2. Log-Structured Merge-Tree (LSMT)
Apache Cassandra 采用双层 Log-Structured Merge-Tree (LSMT) 数据结构作为存储核心。这种结构包含两个树形组件:
- **内存组件 (C0)**:基于内存的缓存
- **磁盘组件 (C1)**:持久化存储
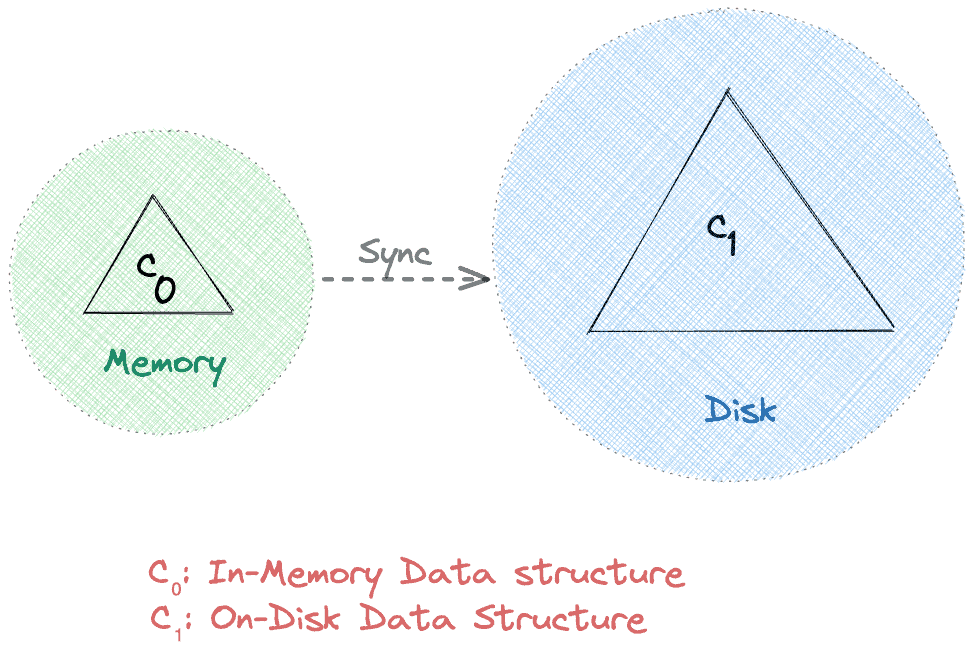
核心设计理念:
- 所有请求优先访问内存组件 C0
- 通过同步操作定期将数据从 C0 刷写到磁盘 C1
- 显著减少 I/O 操作,高效利用网络带宽
后续我们将深入探讨 C0 和 C1 的具体实现,即 Cassandra 中熟知的 MemTable 和 SSTable。
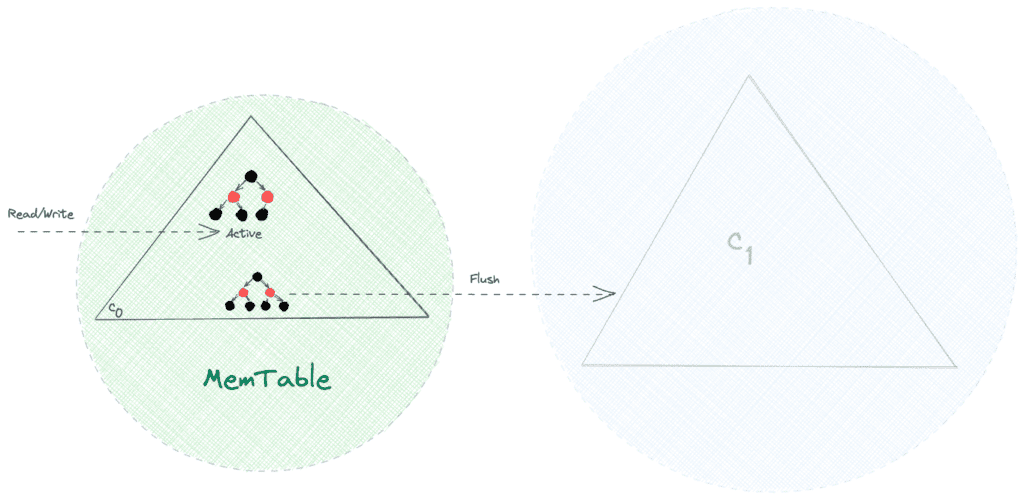
3. MemTable
MemTable 是内存驻留数据结构,通常采用具备自平衡特性的红黑树 (Red-black tree) 实现。其操作复杂度均为 O(log n):
- 搜索 (search)
- 插入 (insert)
- 更新 (update)
- 删除 (delete)
关键特性:
- 作为可变内存结构,所有写操作顺序执行
- 实现高速写入性能
- 受限于内存容量和易失性,需定期持久化
当 MemTable 大小达到阈值时:
- 所有读写请求切换到新 MemTable
- 旧 MemTable 刷写到磁盘后丢弃
踩坑点:若节点在刷写前崩溃,未持久化数据将丢失。Cassandra 通过 Commit Log 机制解决此问题(下节详述)。
4. Commit Log
为解决数据持久化问题,Cassandra 引入 Commit Log(预写日志) 机制:
- 所有写操作立即追加到磁盘上的只追加文件
- MemTable 充当写回缓存 (write-back cache)
- 仅在崩溃恢复时读取 Commit Log
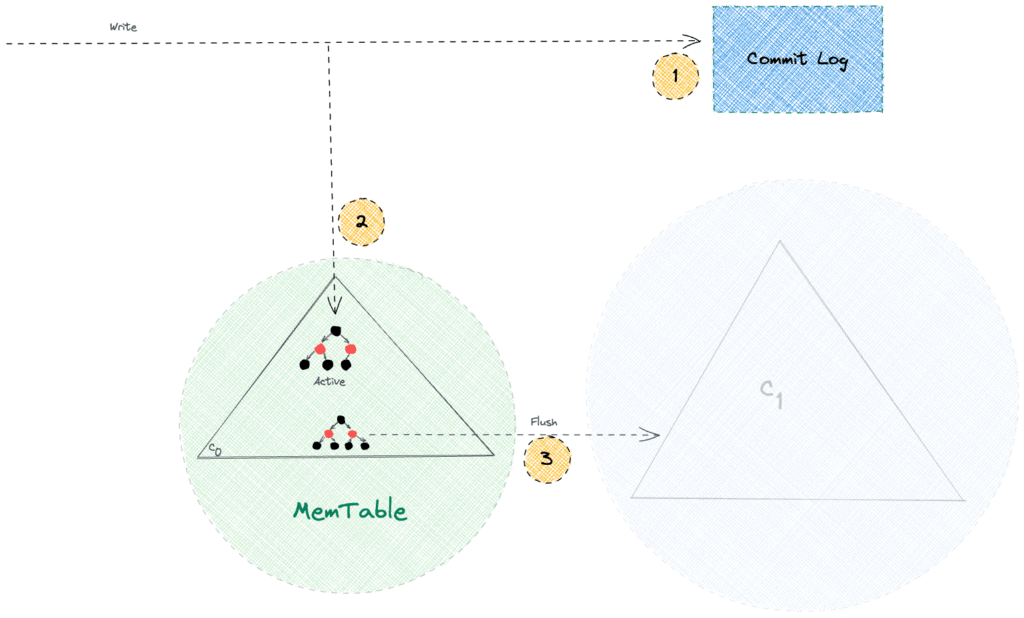
核心优势:
- 追加操作避免磁盘随机寻址,保证高性能
- 提供强数据持久性保证
- 常规读请求完全不访问 Commit Log
5. SSTable
SSTable (Sorted String Table) 是 LSMT 树的磁盘组件,其名称源于 Google BigTable 的类似设计:
- 每个 MemTable 刷写生成新的不可变分段
- 数据按键排序存储
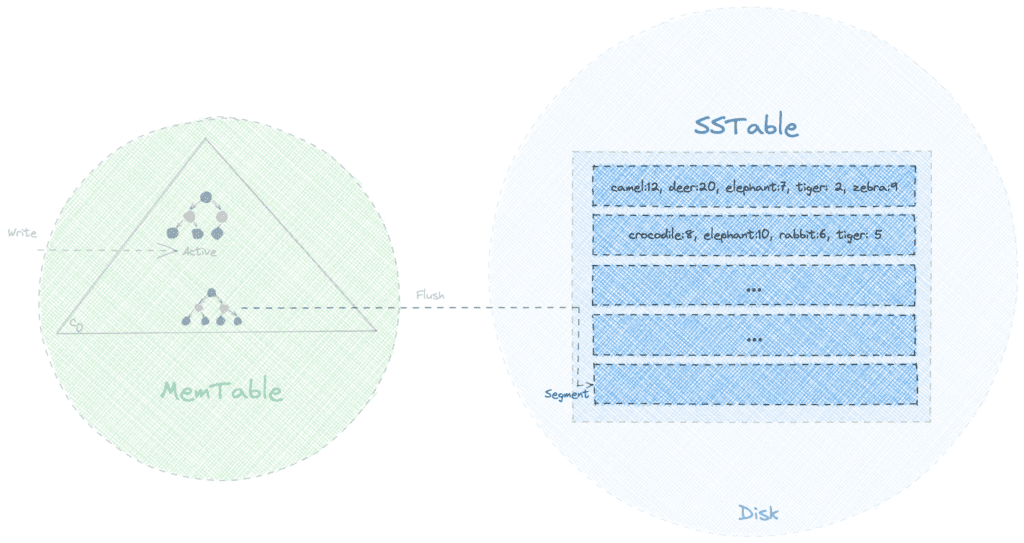
读取挑战:
- 同一键可能存在于多个分段
- 需从最新分段开始扫描,找到即返回
- 最坏时间复杂度 O(N)(N 为分段数)
优化方向:
- 减少需扫描的分段数量(稀疏索引)
- 快速判断键是否存在(布隆过滤器)
- 合并分段消除冗余(压缩)
6. Sparse Index
Cassandra 通过稀疏索引 (Sparse Index) 优化读取性能:
- 存储每个分段的首键及其磁盘偏移量
- 使用 B-Tree 结构维护索引(O(log K) 查找复杂度)
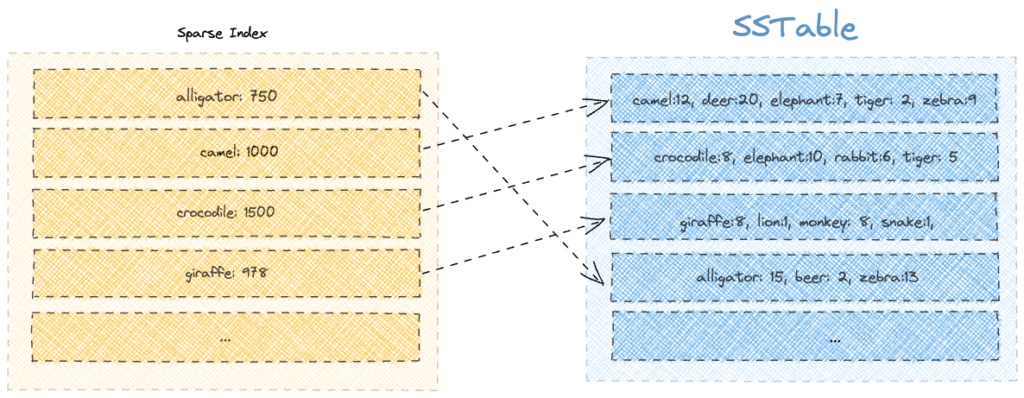
查询流程(以查找 "beer" 为例):
- 在稀疏索引中定位不大于 "beer" 的最大键
- 获取对应分段偏移量(如 "alligator" 所在分段)
- 仅扫描该分段查找目标键
局限性:
- 不存在的键(如 "kangaroo")仍需全分段扫描
- 重复键更新导致索引膨胀
7. Bloom Filter
布隆过滤器 (Bloom Filter) 作为概率性数据结构,进一步优化读取:
- 为每个 SSTable 分段附加独立过滤器
- 先执行键存在性检查,避免无效扫描
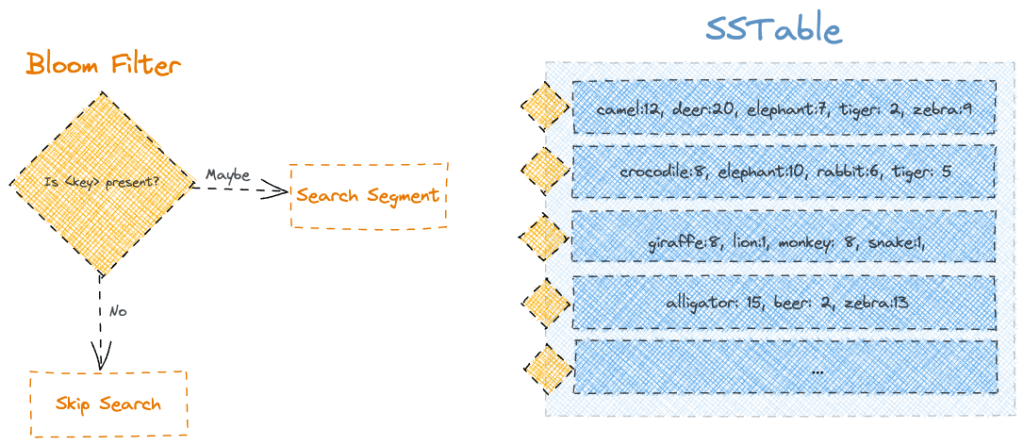
工作特性:
- 响应 "No" ⇒ 键绝对不存在
- 响应 "Maybe" ⇒ 需进一步扫描
- 可通过增大存储空间提升准确率
实际效果:显著减少不存在键的磁盘 I/O,尤其适合稀疏数据场景。
8. Compaction
随着时间推移,分段数量增长导致读取性能下降。Cassandra 通过压缩 (Compaction) 机制解决:
- 后台合并小分段为大分段
- 仅保留每个键的最新版本
- 同时实现读取加速和存储优化
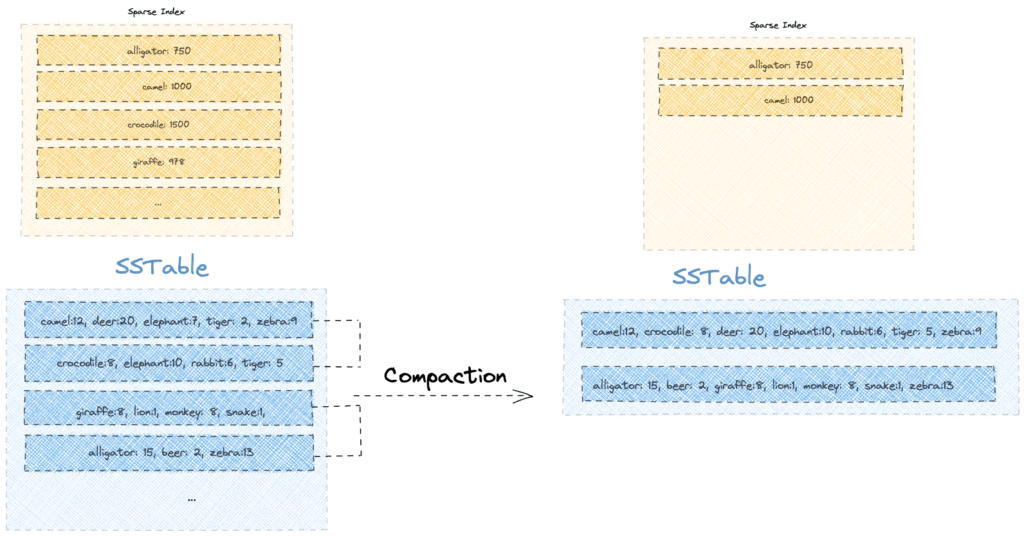
核心收益:
- 空间回收:清除旧版本数据(如 "elephant" 的历史记录)
- 删除生效:墓碑标记 (tombstone) 在压缩时真正删除数据
- 索引简化:减少分段数量和索引条目
简单粗暴的结论:压缩是维持 Cassandra 长期性能的关键后台操作。
9. 总结
本文深入剖析了 Apache Cassandra 存储引擎的核心组件:
- LSMT 树架构:内存 MemTable + 磁盘 SSTable
- 写入优化:Commit Log 保证持久性
- 读取优化:稀疏索引 + 布隆过滤器
- 长期维护:压缩机制平衡性能与存储
这些设计使 Cassandra 在写密集型场景下仍能保持卓越的读取性能,堪称分布式存储工程的典范实现。