1. 概述
在注册网站账号时,我们经常会看到类似这样的提示:“该用户名或邮箱已被占用”。这个提示往往在几毫秒内就能出现,说明网站在后台快速地验证了数百万条记录是否存在。
那么,它们是如何做到的呢?其中一个高效方案就是使用 布隆过滤器(Bloom Filter)。
在本文中,我们将深入讲解布隆过滤器的基本原理、操作、应用场景和局限性,帮助你在实际项目中更好地使用这一高效数据结构。
2. 什么是布隆过滤器?
布隆过滤器是一种概率型数据结构(Probabilistic Data Structure),用于判断一个元素是否属于一个集合。虽然也可以用其他结构(如哈希表、集合)实现类似功能,但布隆过滤器在空间和时间效率上更具优势。
布隆过滤器的底层实现其实是一个位数组(bit array),初始时所有位都为0。如下图所示,是一个长度为19的布隆过滤器:

3. 布隆过滤器的操作
布隆过滤器只支持两种操作:
Insert(插入)Lookup(查找)
3.1 插入操作(Insert)
插入操作的时间复杂度和空间复杂度都是常数级 O(k),k 是哈希函数的数量。具体步骤如下:
- 对要插入的元素进行哈希运算
- 对结果取模数组长度,得到索引位置
- 将对应索引位置的 bit 设置为 1
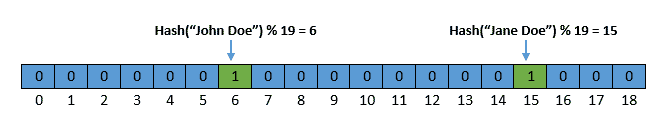
举个例子,我们插入两个字符串:John Doe 和 Jane Doe,假设它们的哈希值分别为 1355 和 8337:
- 1355 % 19 = 6
- 8337 % 19 = 15
插入后的布隆过滤器如下图所示:
3.2 查找操作(Lookup)
查找操作的时间复杂度也是 O(k)。步骤如下:
- 对要查找的元素进行哈希运算
- 对结果取模数组长度,得到索引位置
- 检查对应索引位置的 bit 是否为 1
⚠️ 注意:
- 如果某一位是 0,说明该元素一定不在集合中
- 如果所有对应的位都是 1,说明该元素可能在集合中
比如,我们检查字符串 John 是否存在,假设其哈希值 %19 = 10:
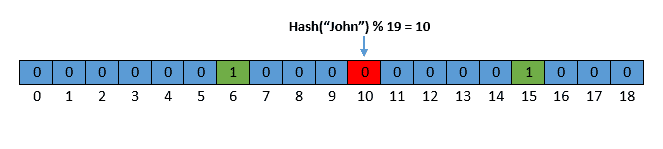
此时,第10位为0,说明 John 肯定不在布隆过滤器中。
4. 误判分析(False Positive)
布隆过滤器的高效是以概率性判断为代价的。它可能会出现误判(False Positive)的情况,即判断一个不存在的元素为存在。
4.1 误判示例
例如,我们检查 James Bond 是否存在,假设其哈希值 %19 = 6,与 John Doe 相同:
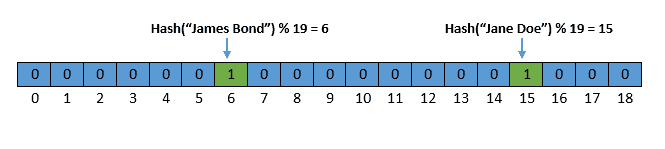
虽然 James Bond 没有被插入过,但由于其哈希值指向的位置已经被 John Doe 占用,因此返回“可能存在”。
4.2 降低误判率的方法
✅ 常见做法是使用多个哈希函数,每次插入时设置多个 bit。这样可以显著降低误判率。
❌ 但注意:布隆过滤器无法避免误判,只能降低概率。
5. 布隆过滤器的应用场景
布隆过滤器因其高效性被广泛应用于多个领域,以下是一些典型场景:
- ✅ 拼写检查器:早期拼写检查工具使用布隆过滤器判断单词是否存在
- ✅ 数据库系统:如 PostgreSQL、Apache Cassandra、Cloud Bigtable 等数据库使用布隆过滤器减少对磁盘的无效访问
- ✅ 搜索引擎:如 BitFunnel 使用布隆过滤器加速索引查询
- ✅ 安全检测:用于识别弱密码、恶意链接等
6. 布隆过滤器的局限性
虽然布隆过滤器效率高,但也有一些明显限制:
- ❌ 不支持删除操作(除非使用变体如 Counting Bloom Filter)
- ❌ 误判率不能完全消除,只能降低
- ❌ 哈希冲突是误判的主要原因
7. 总结
布隆过滤器是一种空间和时间效率都非常高的数据结构,适用于允许误判但不允许漏判的场景。
✅ 优点:
- 插入和查询速度快
- 占用内存小
❌ 缺点:
- 不支持删除
- 存在误判可能
在实际开发中,合理使用布隆过滤器可以显著提升系统性能,尤其是在大数据、高并发场景中。但在对准确性要求极高的场景下,需要谨慎使用或结合其他结构使用。