1. 概述
本文将讲解二叉查找树(Binary Search Tree, BST)这种数据结构的基本原理和常见操作实现。
BST 是一种支持快速查找、插入和删除操作的数据结构,同时还能按顺序遍历元素。我们将从基本概念讲起,然后逐步实现查找、插入和遍历等核心操作。
2. 二叉查找树概述
简单来说,二叉查找树是一种满足“二叉搜索性质”的二叉树结构。每个节点的值:
- 都大于其左子树中任意节点的值;
- 都小于其右子树中任意节点的值。
如下图所示:
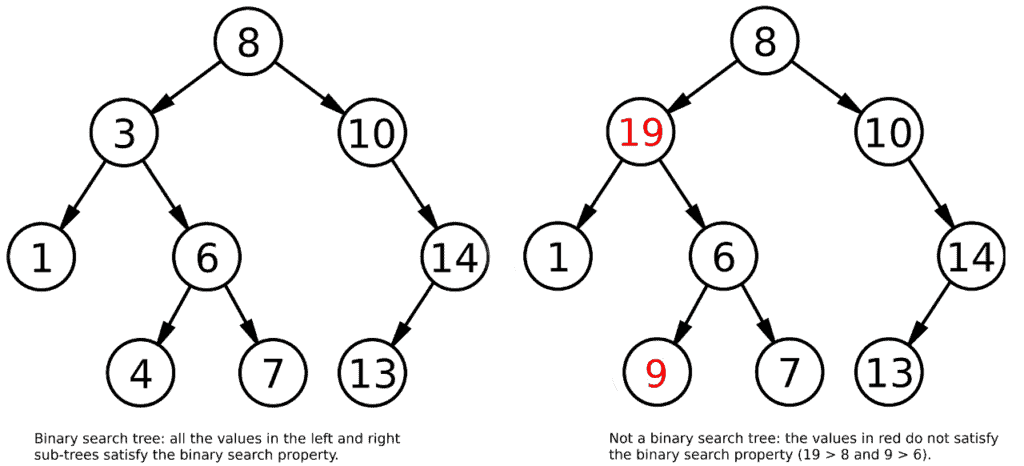
这种特性使得我们每次查找、插入或删除时,都可以根据当前节点的值决定是往左还是往右走,从而大幅提高效率。理想情况下,这些操作的时间复杂度为 O(log n)。
举个例子:我们要查找值为 9 的节点,由于 9 > 8(根节点),我们可以直接跳过整个左子树,大幅减少查找范围。
2.1. 查找操作
BST 的查找逻辑非常直观:
- 如果目标值等于当前节点值,查找成功;
- 如果目标值小于当前节点值,则去左子树继续查找;
- 如果目标值大于当前节点值,则去右子树继续查找;
- 若走到空节点仍未找到,则说明该值不在树中。
下面是递归实现的 Java 伪代码:
algorithm lookup(tree, key):
// INPUT
// tree = a binary search tree
// key = the key to look for
// OUTPUT
// true if the key is found, false otherwise
if key == tree.key:
return true
if key < tree.key:
if not tree.hasLeftChild():
return false
return lookup(tree.leftChild(), key)
if key > tree.key:
if not tree.hasRightChild():
return false
return lookup(tree.rightChild(), key)
✅ 踩坑提醒:注意边界条件,比如遇到空节点要及时返回 false。
2.2. 插入操作
插入操作的核心是找到合适的位置,使得插入后仍保持 BST 的性质。
算法逻辑如下:
- 从根节点开始,比较插入值与当前节点的大小;
- 若小于当前节点且有左子节点,则递归插入左子树;
- 若小于当前节点但没有左子节点,则创建新节点作为左子节点;
- 右子节点同理。
Java 伪代码实现如下:
algorithm insert(tree, key):
// INPUT
// tree = a binary search tree
// key = the key to insert
// OUTPUT
// a binary search tree with a new node for the key,
// or the same input tree if the key already exists
if key < tree.getKey():
if tree.hasLeftChild():
insert(tree.getLeftChild(), key)
else:
tree.setLeftChild(key)
else if key > tree.getKey():
if tree.hasRightChild():
insert(tree.getRightChild(), key)
else:
tree.setRightChild(key)
⚠️ 注意:本实现未处理重复值的情况。实际开发中需根据业务需求决定是否允许重复值,若不允许,可在插入前做判断并提前返回。
2.3. 遍历操作
树是非线性结构,因此遍历顺序不唯一。BST 中最常用的是 中序遍历(in-order traversal),它能按升序输出所有节点值。
中序遍历的基本顺序是:
- 遍历左子树;
- 访问当前节点;
- 遍历右子树。
Java 伪代码如下:
algorithm dfs(tree):
// INPUT
// tree = a binary search tree
// OUTPUT
// the function prints the tree's values in depth-first in-order
if tree.hasLeftChild():
dfs(tree.getLeftChild())
print(tree.value)
if tree.hasRightChild():
dfs(tree.getRightChild())
✅ 要想按降序输出,只需将访问顺序改为:右子树 → 当前节点 → 左子树。
这种遍历方式的时间复杂度为 O(n),因为每个节点仅被访问一次。
3. 总结
本文简要介绍了二叉查找树的基本原理和常见操作:
- BST 通过“左小右大”的性质,实现了高效的查找、插入和删除;
- 常见操作的时间复杂度在理想情况下为
O(log n); - 中序遍历可按升序访问所有节点,时间复杂度为
O(n)。
BST 是许多更复杂树结构(如 AVL 树、红黑树)的基础,理解其原理对于掌握高级数据结构至关重要。