1. 引言
在本教程中,我们将探讨特征相关性对机器学习分类算法的影响。虽然相关性本身并不一定有害,但如果不加以处理,它可能会对模型的预测性能产生负面影响。
需要注意的是,相关性并不意味着因果关系。在构建模型时,我们应关注数据中是否存在冗余信息,并通过适当的预处理手段来减少特征数量,从而提升模型的泛化能力。
2. 相关性与因果性
相关性 ≠ 因果性。举个例子:
- 风速增加 → 风力发电机叶片转速增加 → 发电量增加
- 但反过来,叶片转速增加不会导致风速增加
虽然这两个变量之间存在强相关性,但它们之间的因果关系是单向的。
从统计学角度来看:
- 相关性是对称的(A 与 B 相关 ⇔ B 与 A 相关)
- 因果性是不对称的
在机器学习中,我们更关注变量之间的统计相关性,而不是因果关系。因为大多数模型本质上是统计模型,它们依赖于数据中的模式,而不是背后的物理机制。
3. 相关性与共线性
3.1 相关性的定义
- 相关性(Correlation)是衡量两个变量之间线性依赖程度的统计量
- 可以是正相关(同向变化)或负相关(反向变化)
- 两个变量独立 ⇨ 它们不相关
常用的相关系数有:
| 方法 | 适用场景 |
|---|---|
| 皮尔逊相关系数(Pearson) | 线性关系 |
| 斯皮尔曼等级相关(Spearman) | 非线性单调关系 |
| 互信息(Mutual Information) | 更复杂的非线性关系 |
✅ 相关性可以是正向的:知道一个变量有助于预测另一个变量
❌ 但高相关性也可能带来问题:如特征冗余、模型过拟合等
3.2 皮尔逊相关系数公式
皮尔逊相关系数计算公式如下:
$$ \rho_{XY} = \frac{\Sigma_{XY}}{\sigma(X)\sigma(Y)} = \frac{\mathrm{E}[(X - \mu_X)(Y - \mu_Y)]}{\sigma(X)\sigma(Y)} $$
其中:
- $\Sigma_{XY}$ 是协方差
- $\sigma(X)$, $\sigma(Y)$ 是标准差
- $\mu_X$, $\mu_Y$ 是均值
3.3 共线性(Collinearity)
共线性指的是一个特征可以被其他特征线性表示的现象。它分为:
- 完全共线性:一个特征能被其他特征精确表示
- 多重共线性:一个特征能被其他特征高度预测
在回归模型中,共线性会导致以下问题:
⚠️ 矩阵不可逆:$(\mathbf{X}^T\mathbf{X})^{-1}$ 不存在
⚠️ 参数估计不稳定:小的数据扰动会导致回归系数大幅波动
⚠️ 解释性差:无法准确判断单个特征对输出的影响
3.4 共线性带来的问题
数学上,共线性会导致以下情况:
- $\mathbf{X}^T\mathbf{X}$ 矩阵秩不足(rank-deficient)
- $\det(\mathbf{X}^T\mathbf{X}) = 0$,矩阵不可逆
- 最小二乘法失效
例如,一个 $2 \times 2$ 矩阵:
$$ \mathbf{A} = \begin{bmatrix} a & b \ c & d \end{bmatrix}, \quad \mathbf{A}^{-1} = \frac{1}{ad - bc} \begin{bmatrix} d & -b \ -c & a \end{bmatrix} $$
如果 $ad - bc = 0$,则矩阵不可逆。
4. 维度灾难(Curse of Dimensionality)
4.1 问题描述
特征数量 $D$ 越多,输入空间的体积呈指数级增长:
- 每个特征分成 $M$ 个区间
- 总单元数为 $M^D$
这会导致:
✅ 初始阶段:分类性能提升(信息更丰富)
❌ 超过某个阈值后:分类性能下降(数据稀疏)
例如,图像识别中使用像素作为特征,可能会导致上万维特征空间。如果数据量不够,很多区域将没有训练样本,模型泛化能力差。
4.2 解决方案
- 减少特征数量:删除冗余或不重要的特征
- 特征降维:如 PCA、LDA、t-SNE 等
- 增加数据量:成本高,不总是可行
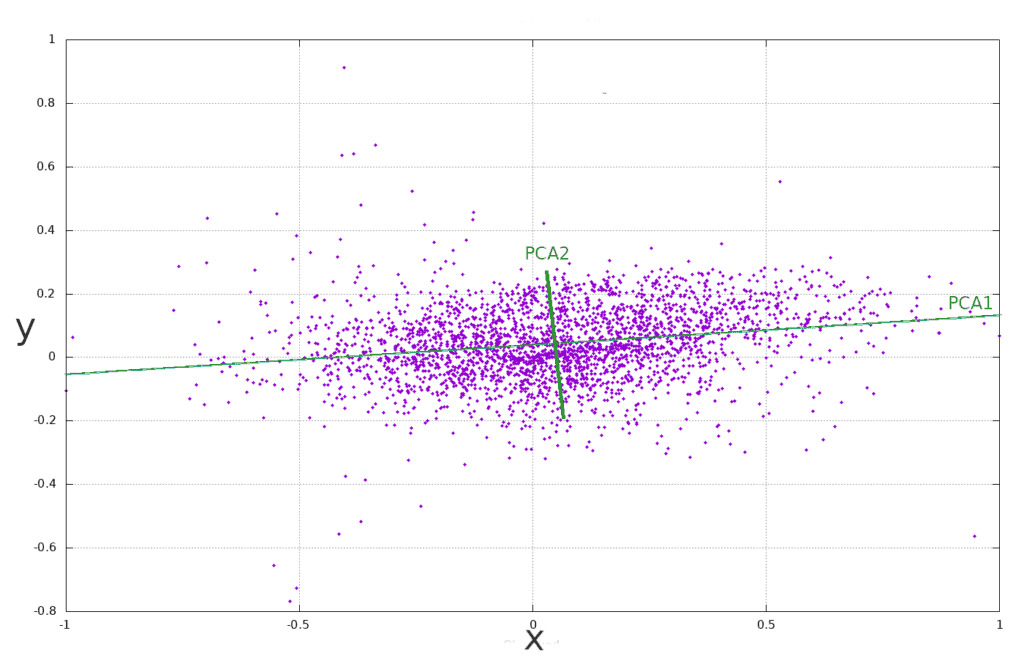
5. 主成分分析(PCA)
PCA 是一种常用的降维技术,其核心思想是:
- 找到一组新的正交基(主成分)
- 将数据投影到这些基上
- 保留尽可能多的方差(信息)
5.1 PCA 的作用
- 消除特征间的相关性
- 降低特征维度
- 保留数据的主要变化方向
- 提升模型效率和稳定性
5.2 PCA 的目标
将原始输入矩阵 $\mathbf{X} \in \mathbb{R}^{N \times D}$ 转换为一个新的满秩矩阵 $\mathbf{X'} \in \mathbb{R}^{N \times K}$,其中 $K < D$。
这样做的好处是:
- 消除共线性问题
- 减少冗余信息
- 控制信息损失程度
- 提升模型泛化能力
5.3 PCA 的数学基础
- 协方差矩阵:$\mathbf{C} = \frac{1}{N} \mathbf{X}^T \mathbf{X}$
- 特征值分解:$\mathbf{C} = \mathbf{V} \Lambda \mathbf{V}^T$
- 投影矩阵:$\mathbf{P} = \mathbf{V}_k$(前 $k$ 个特征向量)
最终变换为:
$$ \mathbf{X'} = \mathbf{X} \cdot \mathbf{V}_k $$
6. 总结
- 相关性 ≠ 因果性,但相关性可能引入冗余信息
- 共线性会影响模型稳定性,特别是回归模型
- 维度灾难限制了我们可以使用的特征数量
- PCA 是一种有效的降维工具,可帮助我们处理相关性和共线性问题
✅ 建议实践:
- 在建模前进行相关性分析
- 使用 PCA 或其他降维方法处理高维数据
- 注意特征选择,避免冗余
掌握这些技术,有助于你构建更稳定、更高效的分类模型。