1. 概述
信息论是当前数据存储与分析领域的重要理论基础,尤其在数据压缩方面提供了强有力的支撑。虽然存在一些纯统计方法,但机器学习提供的神经网络结构更加灵活,能够为多种应用场景实现数据压缩。
在本教程中,我们将围绕自动编码器(Autoencoder)展开讲解,涵盖其功能、结构、超参数、训练方式及其常见应用类型。
2. 功能
压缩数据的方式多种多样,例如主成分分析(PCA)是一种经典的统计方法,能够提取数据中方差贡献最大的特征,从而实现降维压缩。这种技术属于“降维”范畴。但PCA只能提取线性无关的特征。
而自动编码器作为机器学习的一种神经网络结构,可以学习到更复杂的非线性编码特征。这些特征之间可以存在相关性,因此不一定是正交的。通过这种方式,可以在一个“潜在空间”中表示复杂数据。
以图像识别为例,当我们使用卷积神经网络(CNN)进行人脸识别时,可以将其构造成自动编码器结构。通过编码压缩图像,在略微降低图像质量的前提下节省存储空间。输出图像与输入图像之间的质量差异称为“重建损失(Reconstruction Loss)”。
自动编码器的主要目标是:在尽可能小的编码长度下,实现低甚至无重建损失的数据压缩。为此,自动编码器需要从数据中学习一个能够将数据实例映射为有意义编码的函数。我们可以将其理解为数据在低维空间中的重新映射。同时,这个编码还需要能够被解码器还原。
3. 通用结构
为了更好地理解自动编码器的工作机制,我们可以将其拆解为三个主要组成部分:编码器(Encoder)、瓶颈层(Bottleneck)、解码器(Decoder)。数据流经这三个部分的顺序如下图所示:
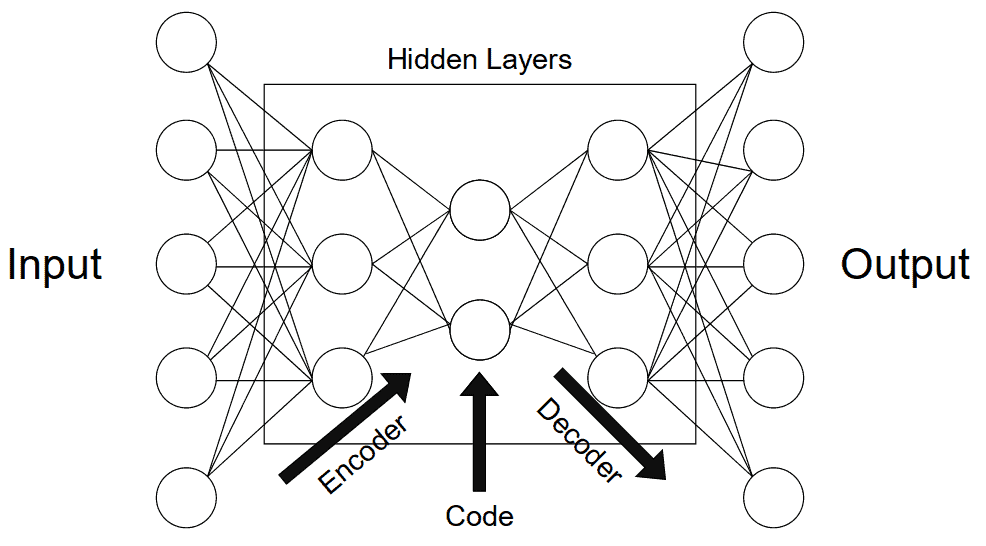
3.1 编码器
编码器的作用是将输入数据压缩为一个低维编码。在神经网络中,通常通过一系列池化层来实现维度的逐步降低。这样做可以起到去噪作用,只保留对编码有意义的部分。
网络中维度最少的那层被称为瓶颈层(Bottleneck),通常位于整个网络的中间位置。如果我们希望保留更多信息,就需要设置一个更大的编码维度。这个“编码大小”是一个关键超参数,它决定了编码器能保留多少信息,同时也影响模型的泛化能力。编码维度太大可能引入噪声,太小则可能无法准确表示原始数据。
3.2 解码器
解码器的作用是将编码还原为原始数据格式,可以理解为“解压缩”或“信息重建”工具。在图像任务中,比如图像分割,解码器可以根据编码还原图像内容,并识别出目标对象。
✅ 一些生成模型(如变分自动编码器 VAE)甚至可以通过解码器生成新的、不存在的数据。这在数据增强(Data Augmentation)场景中非常有用。
4. 常见类型
自动编码器在机器学习和计算机视觉中应用广泛,根据其设计目的和结构特点,主要分为以下几类:
4.1 去噪自动编码器(Denoising Autoencoder)
这类自动编码器专门用于从带有噪声的数据中提取干净的特征。训练时会在输入中加入噪声,迫使模型学会忽略这些噪声并还原原始数据。输出图像应比输入图像更“干净”。
✅ 应用场景:特征提取、图像去噪
⚠️ 示例:使用MNIST数据集训练去噪自动编码器效果如下:

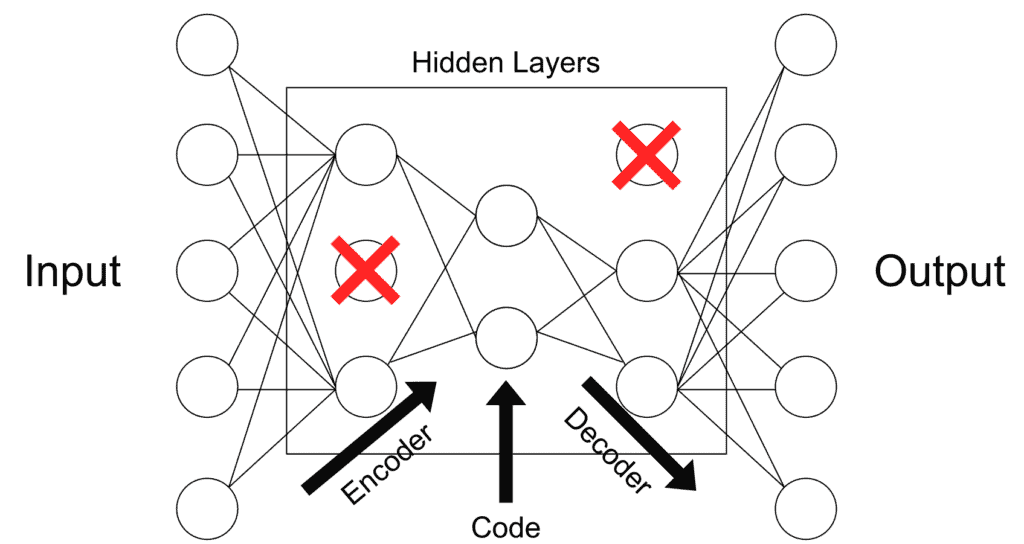
4.2 稀疏自动编码器(Sparse Autoencoder)
该类型通过在损失函数中加入“稀疏惩罚项”来限制隐藏层节点的激活程度,从而防止过拟合。也可以理解为一种正则化手段。
✅ 应用场景:通用正则化、特征选择
⚠️ 示例结构如下:
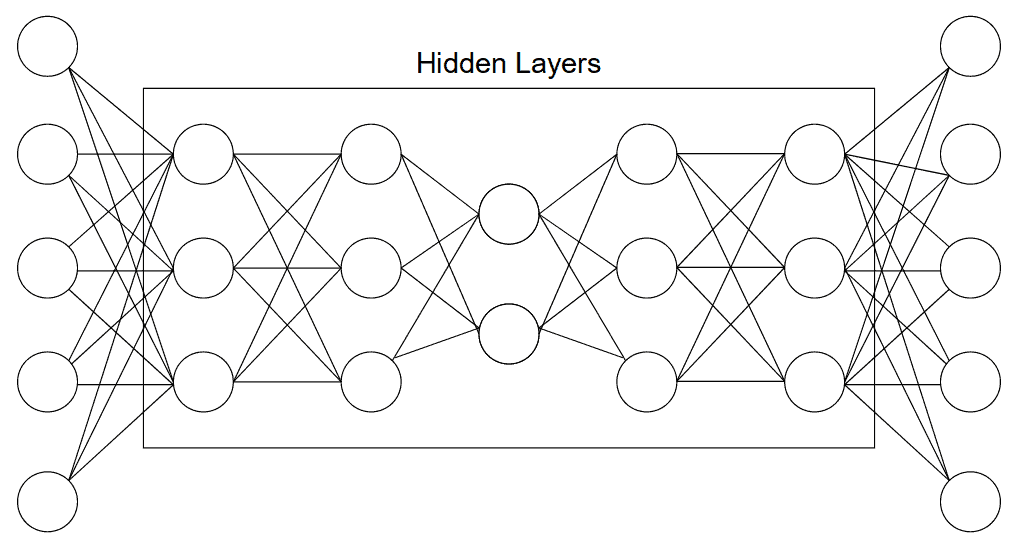
4.3 深度自动编码器(Deep Autoencoder)
由两个对称的深度信念网络(Deep Belief Network)组成,结构上类似于前面提到的通用自动编码器。编码器和解码器分别由多个隐藏层构成。
✅ 应用场景:特征提取、数据压缩、降维
⚠️ 结构示意图如下:
4.4 收缩自动编码器(Contractive Autoencoder)
这类自动编码器通过惩罚输入微小变化引起的编码剧烈波动,使得相近输入对应相近编码。这有助于模型学习到更具泛化能力的特征。
✅ 应用场景:数据增强、鲁棒特征学习
4.5 欠完备自动编码器(Undercomplete Autoencoder)
该类型在隐藏层中使用的维度小于输入维度,迫使模型专注于提取最重要的特征。通常不需要额外正则化。
✅ 应用场景:特征提取
⚠️ 典型结构如下图所示:
4.6 卷积自动编码器(Convolutional Autoencoder)
这类自动编码器使用卷积层进行编码与解码,特别适合图像数据。其中最经典的结构是U-Net,用于图像分割任务。
✅ 应用场景:图像分割、模式识别
⚠️ U-Net结构如下:

4.7 变分自动编码器(Variational Autoencoder, VAE)
VAE 将编码空间建模为概率分布,而非单一的点。这种设计使得潜在空间更加规则,便于生成新数据。因此,VAE 被归类为生成模型(Generative Model)。
训练过程中,输入样本被映射为一个分布的均值和方差,然后从中采样一个点进行解码,并计算重建误差。
✅ 应用场景:图像生成、数据增强
📚 推荐阅读:Auto-Encoding Variational Bayes
5. 小结
本文系统地介绍了自动编码器的基本原理、结构组成、训练方法以及常见类型。自动编码器不仅在数据压缩、特征提取方面表现优异,还在图像处理、生成建模等领域发挥着重要作用。
✅ 关键点总结:
| 类型 | 核心机制 | 典型用途 |
|---|---|---|
| 去噪自动编码器 | 输入加噪,输出去噪 | 图像去噪 |
| 稀疏自动编码器 | 稀疏惩罚 | 正则化、特征选择 |
| 深度自动编码器 | 多层结构 | 降维、压缩 |
| 收缩自动编码器 | 惩罚编码波动 | 数据增强 |
| 欠完备自动编码器 | 编码维度小 | 特征提取 |
| 卷积自动编码器 | 卷积结构 | 图像分割 |
| 变分自动编码器 | 概率分布建模 | 图像生成 |
自动编码器种类繁多,选择时应根据具体任务需求灵活选用。希望本文能为你的项目选型提供参考。