1. 概述
本文将探讨为什么逻辑回归模型的成本函数采用对数形式。
我们会从梯度下降的学习机制谈起,了解一个函数能够通过梯度下降学习的条件。
接着,我们定义逻辑回归的数学模型,并讨论其似然函数(likelihood function)的性质。这将帮助我们理解为什么在一般情况下,逻辑回归参数的学习并不总是能保证收敛。
最后,我们会引入对数似然函数(log-likelihood),分析其在参数学习上的优势。
文章结尾,你将理解为什么逻辑回归使用对数形式的成本函数,以及它与函数可学习性之间的理论联系。
2. 通过梯度下降学习参数
2.1 参数学习的问题
要理解为什么逻辑回归使用对数成本函数,首先要理解梯度下降对函数形式的要求。
梯度下降是一种用于优化连续可导函数参数的通用方法,广泛用于神经网络权重的学习,也适用于逻辑回归模型的参数学习。
要使用梯度下降,目标函数必须满足以下条件:
✅ 函数在定义域内连续且可导
✅ 函数是凸函数(convex)
✅ 函数的梯度是Lipschitz连续的
满足这些条件后,我们就能通过梯度下降逼近任意精度的最小值点。
2.2 梯度下降的要求
如果一个函数满足上述条件,那么我们可以找到一个点 $ x^* $,使得:
$$ f(x^*) - f(x_0) < \epsilon $$
其中 $ x_0 $ 是使得 $ f'(x_0) = 0 \wedge f''(x_0) \geq 0 $ 的点,$ \epsilon $ 是任意设定的精度。
换句话说,只要目标函数及其梯度满足这些性质,我们就能通过梯度下降找到一个足够接近最小值的点。
因此,我们可以将选择逻辑回归成本函数的问题转化为选择一个可以在其上应用梯度下降的函数。
3. 逻辑回归模型
3.1 逻辑函数回顾
逻辑回归模型本质上是一个将线性函数映射到 (0,1) 区间的函数,形式如下:
$$ y = \frac{1}{1 + e^{-(ax + b)}} $$
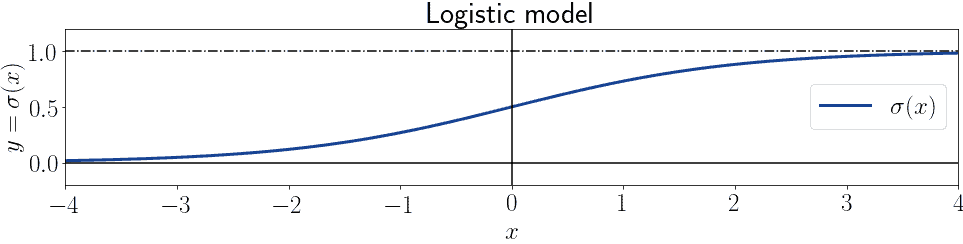
当 $ a = 1, b = 0 $ 时,该函数呈现出经典的 S 型曲线:
3.2 广义线性模型与参数变化
虽然函数形式不变,但参数 $ a $ 和 $ b $ 的不同会导致函数值变化很大:
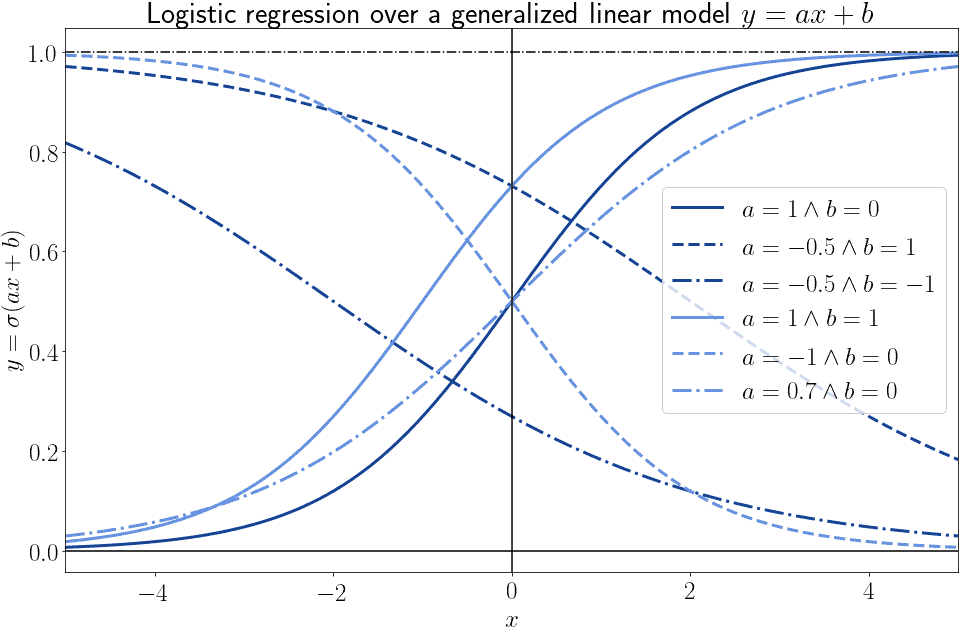
对于任意点 $ (x, y) $,存在无数个逻辑模型可以经过该点,每个模型对应一组 $ (a, b) $ 参数。
3.3 与训练数据的拟合
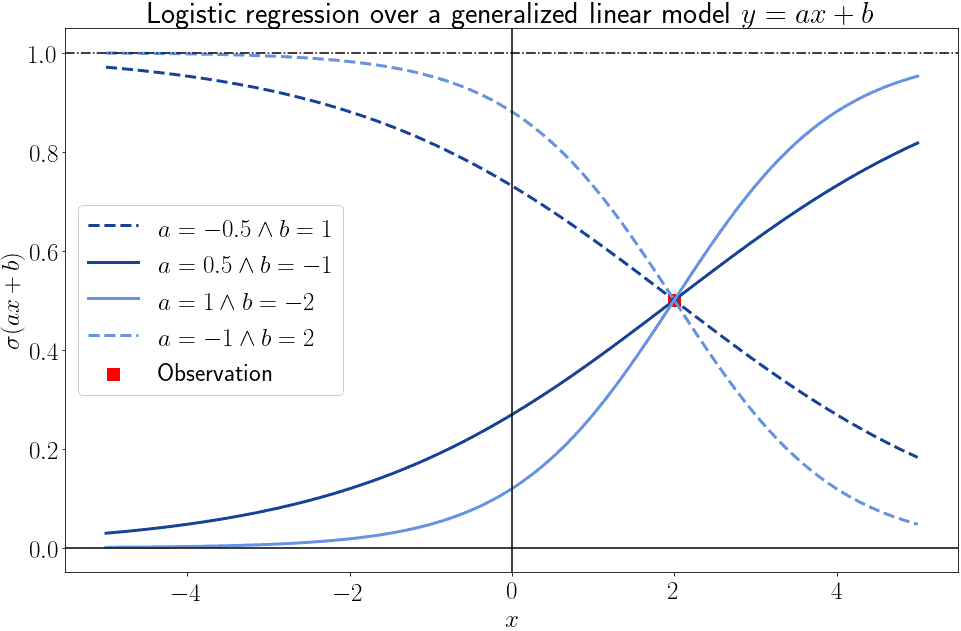
仅凭一个样本点,无法确定最佳逻辑模型:
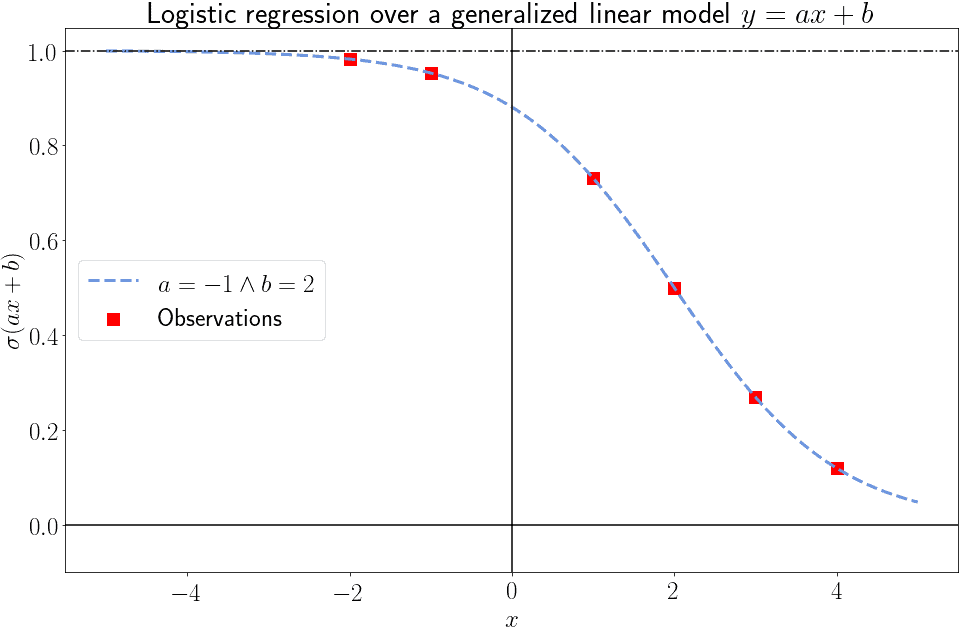
但随着样本数量增加,可以逐步缩小可能的模型范围,最终确定一个最佳拟合模型:
3.4 逻辑回归的数学定义
逻辑回归模型是一个映射:
$$ f: (-\infty, \infty) \to (0, 1) $$
用于建模伯努利分布的因变量 $ y \in {0,1} $ 与自变量向量 $ X = {x_1, x_2, ..., x_n} $ 的关系。
逻辑回归函数可写为:
$$ y = \frac{1}{1 + e^{-A^T X}} $$
其中 $ A = {a_0, a_1, ..., a_n} $ 是模型参数。
3.5 参数形式的逻辑回归
逻辑回归的参数形式为:
$$ P(y=1|X,A) = \frac{1}{1 + e^{-A^T X}} $$
同时,$ P(y=0|X,A) = 1 - P(y=1|X,A) $
对于单个样本 $ (x_i, y_i) $,其概率可写为:
$$ P(y_i|x_i, A) = f(x_i)^{y_i}(1 - f(x_i))^{1 - y_i} $$
对所有样本的联合概率,即似然函数为:
$$ L(A|X,Y) = \prod_{i=1}^{n} f(x_i)^{y_i}(1 - f(x_i))^{1 - y_i} $$
4. 逻辑回归的成本函数
4.1 为什么不用均方误差?
我们希望找到一组参数 $ A $,使得模型预测值尽可能接近真实值。
在回归问题中,常用均方误差(MSE)作为损失函数:
$$ MSE = \frac{1}{n} \sum_{i=1}^{n} (h_A(x_i) - y_i)^2 $$
但逻辑函数本身不是凸函数,所以 MSE 也不保证是凸函数。
这意味着使用 MSE 无法保证梯度下降能找到全局最小值。
4.2 凸性问题
逻辑函数在某些区域是凸的,但整体不是凸的:
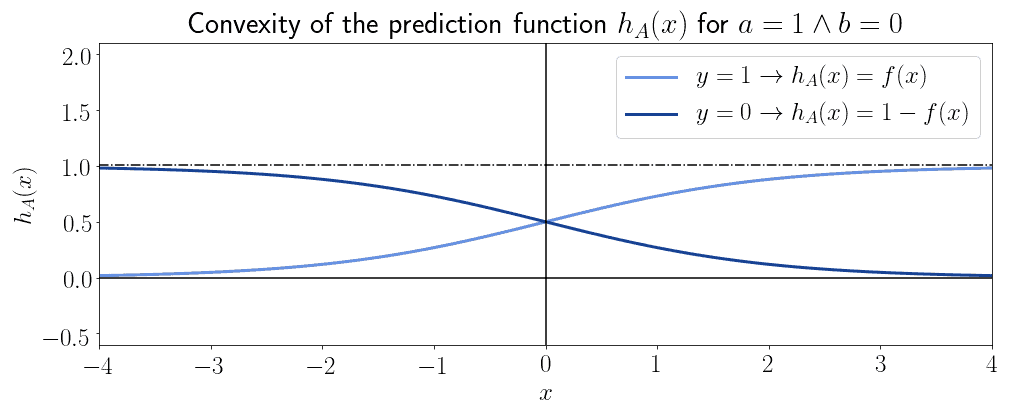
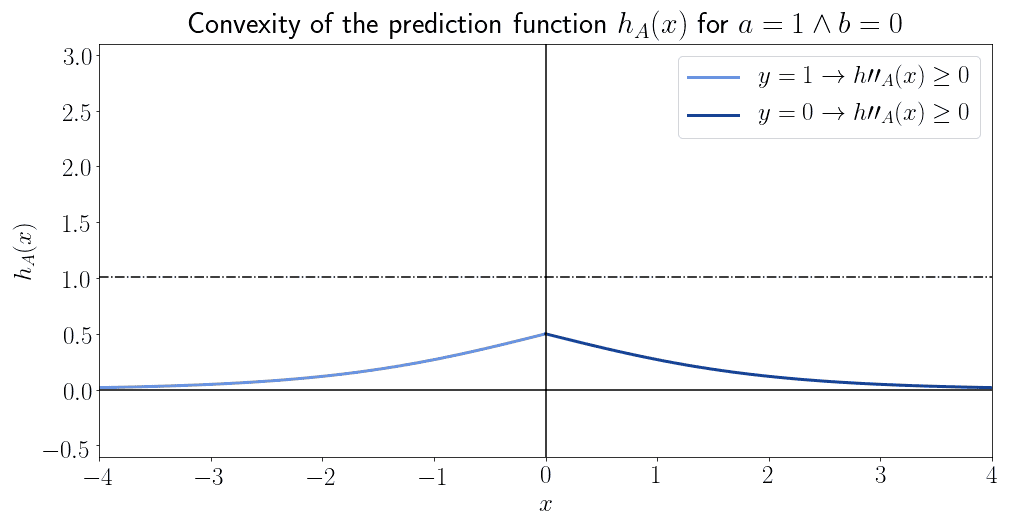
这意味着 MSE 无法保证收敛。
4.3 对数预测函数的优势
考虑使用逻辑函数的对数形式:
- 当 $ y_i = 1 $ 时,使用 $ \log(h_A(x_i)) $
- 当 $ y_i = 0 $ 时,使用 $ \log(1 - h_A(x_i)) $
这两个函数本身不是凸函数:
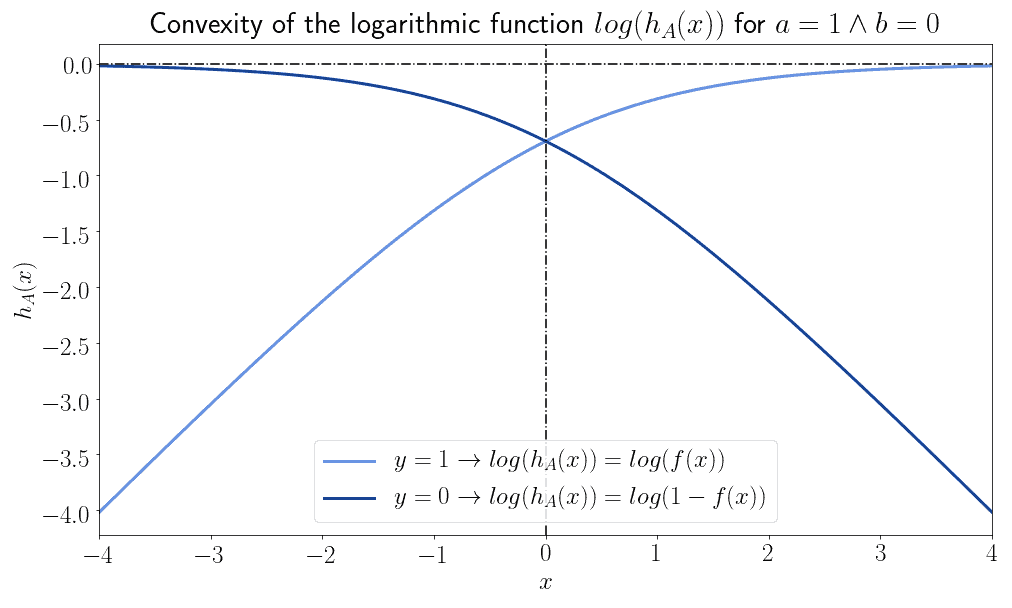
但如果我们将它们垂直翻转,它们就变成了凸函数:
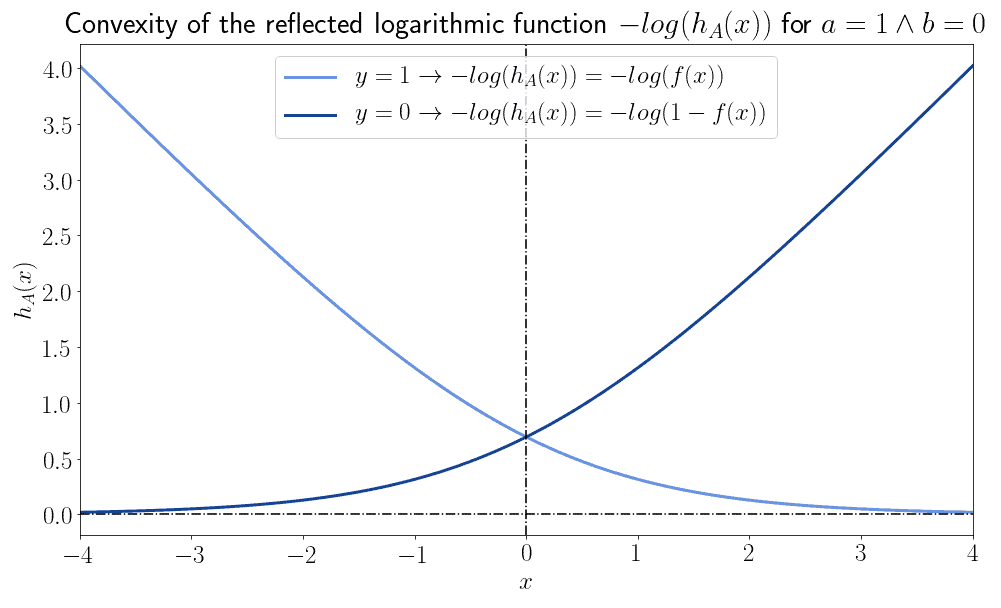
4.4 成本函数与优化
因此,我们可以定义如下成本函数:
$$ Err(h_A, y) = -y \cdot \log(h_A(x)) - (1 - y) \cdot \log(1 - h_A(x)) $$
这个函数在整个定义域内是凸的。
我们可以将优化问题定义为:
$$ J(A) = \frac{1}{n} \sum_{i=1}^{n} \left[ -y_i \cdot \log(h_A(x_i)) - (1 - y_i) \cdot \log(1 - h_A(x_i)) \right] $$
4.5 凸性、梯度下降与对数似然
总结我们上面的分析:
✅ 成本函数是优化模型参数的核心
✅ 梯度下降是最常用的优化方法
✅ 梯度下降要求成本函数是凸的
❌ MSE 在逻辑回归中不保证凸性
✅ 对数似然函数是凸的,适合用作成本函数
因此,我们选择对数似然函数作为逻辑回归的成本函数。
5. 总结
本文探讨了为什么逻辑回归使用对数形式的成本函数。
我们首先了解了梯度下降对函数形式的要求,接着分析了最大似然函数的性质,最后得出结论:由于对数似然函数具有凸性,适合用于梯度下降优化。
✅ 使用对数似然函数确保了参数学习的收敛性
✅ MSE 在逻辑回归中不保证凸性,不适合直接使用
✅ 对数似然函数更适合作为逻辑回归的成本函数
这样,我们就从理论层面理解了逻辑回归成本函数为何采用对数形式。