1. 引言
在本篇文章中,我们将深入探讨如何从给定文本中自动提取关键词(Keyword)和关键短语(Keyphrase)。这类技术属于信息检索(Information Retrieval, IR)范畴,通常借助自然语言处理(Natural Language Processing, NLP)的方法实现。
关键词是指能够概括文本核心内容的单词,而关键短语则是由多个词组成的短语。关键短语提取(Keyphrase Extraction)就是通过算法自动识别这些具有代表性的短语,从而帮助我们更好地理解、索引和分类文本内容。
2. 什么是 IR 与 NLP?
信息检索(IR) 是指从大量信息中找到与用户需求相关的资源的过程。例如,在搜索引擎中输入查询词,搜索引擎会返回与之相关的网页,这就是一个典型的 IR 场景。
自然语言处理(NLP) 是人工智能的一个分支,专注于让机器理解人类语言。它融合了语言学、计算机科学和人工智能的理论与技术。与编程语言相比,自然语言具有高度的歧义性和不规则性,这对机器处理构成了挑战。
NLP 提供了多种语法和语义分析技术,可用于执行拼写纠正、语法纠正、翻译、摘要生成、关键短语提取等任务。
3. 基础概念
在深入探讨关键短语提取算法之前,我们需要理解一些 NLP 和语言学中的基本术语。
3.1. 语言学中的术语
- Token(词元):文本中最小的语言单位,如单词、标点等。
- Type(类型):指一个词元的唯一形式。
- Vocabulary(词汇表):一个语言中所有不同词元的集合。
- n-gram:连续 n 个词元构成的序列,如 unigram(1-gram)、bigram(2-gram)等。
- Corpus(语料库):用于语言研究的结构化文本集合,复数为 corpora。
3.2. 语言模型
语言模型的目标是根据已有文本预测下一个可能出现的词。传统方法是基于统计的 n-gram 模型:
$$ P(w^{n}{1}) = \prod{k=1}^{n}P(w_{k}|w^{k-1}_{1}) $$
但随着深度学习的发展,神经语言模型(Neural Language Modeling) 成为主流,能更准确地捕捉上下文关系。
3.3. 相关性函数
在 NLP 中,我们需要衡量某个词或短语对文本的重要性。常用方法包括:
- TF-IDF:衡量词在文档中的重要性,公式如下:
$$ tf\text{-}idf(t,d,D) = tf(t,d) \times idf(t,D) $$
- BM25:基于概率模型的改进版 TF-IDF,广泛用于搜索引擎。
3.4. 词语相似度
判断两个词或短语之间的相似性是 NLP 的关键任务之一。常用方法包括:
- Jaccard 相似度
- Levenshtein 距离
- 余弦相似度(Cosine Similarity)
其中,词向量(Word Embeddings) 是当前最有效的方法之一。例如,Word2Vec、GloVe 和 BERT 都能生成高质量的词向量:

4. 数据预处理与清洗
在使用任何 NLP 算法前,数据预处理是必不可少的步骤。自然语言文本通常杂乱无章,需经过清理和结构化处理。
4.1. 分词(Tokenization)
将文本拆分为更小单位(如句子、词、字符)的过程。英文中通常以空格为界,但中文等语言需使用专门的分词工具。

4.2. 词干提取与词形还原
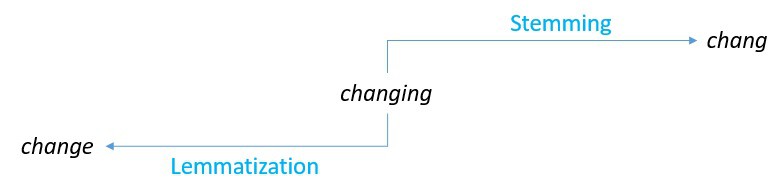
- Stemming(词干提取):通过简单规则截断词尾,获取词根。
- Lemmatization(词形还原):基于词典和语法分析,还原为标准词形。
4.3. 词性标注(Part-of-Speech Tagging)
识别每个词在句子中的语法角色(名词、动词等),有助于筛选出名词短语等关键结构。

4.4. 命名实体识别(NER)
识别文本中的人名、地名、组织名等实体,是信息抽取的重要环节。

4.5. 搭配提取(Collocation Extraction)
识别高频共现的词组,如“strong tea”、“powerful computer”,有助于发现语义紧密的短语。

5. 关键短语提取算法
关键短语提取通常分为两个阶段:
- 候选识别(Candidate Identification)
- 关键短语选择(Keyphrase Selection)
5.1. 候选识别
- Tokenization:将文本拆分为词元
- 去除停用词和标点
- Stemming / Lemmatization:统一词形
- PoS Tagging:筛选名词短语
- NER:提取实体短语
- Collocation Extraction:识别高频搭配
目的是缩小候选范围,提高后续处理效率。
5.2. 关键短语选择
- 统计方法:如 TF-IDF、BM25,但频率不总是最佳指标
- 监督学习:需要标注数据训练模型
- 无监督学习:无需标注数据,适合大规模应用
5.3. 无监督方法
图排序算法(Graph-based Ranking)是无监督提取的关键技术之一。它将候选短语作为图节点,共现或语义关系作为边,通过图结构评估节点重要性。
常见算法包括:
- TextRank
- PageRank
- HITS
以 PageRank 为例,节点得分公式为:
$$ S(V_{i}) = (1-d) + d \cdot \sum_{j \in In(V_{i})} \frac{1}{|Out(V_{j})|} S(V_{j}) $$
其中:
- $ In(V_i) $:指向节点 $ V_i $ 的节点集合
- $ Out(V_j) $:节点 $ V_j $ 所指向的节点集合
- $ d $:阻尼因子(通常设为 0.85)
5.4. 有监督方法
将关键短语提取问题转化为分类或排序任务:
- 分类模型:判断某个短语是否为关键短语
- 排序模型:对候选短语进行排序
特征包括:
- 词频
- 位置信息(如首次出现位置)
- 词性组合
- 语义相似度
常用算法:
- Naive Bayes
- Decision Trees
- SVM
- KEA(一种基于 TF-IDF 和位置信息的分类方法)
KEA 模型公式如下:
$$ P[yes] = \frac{Y}{Y + N} \cdot P_{TF\text{-}IDF}[t|yes] \cdot P_{distance}[d|yes] $$
$$ P[no] = \frac{Y}{Y + N} \cdot P_{TF\text{-}IDF}[t|no] \cdot P_{distance}[d|no] $$
最终根据概率对候选短语进行排序。
6. 总结
本文系统介绍了信息检索与自然语言处理的基本概念,重点讲解了关键短语提取的核心技术与算法。我们从数据预处理开始,逐步过渡到候选识别与关键短语选择阶段,涵盖了无监督与有监督方法的典型实现。
✅ 关键点总结如下:
- 关键短语提取是 NLP 的重要应用,广泛用于信息检索、摘要生成、内容分类等场景
- 数据预处理至关重要,包括分词、词形还原、词性标注等
- 图排序算法(如 TextRank、PageRank)是无监督提取的主流方法
- 有监督方法如 KEA 可以获得更高精度,但依赖标注数据
掌握这些技术,将有助于我们更好地理解和处理自然语言文本,构建更智能的信息系统。