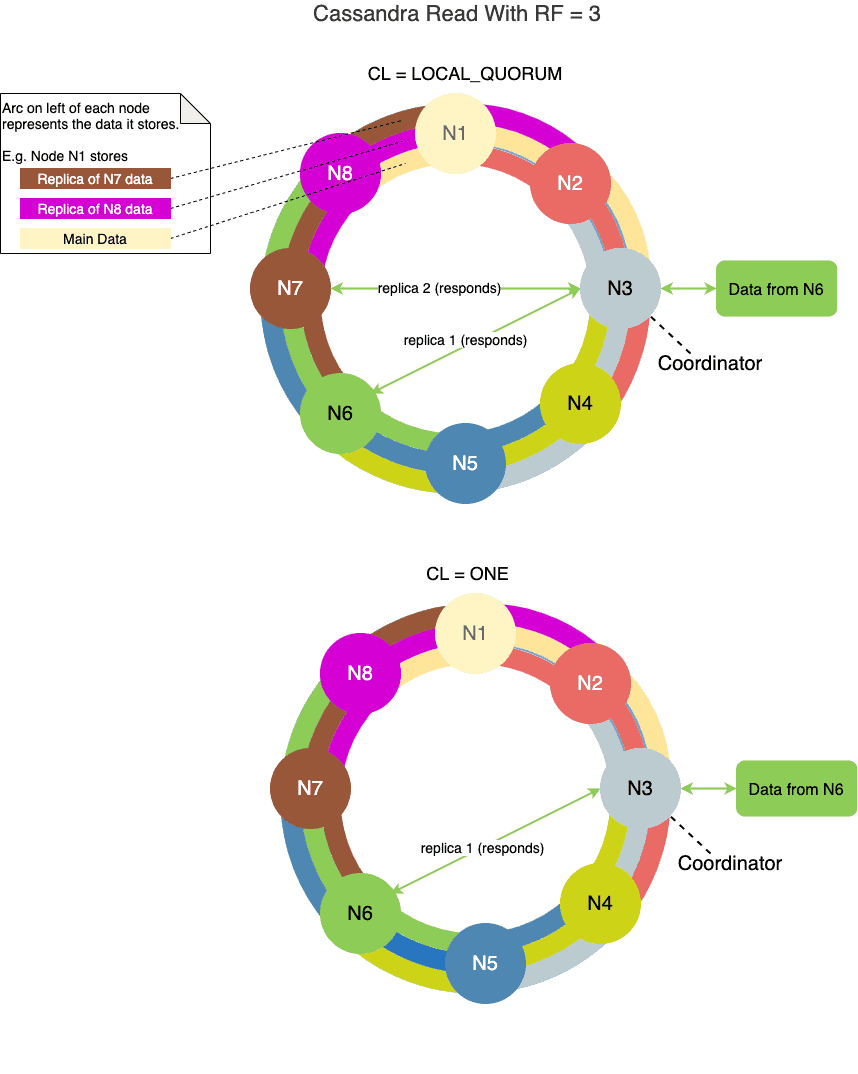
6. 强一致性
强一致性保证无论写入与读取间隔多久,读取的数据总是最新写入的数据。强一致性需满足公式:W + R > RF,其中:
W:写操作一致性级别要求的副本确认数R:读操作一致性级别要求的副本响应数RF:复制因子
6.1. 写 CL = QUORUM 且读 CL = QUORUM
当 RF=3,W=QUORUM(或 LOCAL_QUORUM),R=QUORUM(或 LOCAL_QUORUM)时:W(2) + R(2) > RF(3)
写操作确保两个副本拥有最新数据,读操作需至少两个副本返回一致数据才成功。
6.2. 写 CL = ALL 且读 CL = ONE
当 RF=3,W=ALL,R=ONE 时:W(3) + R(1) > RF(3)
写操作需所有副本确认成功,读操作只需任一副本响应即可保证读到最新数据。
⚠️ 踩坑提示:CL=ALL 的写操作容错性差,会降低系统可用性,生产环境需谨慎使用。
7. 总结
本文系统分析了 Cassandra 的数据复制机制,深入探讨了读写操作中不同一致性级别的特性与适用场景,并通过具体案例展示了实现强一致性的方法。掌握这些核心概念,有助于在实际项目中平衡 Cassandra 的高可用性与数据一致性需求。