1. 概述
在机器学习模型开发过程中,模型评估是不可或缺的一环。本文将重点介绍两种常用的交叉验证技术:K 折交叉验证(K-Fold Cross-Validation) 和 留一法交叉验证(Leave-One-Out Cross-Validation, LOO)。
我们会从最基础的训练集/测试集划分方法讲起,说明为什么需要交叉验证。然后分别介绍 K 折和 LOO 的工作原理,并通过对比分析它们各自的优缺点。
2. 训练集/测试集划分方法
在构建机器学习模型时,我们希望得到一个对模型性能的无偏估计。为了实现这一点,必须使用未参与训练的数据来评估模型表现。
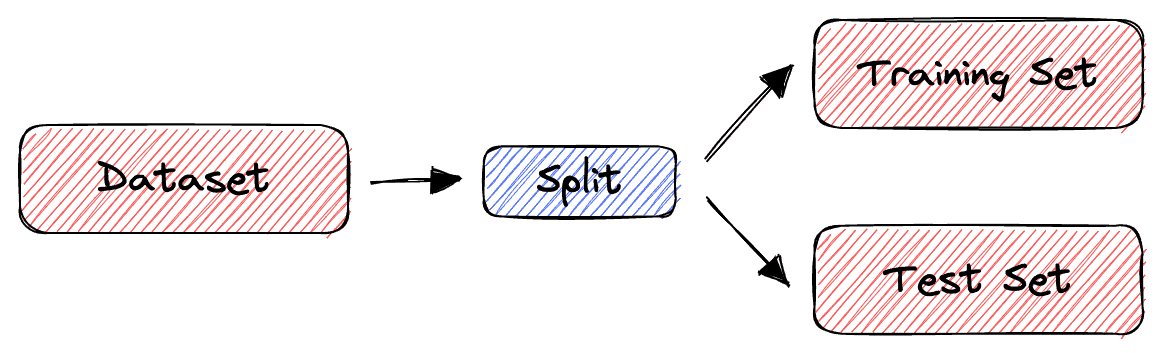
最简单的方法是将数据集划分为两个子集:训练集(Training Set) 和 测试集(Test Set)。训练集用于模型训练,测试集用于评估模型泛化能力。
这种方法虽然简单,但也存在明显缺陷:
✅ 实现简单,速度快
❌ 对数据划分敏感,尤其是数据量少时,结果波动大
❌ 可能导致模型评估结果偏差较大
下图展示了训练集/测试集划分的基本流程:
3. 交叉验证简介
为了缓解训练集/测试集划分带来的不稳定性,我们引入交叉验证(Cross-Validation)机制。
交叉验证的核心思想是:多次划分训练集和测试集,取平均性能作为最终评估结果。这样可以有效降低单次划分带来的随机性影响,使评估结果更加稳定可靠。
常见的交叉验证方法包括:
- K 折交叉验证
- 分层 K 折交叉验证(Stratified K-Fold)
- 留一法(Leave-One-Out)
- 留 P 法(Leave-P-Out)
本文我们重点介绍前两种:K 折交叉验证 和 留一法(LOO)
4. K 折交叉验证
K 折交叉验证是一种广泛使用的交叉验证方法。其核心步骤如下:
- 将数据集划分为 K 个大小相等的子集(称为“Fold”)
- 依次将每个子集作为测试集,其余 K-1 个子集合并为训练集
- 重复 K 次训练和评估过程
- 最终结果为 K 次评估结果的平均值
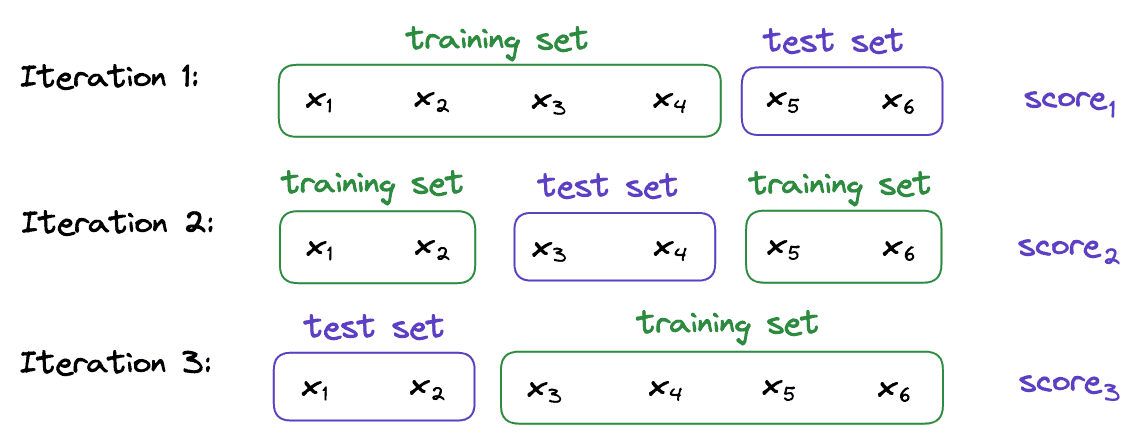
举个例子,假设我们有一个包含 6 个样本的数据集:
S = {x1, x2, x3, x4, x5, x6}
我们选择 K=3,则划分可能如下:
S1 = {x1, x2}
S2 = {x3, x4}
S3 = {x5, x6}
交叉验证过程如下图所示:
最终模型性能为:
$$ \text{overall score} = \frac{score_1 + score_2 + score_3}{3} $$
✅ 优点:
- 计算效率较高
- 适用于中等规模数据集
- 结果相对稳定
❌ 缺点:
- 若 K 值选择不当,仍可能引入偏差
- 对数据分布不均匀的场景效果一般
5. 留一法交叉验证(LOO)
留一法(Leave-One-Out)是一种极端的交叉验证方法,其核心思想是:
- 每次只留一个样本作为测试集,其余所有样本作为训练集
- 重复训练 N 次(N 为样本总数)
- 最终结果为 N 次评估结果的平均值
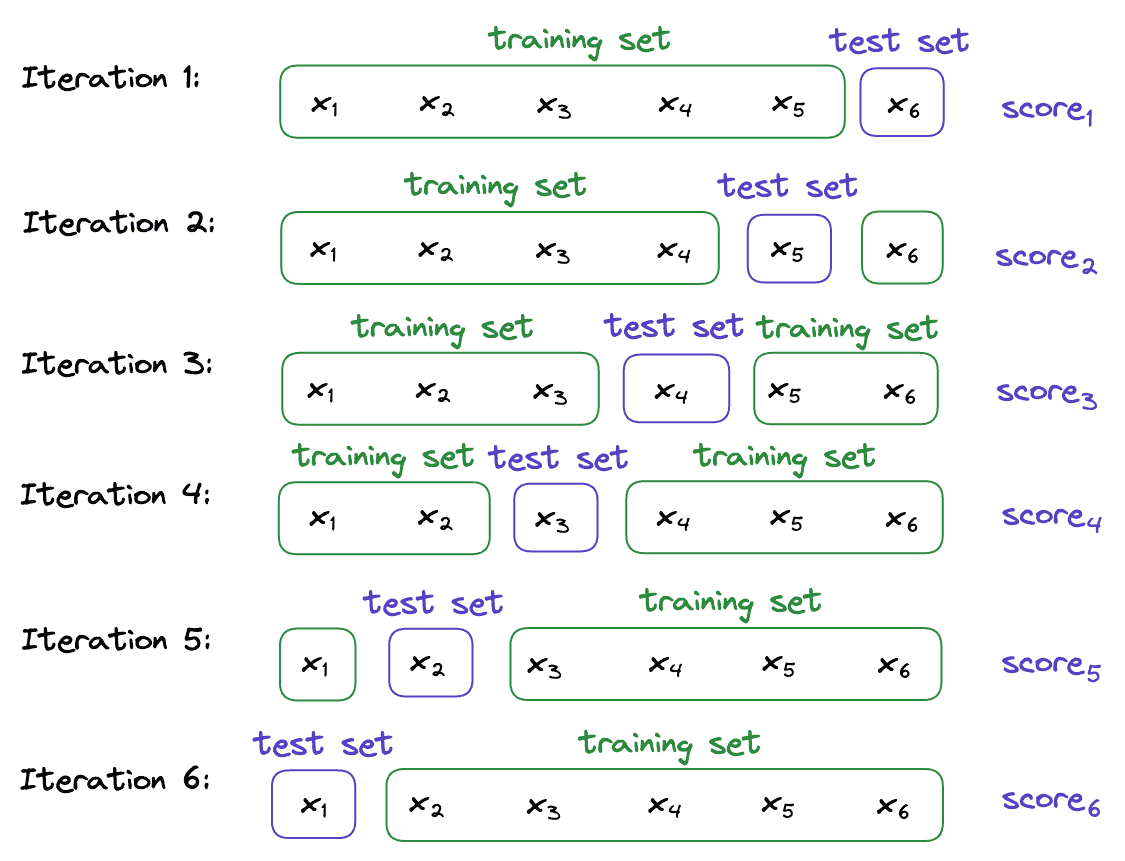
继续用上面的例子,若数据集仍为:
S = {x1, x2, x3, x4, x5, x6}
则 LOO 的划分如下:
S1 = {x1}, S2 = {x2}, S3 = {x3}, S4 = {x4}, S5 = {x5}, S6 = {x6}
每次训练时使用其余 5 个样本,测试时使用留出的那个。整个流程如下图所示:
最终模型性能为:
$$ \text{overall score} = \frac{score_1 + score_2 + score_3 + score_4 + score_5 + score_6}{6} $$
✅ 优点:
- 几乎没有划分偏差
- 利用率高,每次训练都使用了几乎全部数据
❌ 缺点:
- 计算成本极高,尤其是大数据集
- 训练时间长,不适用于实时场景
6. 方法对比
| 特性 | K 折交叉验证 | 留一法(LOO) |
|---|---|---|
| 数据使用率 | 中等(K-1)/K | 极高(N-1)/N |
| 计算成本 | ✅ 低 | ❌ 高 |
| 结果稳定性 | ✅ 中等 | ✅ 高 |
| 适用数据量 | ✅ 中大型 | ✅ 小型 |
| 是否受划分影响 | ✅ 是 | ❌ 否 |
| 是否适合调参 | ✅ 是 | ❌ 否 |
⚠️ 选择建议:
- 数据量较小时(如 < 1000),优先考虑 LOO
- 数据量较大时(如 > 10000),建议使用 K 折(K=5 或 10)
- 若需调参,推荐使用 K 折交叉验证,效率更高
7. 总结
本文介绍了两种常用的交叉验证方法:K 折交叉验证 和 留一法交叉验证。它们各有适用场景:
- K 折交叉验证:适合中大型数据集,计算效率高,评估结果相对稳定
- 留一法交叉验证:适合小型数据集,评估结果更精确,但计算开销大
在实际项目中,应根据数据规模、计算资源和评估精度需求灵活选择。合理使用交叉验证技术,有助于我们更准确地评估模型性能,从而做出更优的建模决策。