1. 简介
本文将介绍神经网络中 Epoch 的含义,探讨训练过程中 Epoch 数量与模型收敛之间的关系,并了解如何通过 Early Stopping 来提升模型的泛化能力。
2. 神经网络简介
神经网络是一种监督学习算法,广泛用于分类和回归任务。虽然它在许多场景中表现优异,但也有其优缺点(如过拟合风险、训练耗时等)。
构建神经网络时,需要考虑多个架构层面的问题,例如:
- 网络层数与神经元数量
- 输入特征的预处理(如归一化)
- 权重初始化方式
- 是否使用偏置项(Bias)
- 激活函数的选择
这些因素都会影响最终模型的性能和训练效率。
3. Epoch 的定义
一个 Epoch 表示将整个训练数据集完整地过一遍(forward pass + backward pass)的过程。
如下图所示,一个完整的 Epoch 包括一次前向传播和一次反向传播:
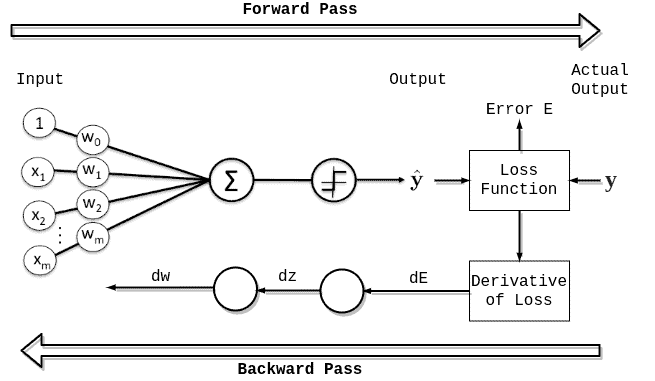
通常,一个 Epoch 会分成多个 Batch 来处理。每个 Batch 的处理称为一个 Iteration(迭代)。
举个例子:
- 假设训练数据有 1000 条
- Batch Size = 1000:一个 Epoch 只需 1 次 Iteration
- Batch Size = 500:一个 Epoch 需要 2 次 Iteration
- Batch Size = 100:一个 Epoch 需要 10 次 Iteration
所以,Epoch 数量 × Iteration 数量 × Batch Size = 总共训练的数据量。
⚠️ 注意:Epoch 和 Iteration 容易混淆,一定要区分开。Epoch 是“遍历整个数据集的次数”,Iteration 是“每次处理一个 Batch 的次数”。
4. Epoch 与模型训练的收敛性
在训练神经网络时,我们希望模型能收敛到一个稳定状态,既不过拟合(Overfitting),也不欠拟合(Underfitting)。
4.1 模型收敛的判断标准
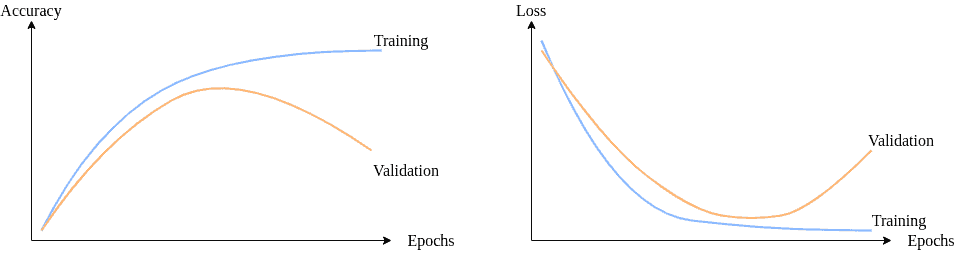
通常我们会通过绘制 Loss / Accuracy 曲线 来观察模型是否收敛:
- 训练初期:Loss 下降,Accuracy 上升
- 收敛阶段:Loss 和 Accuracy 趋于稳定
- 过拟合阶段:Validation Loss 开始上升,而 Training Loss 仍在下降
下图展示了典型的训练曲线:
为了更好地判断模型是否收敛,通常将数据划分为:
- 训练集(Training Set)
- 验证集(Validation Set)
这样我们可以分别绘制两者的 Loss 曲线,从而判断是否过拟合或欠拟合。
4.2 Epoch 数量的选择
设置 Epoch 数量是一个超参数,需要根据模型结构和数据集大小进行调整。
- Epoch 数量太少:模型欠拟合
- Epoch 数量太多:模型过拟合 + 浪费资源
4.3 Early Stopping 技术
Early Stopping 是一种正则化手段,其核心思想是:在验证集上的误差开始上升时提前停止训练。
使用方法如下:
- 设置一个较大的 Epoch 数量(比如 1000)
- 每个 Epoch 结束后评估验证集 Loss
- 如果验证 Loss 在连续几个 Epoch 中没有下降,则停止训练
✅ 优点:
- 避免过拟合
- 节省训练时间
❌ 缺点:
- 需要设置合适的“耐心值(Patience)”
- 验证集 Loss 可能波动,误判停止时机
5. 总结
- Epoch 是指整个训练集被完整使用一次的过程
- 一个 Epoch 可以包含多个 Batch,每个 Batch 的处理称为一个 Iteration
- Epoch 数量影响模型是否收敛,太少会欠拟合,太多会过拟合
- 通过观察 Loss / Accuracy 曲线,可以判断模型是否收敛
- 使用 Early Stopping 是防止过拟合的有效手段,推荐在训练中使用
合理设置 Epoch 数量 + 使用 Early Stopping = 更高效、更泛化的模型训练方式 ✅