1. 概述
在深度学习中,Epoch、Batch 和 Mini-Batch 是三个基础概念,理解它们之间的区别对于训练模型至关重要。本文将从梯度下降算法出发,逐步讲解这三个术语的定义及其差异,并通过一个具体示例帮助加深理解。
2. 梯度下降算法
要理解 Epoch、Batch 和 Mini-Batch,首先得了解 梯度下降(Gradient Descent) 这一优化算法。它是深度学习模型训练的核心机制。
梯度下降的基本流程如下:
- ✅ 计算目标函数(通常是损失函数)对参数的一阶导数(即梯度);
- ✅ 沿梯度的反方向更新参数,以逐步逼近最小值。
在神经网络中,我们会将训练数据输入网络,计算损失函数的梯度并更新网络参数。
根据每次迭代中使用的训练数据量,梯度下降可以分为以下三种类型:
2.1 Batch Gradient Descent(批量梯度下降)
- ✅ 使用整个训练集进行一次参数更新。
- ✅ 计算准确但效率低,尤其在数据量大时。
示意图如下: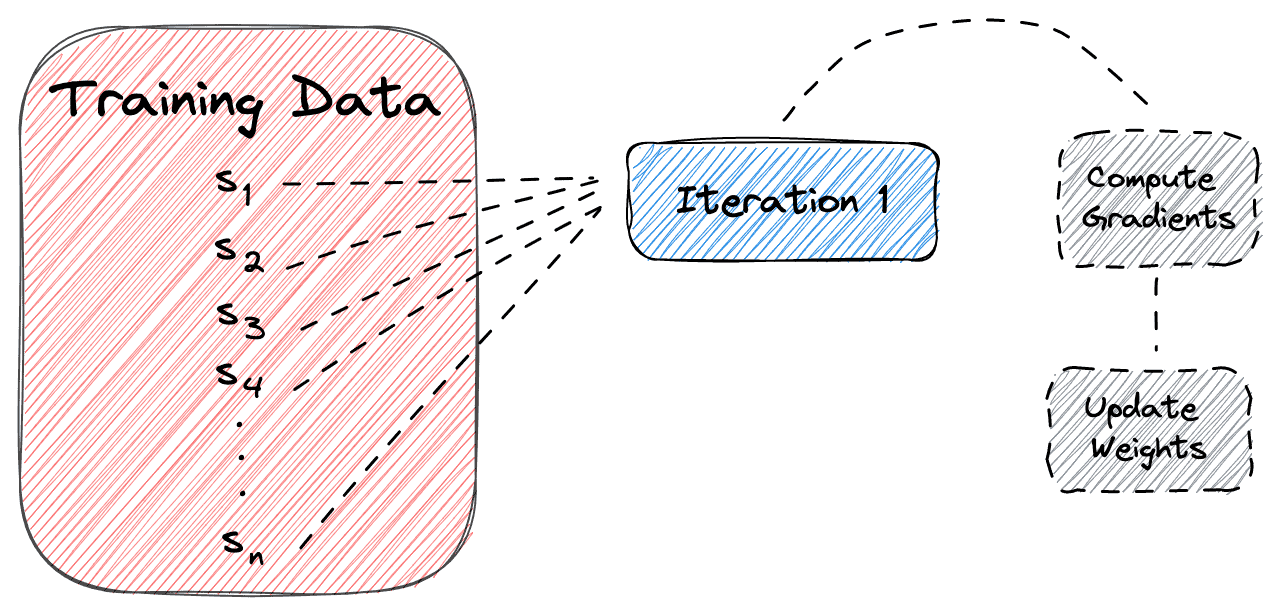
2.2 Stochastic Gradient Descent(随机梯度下降)
- ✅ 每次只使用一个样本进行参数更新。
- ✅ 更新速度快,但损失函数波动大,收敛不稳定。
示意图如下: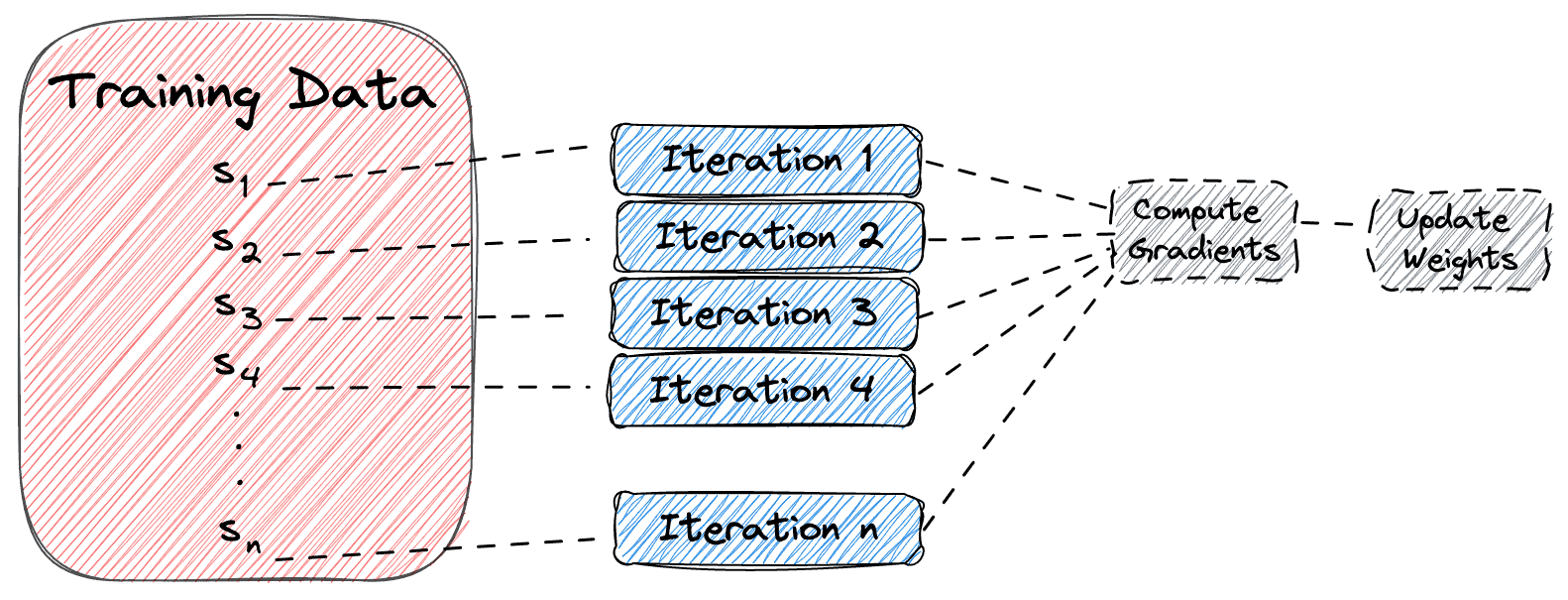
2.3 Mini-Batch Gradient Descent(小批量梯度下降)
- ✅ 使用一小批样本(mini-batch)进行一次更新。
- ✅ 平衡了前两者,兼顾速度和稳定性。
- ✅ 是目前深度学习中最常用的训练方式。
示意图如下(mini-batch size = 2):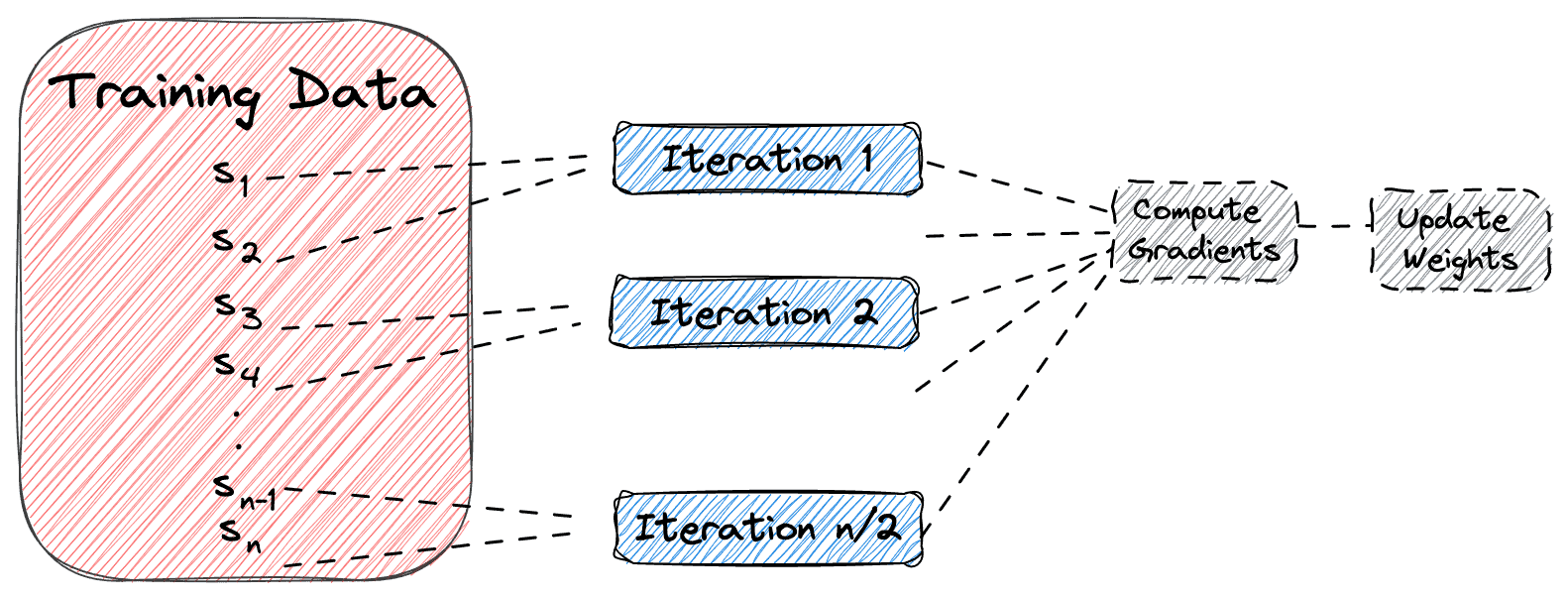
3. Epoch、Batch 与 Mini-Batch 的定义
✅ Epoch
- 一个 Epoch 表示整个训练集被完整使用一次来更新网络参数。
- Epoch 是一个超参数,控制训练的轮数。
✅ Batch
- 在 Batch Gradient Descent 中,Batch 表示的就是整个训练集。
- 一次更新使用全部数据。
✅ Mini-Batch
- 在 Mini-Batch Gradient Descent 中,Mini-Batch 是每次训练中使用的数据子集。
- 每个 Mini-Batch 的大小(batch size)是一个超参数。
⚠️ 三者关系总结
| 方法 | 每次更新使用的样本数 | 一个 Epoch 对应的更新次数 |
|---|---|---|
| Batch GD | 全部数据(n) | 1 次 |
| Stochastic GD | 1 个样本 | n 次 |
| Mini-Batch GD | b 个样本(b < n) | n / b 次 |
4. 示例说明
假设我们有:
- ✅ 数据集大小:n = 2000
- ✅ 训练轮数(Epoch)= 10
- ✅ Mini-Batch 大小:b = 4
那么:
- ✅ Batch GD:总共更新 10 次(每个 Epoch 1 次)
- ✅ Stochastic GD:总共更新 2000 × 10 = 20000 次(每个 Epoch 2000 次)
- ✅ Mini-Batch GD:总共更新 (2000 / 4) × 10 = 5000 次(每个 Epoch 500 次)
这个例子清晰地展示了三种方法在参数更新频率上的差异。
5. 总结
本文详细介绍了 Epoch、Batch 和 Mini-Batch 三者之间的区别:
- ✅ Epoch 是训练轮数的单位;
- ✅ Batch 是 Batch GD 中使用的全部训练数据;
- ✅ Mini-Batch 是 Mini-Batch GD 中每次训练使用的数据子集;
- ✅ Mini-Batch GD 是目前最常用的方法,兼顾训练速度和稳定性。
理解这些概念有助于我们更好地配置训练参数、优化模型性能,也能帮助我们更准确地解读训练过程中的日志和指标。希望这篇文章对你在深度学习训练中有所帮助!