1. 简介
近年来,随着文本数据量呈指数级增长,文本挖掘和分析的重要性日益凸显,已成为许多组织处理信息的必备技能。在文本分析中,一个最具挑战性的任务就是字符串匹配。例如,我们希望知道两个字符串是否指向同一个词,或者在数据库查询时,希望搜索引擎能返回所有相关结果。
本文将介绍如何找到最接近的字符串匹配,并讲解一些常用的实现方法。
2. 什么是字符串匹配?
字符串匹配指的是在文本语料中查找与特定模式匹配的字符串并进行比较的过程。该技术广泛应用于搜索引擎、拼写检查、DNA序列分析等领域。
字符串匹配算法大致可分为两类:
- ✅ 精确匹配算法(Exact String Matching)
- ✅ 模糊匹配算法(Approximate String Matching)
下面我们将分别介绍这两类算法。
3. 精确字符串匹配
精确字符串匹配的目标是在文本中查找一个特定字符串的所有出现位置。这类匹配通常用于查找单词、句子或特定字符序列。例如:
- 在DNA序列中查找特定子序列
- 在文档中查找关键词
常见的精确字符串匹配算法包括:
- ✅ 暴力搜索算法(Brute Force)
- ✅ KMP算法(Knuth-Morris-Pratt)
- ✅ Boyer-Moore算法
3.1 暴力字符串匹配
暴力搜索是最简单的字符串匹配方法。它通过将目标字符串逐个字符滑动在文本上进行比较来查找匹配。虽然实现简单,但最坏情况下的时间复杂度为 O(m * n),其中 m 是模式串长度,n 是文本长度。
虽然效率不高,但适合短文本或作为教学示例使用。
3.2 KMP算法(Knuth-Morris-Pratt)
KMP算法通过预处理模式串,构建一个最长前缀后缀数组(LPS Array),从而避免每次匹配失败后都要回退文本指针的问题。
举个例子:我们要在文本 A T G A T A 中查找模式 A T A:
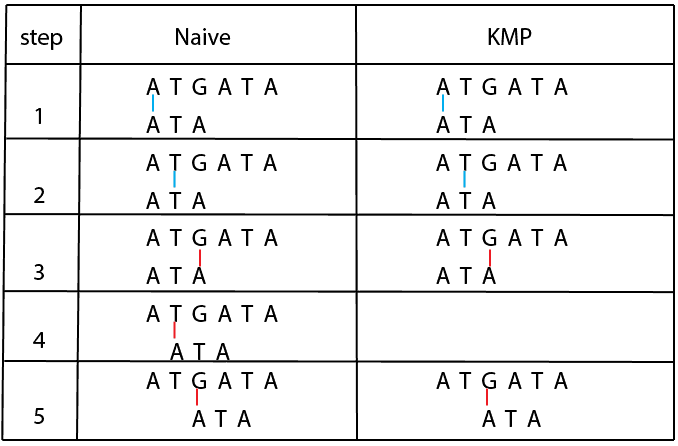
KMP算法利用LPS数组跳过已知不可能匹配的位置,从而提高效率。其时间复杂度为 O(m + n),非常适合长模式匹配场景。
3.3 Boyer-Moore算法
Boyer-Moore算法与KMP类似,但其比较方向是从右向左,且使用了两个规则来决定模式串的移动步数:
- ✅ 坏字符规则(Bad Character Rule)
- ✅ 好后缀规则(Good Suffix Rule)
坏字符规则示例
假设我们有文本 T = "ABABABACF",模式 P = "ABAC"。当发现字符不匹配时,算法会将模式向右移动,直到该坏字符与模式中相同字符对齐,或者模式完全跳过该字符。
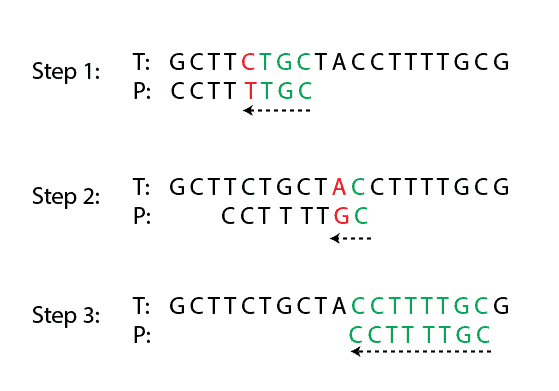
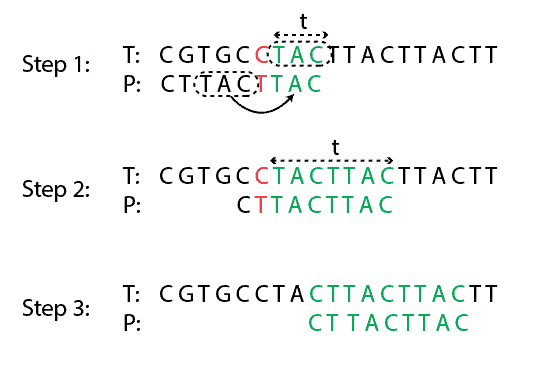
好后缀规则示例
当部分匹配后发生不匹配时,模式将移动到使已匹配的后缀再次匹配的位置。
实际中,Boyer-Moore会综合使用两个规则,取移动步数最大的那个。时间复杂度也为 O(m + n),适用于大多数实际场景。
4. 模糊字符串匹配(Approximate String Matching)
模糊字符串匹配,也称为模糊匹配,是一种查找与目标模式“近似”匹配字符串的技术。它通常用于:
- ✅ 拼写纠错
- ✅ 数据清洗
- ✅ 近似搜索
模糊匹配的核心是衡量两个字符串之间的相似度或距离。常用的字符串距离度量包括:
- ✅ Levenshtein距离
- ✅ Hamming距离
- ✅ Damerau-Levenshtein距离
- ✅ Jaro距离
- ✅ Jaro-Winkler距离
4.1 Levenshtein距离
Levenshtein距离是指将一个字符串转换为另一个所需的最少单字符编辑操作数(插入、删除、替换)。
例如,“kitten” 与 “sitting” 的Levenshtein距离为3:
- kitten → sitten(替换)
- sitten → sittin(替换)
- sittin → sitting(插入)
4.2 Hamming距离
Hamming距离是两个等长字符串在对应位置上不同字符的数量。它常用于二进制数据比较,但不适用于长度不一致的字符串。
例如,“1011101” 与 “1001001” 的Hamming距离为2。
4.3 其他字符串相似度指标
除了上述两种,还有一些其他字符串相似度指标:
- ✅ Damerau-Levenshtein距离(允许交换相邻字符)
- ✅ Jaro距离(考虑字符顺序)
- ✅ Jaro-Winkler距离(对前缀更敏感)
此外,我们还可以将这些距离转化为相似度比例,例如:
- 3字符字符串差异为1 → 比例为
1/3 = 0.33(差异33.33%) - 10字符字符串差异为1 → 比例为
1/10 = 0.1(差异10%)
4.4 基于向量的相似度匹配
我们也可以将字符串转换为向量后再进行相似度计算。常用方法包括:
- ✅ One-hot编码
- ✅ TF-IDF
- ✅ Word2vec
- ✅ BERT
这些方法可以用于更复杂的自然语言处理任务,如语义相似度计算。
5. 总结
本文介绍了字符串匹配的基本概念和主要算法,包括精确匹配与模糊匹配两大类。
- ✅ 精确匹配适用于查找完全一致的字符串,常用算法包括KMP、Boyer-Moore等
- ✅ 模糊匹配用于查找“近似”字符串,常用指标包括Levenshtein距离、Hamming距离、Jaro-Winkler等
- ✅ 实际应用中,建议结合多种指标,并根据具体场景进行调优
⚠️ 模糊匹配是一个高度依赖领域的问题,没有通用的“最优”算法。建议根据具体数据集尝试多种方法,组合使用以获得最佳效果。