1. 简介
在机器学习模型评估中,我们常用多个指标来衡量分类器性能。其中,F1 Score 是 Precision 与 Recall 的调和平均值,常用于综合评估模型的准确性。
但在某些场景中,Precision 与 Recall 的重要性并不对等。例如在医学诊断中,漏诊(False Negative)可能比误诊(False Positive)更严重;而在垃圾邮件检测中,误判正常邮件为垃圾邮件的代价可能更高。
F-Beta Score 正是为了应对这种非对称需求而提出的,它允许我们通过参数 β 来调整 Recall 与 Precision 的权重。
2. F1 Score 简要回顾
F1 Score 是 Precision(P)与 Recall(R)的调和平均:
$$ F_1 = \frac{2PR}{P+R} $$
它适用于 Precision 与 Recall 同等重要的场景。F1 Score 的等高线图如下:
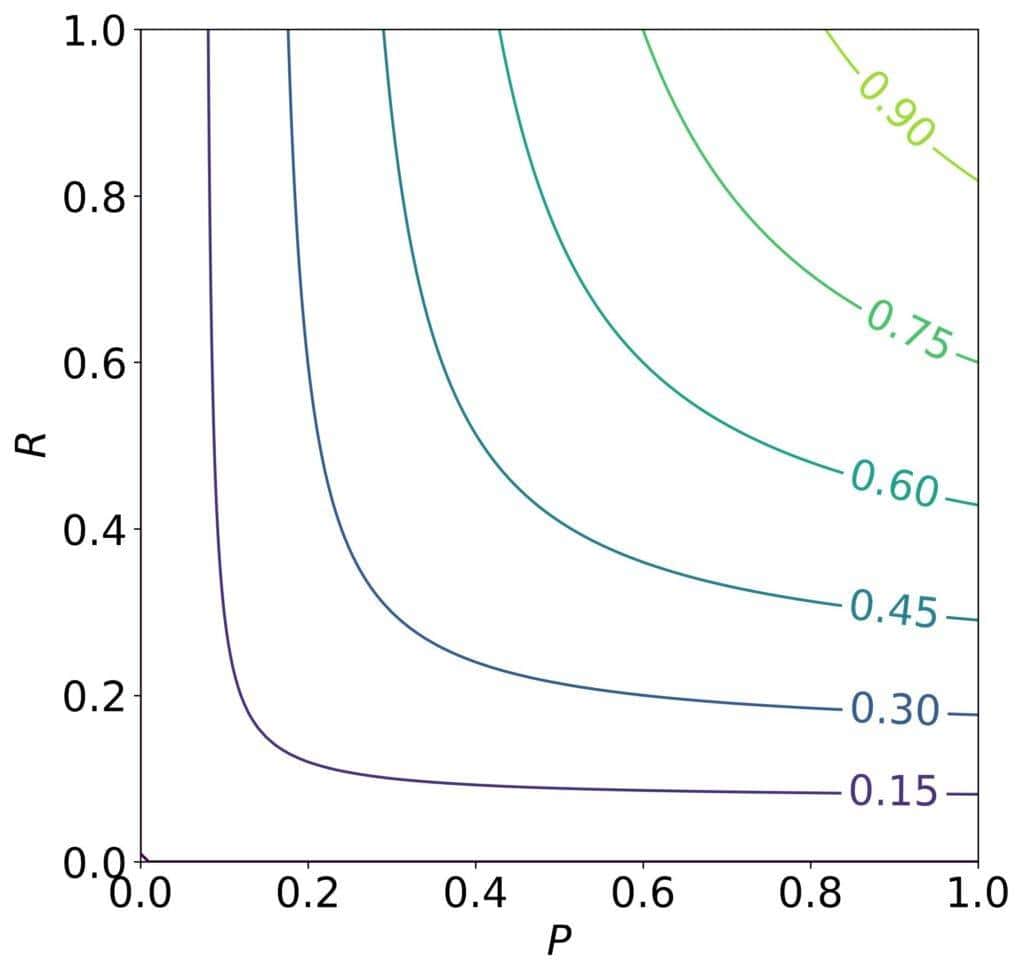
图像对称,表明 Precision 与 Recall 权重一致。
2.1. 当 Precision 与 Recall 不等价时怎么办?
- Recall 更重要:当 False Negative 代价更高时(如医学诊断),我们更关注 Recall。
- Precision 更重要:当 False Positive 代价更高时(如垃圾邮件识别),我们更关注 Precision。
此时,F-Beta Score 就派上用场了。
3. F-Beta Score 的定义
F-Beta Score 的标准形式如下:
$$ F_{\beta} = (1 + \beta^2) \cdot \frac{PR}{\beta^2 P + R} $$
它是一种加权调和平均。权重分别为:
$$ \frac{1}{\beta^2 + 1} \quad \text{和} \quad \frac{\beta^2}{\beta^2 + 1} $$
因此:
$$ F_{\beta} = \frac{1}{\frac{1}{\beta^2 + 1} \cdot \frac{1}{P} + \frac{\beta^2}{\beta^2 + 1} \cdot \frac{1}{R}} $$
- 当 β > 1:Recall 被赋予更高权重(权重是 β 倍 Precision)。
- 当 β < 1:Precision 被赋予更高权重。
- 当 β = 1:即为 F1 Score。
示例:β = 10 时的 F-Beta Score 图形
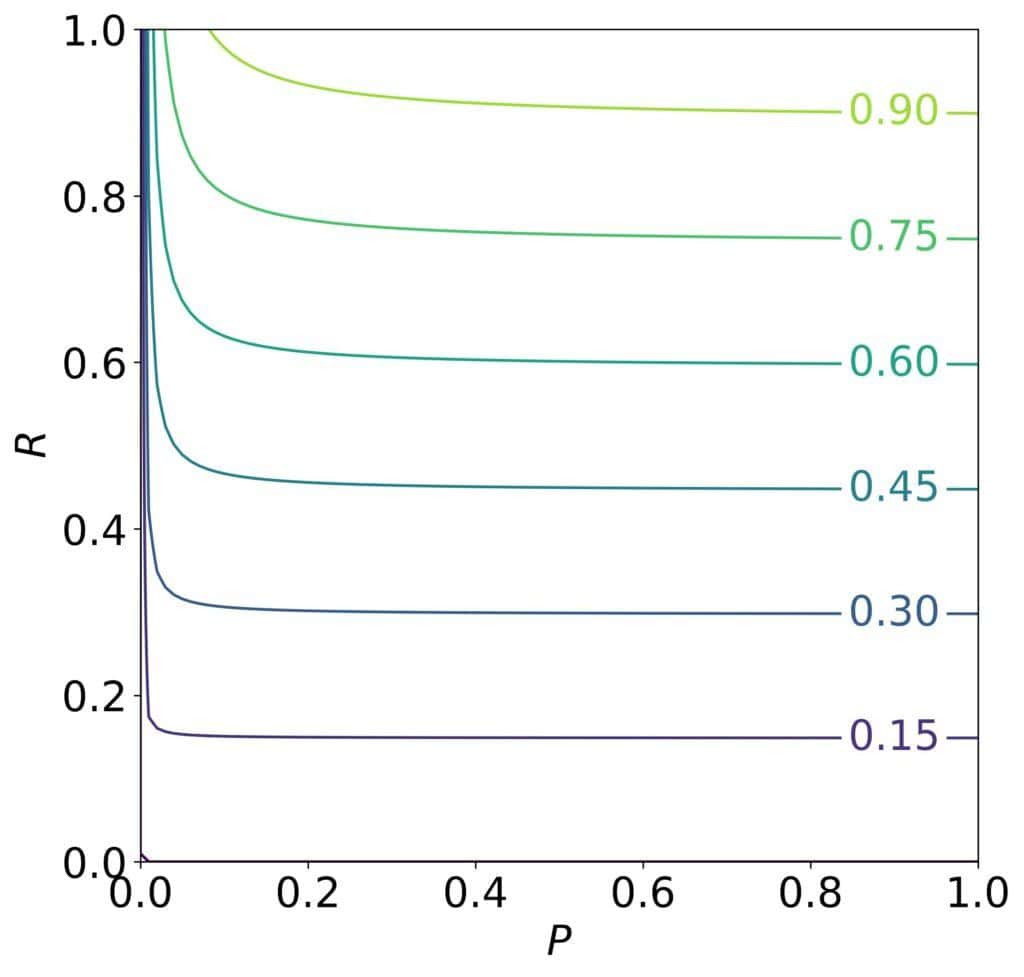
可以看出,Recall 很高时,即使 Precision 不高,F-Beta Score 也可以很高。
为什么是 β² 而不是 β?
这个设计源于 F-Beta Score 的原始定义:当 Precision 与 Recall 的偏导数相等时,Recall 应为 Precision 的 β 倍。
通过数学推导得出,权重中必须使用 β² 才能满足这个条件。
4. F-Beta Score 的其他定义方式
除了上述定义,还有一种不同的加权方式:
$$ \tilde{F}_{\beta} = (1 + \beta) \cdot \frac{PR}{\beta P + R} $$
在这种定义下,当 Precision 与 Recall 相等时,Recall 的提升对 F-Beta Score 的影响是 Precision 的 β 倍。
两种定义在 β = 1 时都等于 F1 Score,但在其它 β 值下结果不同。
5. 总结
| 要点 | 内容 |
|---|---|
| ✅ 用途 | 在 Precision 与 Recall 权重不等时评估分类器性能 |
| ✅ β 的意义 | β > 1 时强调 Recall,β < 1 时强调 Precision |
| ✅ 数学基础 | β² 的使用是基于偏导数相等时 Recall 为 Precision 的 β 倍这一条件 |
| ⚠️ 注意 | 不同的 F-Beta 定义方式在 β ≠ 1 时结果不同,使用时需确认定义来源 |
应用场景举例
- ✅ 医疗诊断:优先提高 Recall,避免漏诊
- ✅ 邮件分类:优先提高 Precision,避免误删重要邮件
F-Beta Score 提供了比 F1 更灵活的评估方式,适用于实际业务中 Precision 与 Recall 不对等的场景。