1. 概述
在本篇文章中,我们将深入探讨“数据湖”这一相对较新的概念。它融合了大数据技术的强大能力与自助式分析的灵活性。我们将重点介绍数据湖的核心组成部分与架构设计、它的优势与局限性,并对比其与数据仓库之间的主要差异。
2. 什么是数据湖?
数据湖是一个集中式存储库,可以以任意规模存储结构化、半结构化和非结构化数据。与传统存储方式不同的是,数据湖允许在数据尚未结构化的情况下进行存储。
数据湖支持多种分析方式,包括仪表盘展示、可视化、大数据处理、实时分析以及机器学习等,从而辅助企业做出更精准的决策。
✅ 优势:数据湖可以降低长期运营成本,同时提供经济高效的文件存储方式。
以下是数据湖的典型结构示意图:
3. 为什么需要数据湖?
数据湖的核心价值在于,它能够以原始格式存储海量数据,直到被分析应用使用为止。与传统的数据仓库不同,数据湖采用扁平化设计,通常以文件或对象形式存储数据,而不是按层级维度和表格结构来组织。
这为用户提供了更灵活的数据管理、存储和使用方式。
构建数据湖的一些关键考虑因素包括:
- 数据结构多样化,提升数据分析的深度和质量
- 无需预先定义企业级的统一模式(schema)
- 支持结构化向非结构化数据的转换,灵活性更高
- 可用于机器学习建模,如收入预测等
- 能为企业带来显著的竞争优势
4. 数据湖架构与核心组成部分
4.1 数据湖的核心组成
由于数据湖中数据量庞大,必须通过元数据标记来确保未来可以快速检索到目标数据。虽然不同数据湖的结构可能有所差异,但其核心目标始终是提升数据的可发现性和可用性。
一个健全的数据湖架构应具备以下关键特性:
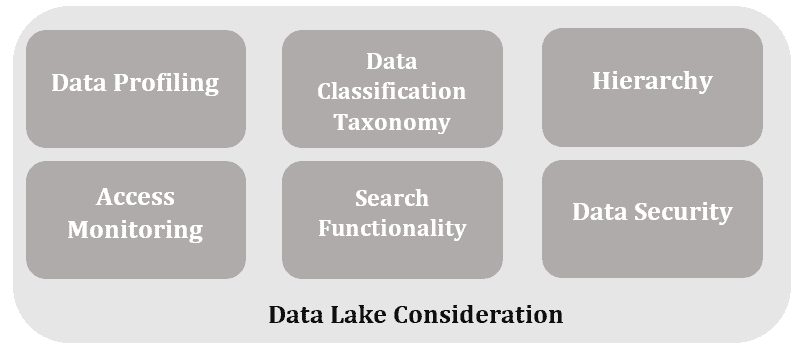
- 数据剖析(Data Profiling):评估数据质量和分类
- 数据分类(Data Taxonomy):描述数据类型、用户组和使用场景
- 层级结构(Hierarchy):组织文件并制定命名规范
- 访问监控(Access Monitoring):追踪用户访问行为,提供时间与地理位置相关的告警
- 搜索功能(Search Functionality):便于用户查找所需数据
- 数据安全(Data Security):包括加密、访问控制和身份认证等措施,防止未经授权的访问
4.2 数据湖的典型架构
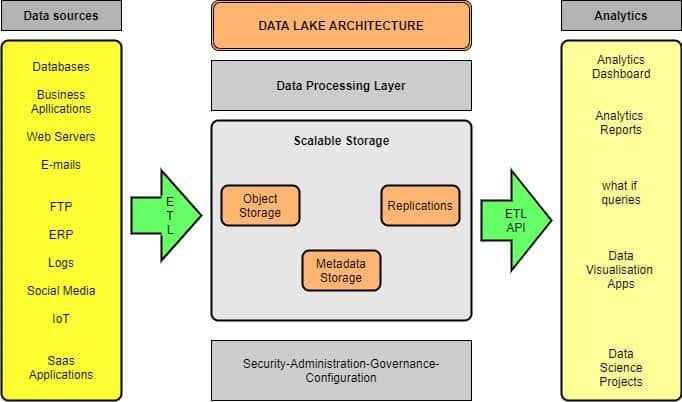
数据湖一般由两个核心部分组成:计算层(Compute) 和 存储层(Storage)。这两部分可以部署在云端,也可以部署在本地。
下图展示了一个典型的数据湖架构,包括数据源、处理层和分析层:
5. 数据湖 vs 数据仓库
数据湖和数据仓库的目标相似,都是为企业提供集中化的数据存储和分析能力。但它们在适用场景和实现方式上有显著差异:
| 特性 | 数据湖 | 数据仓库 |
|---|---|---|
| 可访问性与修改性 | 简单灵活,易于更新和调整 | 复杂且僵化,修改成本高 |
| Schema 模式 | Schema-on-read(读时模式) 无需预先定义结构 |
Schema-on-write(写时模式) 结构化且预定义 |
| 数据结构 | 原始数据 | 加工处理后的数据 |
| 主要用户 | 数据科学家、工程师 | 业务分析师、管理人员 |
| 分析类型 | 机器学习、深度学习、大数据分析、BI | BI、可视化、传统数据分析 |
6. 数据湖的优势与局限性
6.1 数据湖的优势
数据湖采用 Schema-on-read 的方式,意味着数据在写入时无需预先结构化。这种设计大大节省了数据预处理的时间,同时也支持多种格式的数据存储。
✅ 对数据科学家和分析师而言,数据湖提供了更灵活的分析能力,适用于如欺诈检测、情感分析、语音识别、定向广告等多种场景。
6.2 数据湖的局限性
❌ 数据湖存在一定的风险,尤其是在数据安全与访问控制方面。有时数据会被无监管地写入,可能涉及隐私或合规性问题。
❌ 另一个问题是缺乏对历史分析记录的管理,可能导致存储与计算成本上升。对于本地部署的数据湖,还需考虑硬件成本、空间限制、数据中心配置、存储扩展性以及资源预算等问题。
7. 总结
本文详细介绍了数据湖的概念、架构组成、优势与局限性,并与数据仓库进行了对比。
✅ 数据湖是一个能够存储结构化、半结构化和非结构化数据的集中式存储库,其核心目标是为数据科学家和分析师提供一个完整、原始的数据视图,从而支持更复杂、灵活的分析任务。
⚠️ 踩坑提醒:数据湖虽灵活,但若缺乏良好的治理和安全控制,很容易变成“数据沼泽(Data Swamp)”,建议在设计之初就规划好元数据管理、权限体系和数据生命周期策略。