1. 引言
在面对传统编程难以解决的问题时,我们通常会借助机器学习(Machine Learning, ML)算法。这些问题往往难以用数学公式明确描述,例如判断一封邮件是否为垃圾邮件。
随着机器学习领域的快速发展,我们有必要了解其基本分类,尤其是数据在模型中是如何被使用、模型又是如何从数据中“学习”的。如果你计划从事相关工作或开发项目,掌握这些基础分类是非常有必要的。
本文将通过一些实际案例,帮助你更好地理解监督学习(Supervised Learning)与无监督学习(Unsupervised Learning)之间的区别和应用场景。
2. 基本概念
监督学习的目标是训练一个模型,使其能够将输入映射到输出,并具备泛化能力,正确分类未见过的数据。
举个简单的例子:你有一组不同品种的狗的图片,目标是让模型正确识别每张图片中的狗属于哪个品种。输入是狗的图像(X),输出是品种标签(Y):

在这个过程中,有“监督者”提供正确的标签,我们可以据此评估模型表现。
无监督学习则没有输出标签。我们只有输入数据,任务是发现数据中的潜在模式或结构。
比如你在一家服装公司工作,拥有客户的历史数据:消费金额、年龄、购买日期等。你的任务是找出这些数据之间的潜在关系,帮助公司制定营销策略,明确应重点关注哪些客户群体以提升利润。
在这种情况下,输出不是标签,而是对客户的分组。模型会根据数据特征进行聚类:

3. 监督学习
监督学习主要分为两类任务:回归(Regression) 和 分类(Classification)。虽然应用场景不同,但它们的共同点是:训练过程中都有明确的标签(Ground Truth)作为反馈。
3.1 回归问题
当模型的输出是一个数值时,我们称之为回归问题。
举个例子:假设我们有一个汽车数据集,输入是车辆的各种属性(如制造年份、品牌、里程、发动机功率等),输出是车辆价格。如果我们只考虑制造年份这一个特征,那么模型可以表示为:
(1)
$$ y = wx + w_0 $$
其中,w 和 w₀ 是模型需要学习的参数。我们可以将数据点绘制在二维图中,然后拟合出一条直线来预测价格:
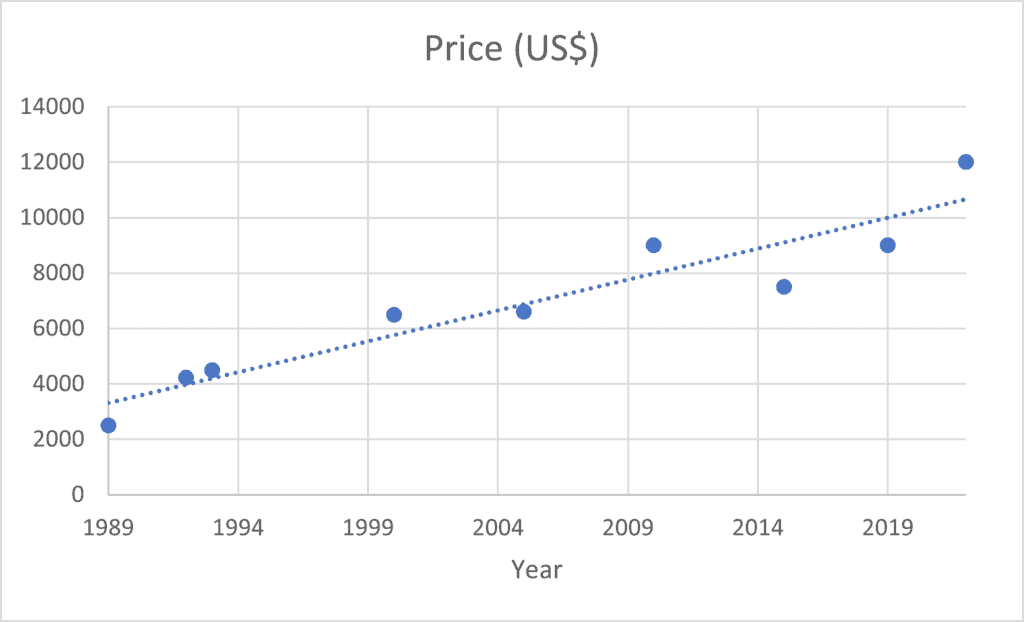
当然,仅用线性模型可能无法很好捕捉复杂关系。我们可以使用高阶多项式或非线性函数来提高模型的泛化能力。
另一个实际应用是:一家冰淇淋公司通过分析气温与销量的关系,优化生产计划。这帮助他们避免了生产过多或过少的问题。
3.2 分类问题
当输出是一个类别标签时,这就是分类问题。
比如,我们想训练一个模型来识别狗的品种。模型会学习不同品种狗的特征,并为每张图片分配一个类别标签。如果模型足够鲁棒,它就能识别训练集中未出现过的狗的品种。
分类问题的关键在于找到一个决策边界,将不同类别的样本区分开:

4. 无监督学习
当没有标签可供参考时,我们就需要依赖无监督学习来发现数据中的潜在结构。常见的无监督学习方法包括:
4.1 聚类(Clustering)
聚类的目标是将未分类的数据分成若干自然形成的组。
比如,K-Means 是一种常见的聚类算法。它的基本流程如下:
✅ 随机初始化 K 个聚类中心
✅ 将每个样本分配到最近的聚类中心
✅ 重新计算聚类中心为该类样本的均值
✅ 重复上述步骤,直到聚类中心不再变化或达到最大迭代次数
下图展示了 K-Means 的迭代过程:
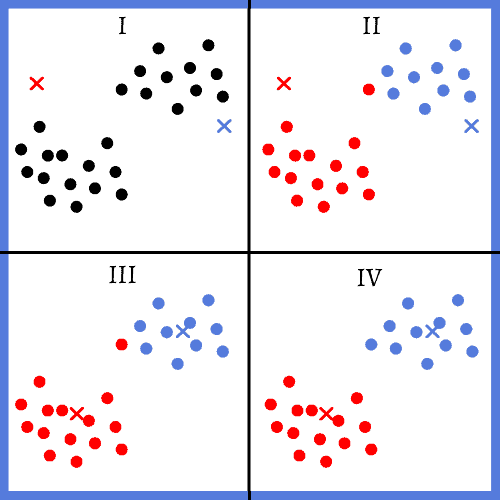
应用场景包括客户分群、电影推荐系统的用户分组等。
4.2 关联分析(Association)
关联分析用于发现数据中特征之间的强相关性。
最经典的例子是购物篮分析(Basket Analysis):找出购买了商品 X 的用户是否也倾向于购买商品 Y。
我们常用两个指标来衡量关联规则的强度:
支持度(Support):X 和 Y 同时出现的概率
$$ Support(X,Y) = \frac{#{客户同时购买 X 和 Y}}{#{所有客户}} $$置信度(Confidence):在购买 X 的前提下,购买 Y 的概率
$$ Confidence(X \rightarrow Y) = \frac{Support(X,Y)}{Support(X)} $$
例如,我们可以分析用户在流媒体平台上的观看记录,找出观看某部剧集的用户是否也倾向于观看某类电影,从而优化推荐系统。
5. 总结
监督学习与无监督学习的关键区别在于:是否拥有标签数据。监督学习适用于输出明确(如分类或数值预测)的问题;无监督学习则适用于探索数据结构、发现隐藏模式的场景。
选择哪种方法,取决于你的数据是否有标签、你的业务目标是预测还是发现,以及你希望模型如何“学习”。
✅ 监督学习:有标签,适合预测任务(分类、回归)
✅ 无监督学习:无标签,适合探索性任务(聚类、关联分析)
理解这些区别,有助于你在实际项目中做出更合理的技术选型。