1. 简介
数据结构是计算机科学的两大支柱之一,用于定义数据的组织、管理和存储方式,以便实现高效的数据访问与修改。根据数据的存储、访问和使用方式,有多种不同的数据结构可供选择。
本文将介绍一些常见的高级数据结构,帮助读者在实际开发中更好地选择和使用。
2. 线性数据结构
当一个数据结构中的元素形成线性序列时,我们称其为线性数据结构。下面我们将讨论几种典型的线性结构。
2.1. 自组织链表(Self-Organizing List)
自组织链表是一种可以根据访问频率动态调整元素顺序的链表结构,以提升平均访问效率。与普通链表相比,它多了一个重新排序的能力。
普通链表查找元素时,最坏情况下需要遍历全部 n 个节点。而自组织链表通过将频繁访问的节点移动到前面,减少后续访问的比较次数。
常见重排策略
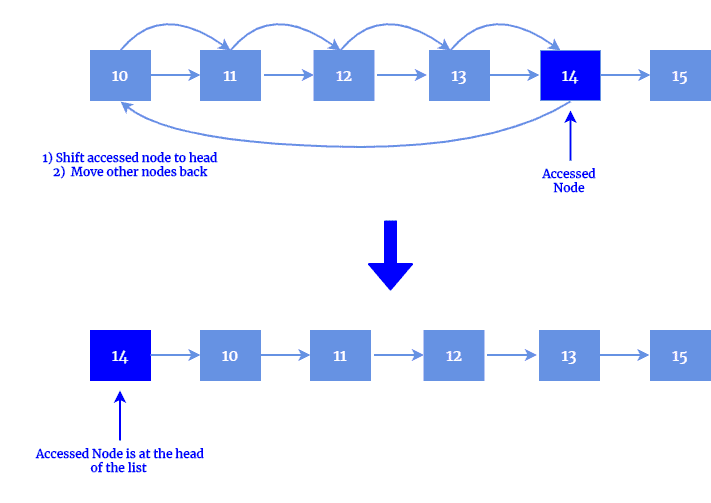
Move to Front(移动到前端)
- 每次访问到某个节点后,将其移动到链表头部。
- ✅优点:实现简单。
- ❌缺点:可能将偶发访问的节点错误地提升优先级。
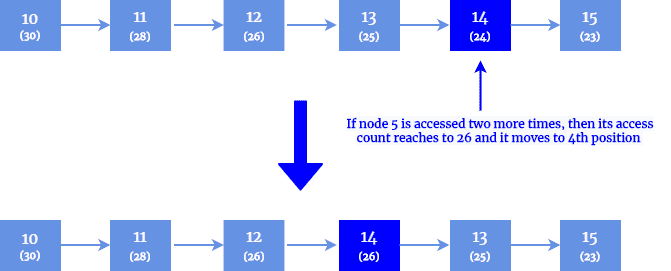
Count Method(计数法)
- 每个节点记录被访问的次数。
- 节点按访问次数从高到低排序。
- ✅优点:更合理地反映真实访问频率。
示例图示
2.2. 循环缓冲区(Circular Buffer)
循环缓冲区又称环形缓冲区,是一种使用固定大小的缓冲区,首尾相连形成环状结构的数据结构。
特点
- ✅不需频繁移动数据。
- ✅适合实现固定大小的队列(FIFO)。
- ❌扩容代价高(需要重新分配内存)。
示例图示
初始状态(容量为5):
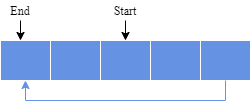
写入1、2、3后:
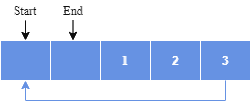
删除两个元素后:
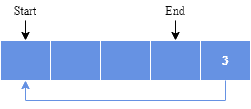
缓冲区满后继续写入会覆盖旧数据:
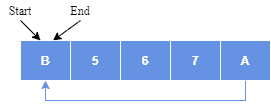
2.3. 空隙缓冲区(Gap Buffer)
空隙缓冲区是一种专为文本编辑器设计的数据结构,用于高效地处理在光标附近频繁插入和删除操作。
工作原理
- 文本分为两段,中间留出“空隙”用于插入新内容。
- 移动光标时,将文本从空隙一侧复制到另一侧。
示例
初始状态:
The quick [ ] over the dog
插入内容后:
The quick brown fox jumps [ ] over the dog
光标移动并插入新词:
The quick brown fox jumps over the lazy [] dog
✅优点:
- 插入/删除操作快。
- 搜索和显示效率高。
❌缺点:
- 多点操作效率低。
- 大文件下复制代价高。
2.4. 哈希数组树(Hashed Array Tree)
哈希数组树(HAT)是一种由多个小数组组成的数组结构,旨在减少动态扩容时的拷贝开销。
结构特点
- 顶层目录是一个大小为 m 的数组。
- 每个元素指向一个大小为 m 的子数组。
- 总容量为 m²。
示例图示
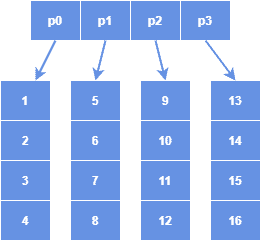
顶层目录大小为4,最多可存储 4×4=16 个元素。
✅优点:
- 扩容成本低。
- 支持高效随机访问。
❌缺点:
- 实现稍复杂。
- 不适合频繁插入/删除场景。
3. 非线性数据结构
非线性数据结构中的元素不是按顺序排列的,而是以树、图等形式组织的结构。这类结构更适合处理层级、关系等复杂数据。
3.1. 绳子结构(Rope)
Rope 是一种由多个字符串节点组成的二叉树结构,特别适合处理大文本的插入、删除和拼接操作。
结构特点
- 每个叶子节点保存一个字符串片段及其长度。
- 非叶子节点保存左子树总长度(weight)。
- 通过 weight 快速定位子串位置。
示例图示
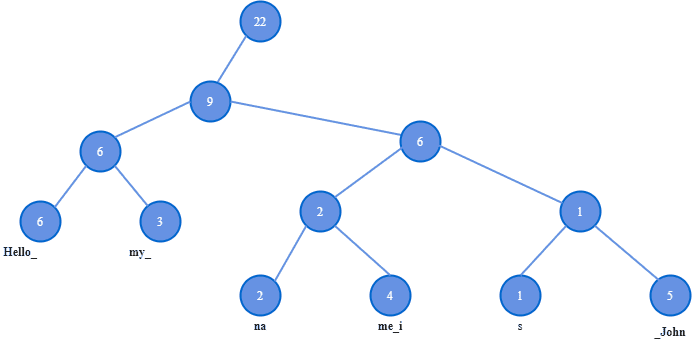
节点 weight 为9,表示其左子树总长度为9("Hello_" 6 + "my_" 3)。
✅优点:
- 对大文本操作高效。
- 支持并发修改。
❌缺点:
- 实现复杂。
- 内存占用较高。
3.2. 伸展树(Splay Tree)
伸展树是一种自调整的二叉查找树,具有“最近访问过的节点下次访问更快”的特性。
操作机制
- 所有操作(查找、插入、删除)都以“伸展”操作为基础。
- 通过旋转操作将目标节点提升到树根。
示例图示
搜索节点20后,它被旋转到根节点:
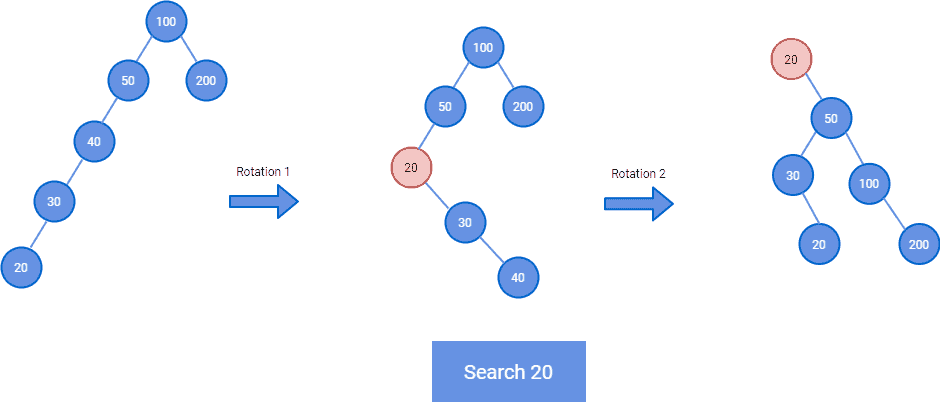
✅优点:
- 平均性能优于普通平衡树。
- 无需额外存储平衡信息。
❌缺点:
- 最坏情况下退化为链表。
3.3. 二叉堆(Binary Heap)
二叉堆是一种完全二叉树结构,常用于实现优先队列。
两个核心约束
- 完全二叉树结构(除最后一层外,其他层必须满)
- 堆序约束:
- 最大堆(Max Heap):父节点值 ≥ 子节点值
- 最小堆(Min Heap):父节点值 ≤ 子节点值
示例图示

✅优点:
- 构建和操作效率高。
- 实现简单。
❌缺点:
- 不支持高效查找任意元素。
4. 总结
本文介绍了多种高级数据结构,包括:
✅线性结构:
- 自组织链表:提升频繁访问效率
- 循环缓冲区:适合固定大小队列
- 空隙缓冲区:适合文本编辑
- 哈希数组树:减少扩容拷贝
✅非线性结构:
- Rope:高效处理大文本
- 伸展树:自动优化访问路径
- 二叉堆:实现优先队列
选择合适的数据结构是提升程序性能的关键。希望本文能帮助你在设计系统或解决性能问题时做出更明智的选择。