1. 引言
在本篇文章中,我们将深入探讨决策树(Decision Tree)与随机森林(Random Forest)之间的区别。这两个模型在机器学习中都常用于分类和回归任务,但它们在结构、性能和适用场景上有显著不同。
如果你已经对机器学习有一定了解,那么本文将帮助你更深入地理解这两个模型之间的本质差异,以及在实际项目中如何选择合适的模型。
2. 决策树
决策树是一种以树形结构进行决策的模型。它通过一系列特征判断,最终得出一个离散或连续的输出结果。
举个例子,下面这棵树可以根据天气情况判断是否适合外出玩耍:
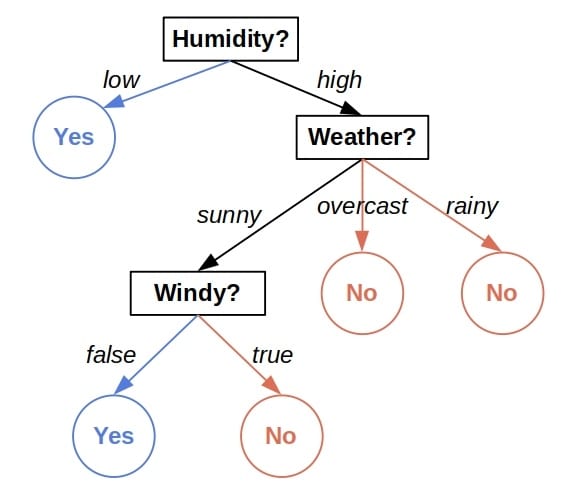
- 内部节点表示对某个特征的判断(如天气、湿度)
- 叶子节点表示最终的预测结果
工作原理简述:
每个叶子节点中都包含一部分训练数据。这些数据都满足从根节点到该叶子节点的所有判断条件。当我们要预测一个新样本时,我们根据它的特征路径走到对应的叶子节点,并使用该节点中训练样本的多数类(分类)或平均值(回归)作为预测结果。
2.1 决策树的两个主要问题
容易过拟合(Overfitting)
决策树在训练时倾向于尽可能多地分裂节点,以提高训练集的准确率。但这会导致模型过于复杂,学习到了训练数据中的噪声,从而在新数据上表现不佳。
✅ 解决方法:限制树的深度、设置最小样本数等剪枝策略。
不稳定性(Instability)
即使训练数据有微小变化(比如去掉几个样本),生成的决策树结构也可能完全不同。这使得模型缺乏一致性。
⚠️ 踩坑提醒:如果你在做模型解释或部署时依赖某棵特定结构的决策树,这种不稳定性会带来一定风险。
3. 随机森林
随机森林是一种集成学习(Ensemble Learning)方法,它通过构建多个决策树并将它们的预测结果进行整合,来提升模型的性能。
核心思想:
- 每棵树使用不同的训练子集和不同的特征子集构建
- 最终预测结果是所有树的投票(分类)或平均(回归)
优势:
- ✅ 抗过拟合能力强
- ✅ 模型更稳定
- ✅ 并行训练效率高
3.1 示例说明
假设我们有如下数据:
![[ \begin{matrix} \text{Weather} & \text{Humidity} & \text{Windy} & \text{PlayOutside} \\ \hline sunny & high & false & \textcolor{baeldungblue}{\text{Yes}} \\ sunny & low & false & \textcolor{baeldungblue}{\text{Yes}} \\ overcast & high & true & \textcolor{baeldungred}{\text{No}} \\ sunny & low & true & \textcolor{baeldungblue}{\text{Yes}} \\ overcast & low & false & \textcolor{baeldungblue}{\text{Yes}} \\ sunny & high & true & \textcolor{baeldungred}{\text{No}} \\ rainy & high & false & \textcolor{baeldungred}{\text{No}} \\ \hline \end{matrix}]](/wp-content/ql-cache/quicklatex.com-73424a049fcbacff7501ebe23e270930_l3.svg "Rendered by QuickLaTeX.com")
现在要预测以下情况是否适合外出:
![[\langle Windy = true, Humidity = low, Weather = sunny \rangle]](/wp-content/ql-cache/quicklatex.com-ddd3dab7abc5b32d2ecb65980feff97b_l3.svg "Rendered by QuickLaTeX.com")
我们使用三棵树组成的森林进行预测:
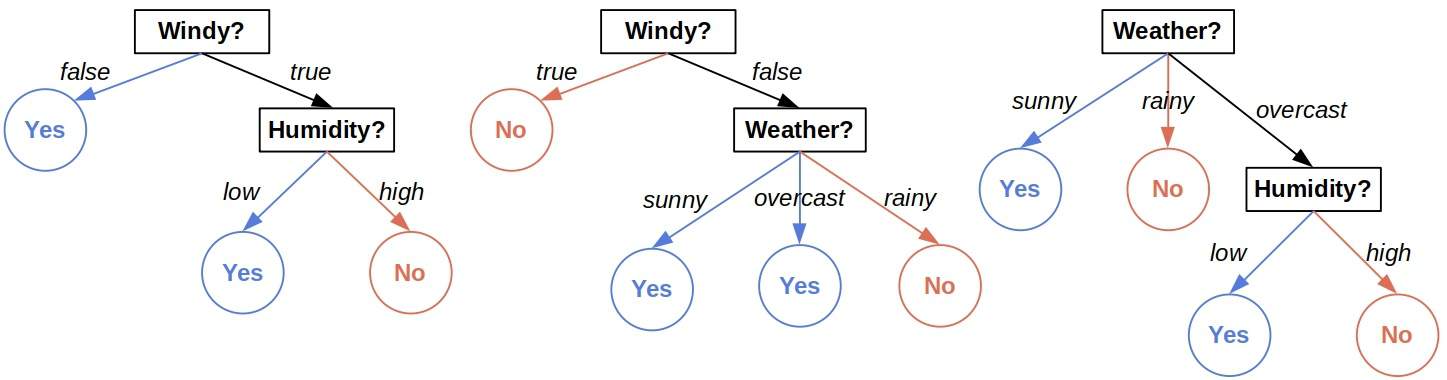
- 第一棵树预测:Yes ✅
- 第二棵树预测:No ❌
- 第三棵树预测:Yes ✅
最终预测结果:Yes(多数投票)
✅ 进阶技巧:也可以对每棵树的预测结果加权(根据树的准确率),提升整体效果。
3.2 随机森林的训练机制
- 每棵树独立训练,可以并行化处理,适合大规模计算
- 训练耗时约为单棵树的
m倍(m为树的数量) - 需要额外调整的超参数:
- 树的数量
m - 每次分裂时考虑的特征数量
- 树的数量
⚠️ 踩坑提醒:树的数量不是越多越好,过大会增加训练时间但提升有限。建议使用交叉验证来确定最佳值。
3.3 可解释性问题
虽然随机森林在性能上优于决策树,但它有一个显著缺点:难以解释。
- 决策树结构清晰,人类可以理解其判断逻辑
- 随机森林由多个树组成,整体决策过程复杂,难以可视化和解释
✅ 实际场景建议:
- 如果项目对模型解释性要求高(如医疗、金融),建议使用决策树
- 如果追求预测精度且无需解释,可使用随机森林
4. 总结
| 特性 | 决策树 | 随机森林 |
|---|---|---|
| 结构 | 单棵树 | 多棵树组合 |
| 易过拟合 | ✅ | ❌ |
| 不稳定性 | ✅ | ❌ |
| 可解释性 | ✅ | ❌ |
| 训练效率 | 高 | 中等(取决于树的数量) |
| 预测精度 | 一般 | 较高 |
✅ 一句话总结:
- 决策树适合需要解释性的场景
- 随机森林适合追求预测性能的场景
在实际项目中,根据业务需求选择合适模型是关键。希望这篇文章能帮你更清晰地理解两者之间的差异,并在实战中做出更明智的选择。