1. 概述
在监督学习(supervised learning)任务中,特征(feature)与标签(label)是两个非常基础但又至关重要的概念。本文将详细讲解它们的定义、区别,以及如何正确使用它们。
我们会从统计学角度理解“特征”的含义,分析其常见类型,并探讨“标签”在机器学习中的角色,以及它们如何影响模型的输出和预测能力。最后,我们还会强调一个常见误区:不要将标签当作特征来使用。
2. 特征(Feature)
特征是观测或测量的结果。它们是数据集中用于描述每个样本(observation)的属性(attribute)。
2.1 特征作为测量结果
我们可以将特征理解为传感器或测量工具的结果。例如:
- 一个温度计每隔15分钟记录一次气温,它记录的“温度”就是一个特征;
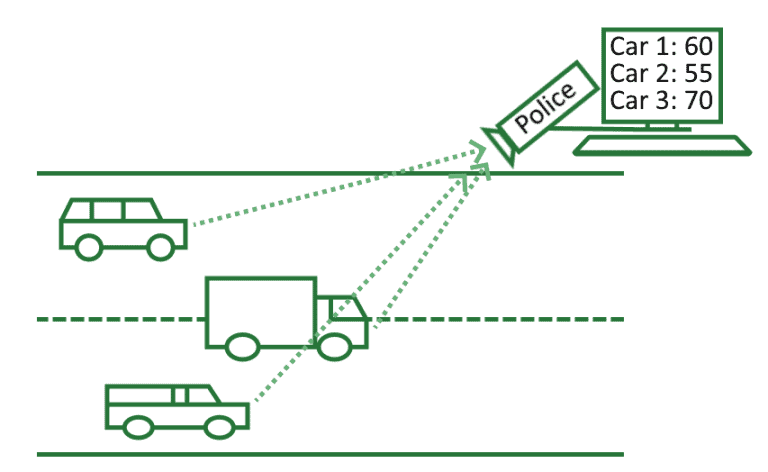
- 警察使用的雷达测速仪记录车辆速度,速度值就是特征;
- 邮件服务器记录每封邮件的文本内容,这些文本可以被处理为特征。
以下是一个测温仪记录温度的示意图:
再比如,测速雷达记录车辆速度:
在这些例子中,测量值(温度、速度、文本)构成了数据集的特征。
2.2 任务类型与特征识别
特征的选择往往取决于我们的研究目标。比如在雷达测速的例子中,车牌号通常作为索引(index),而速度是特征。但在某些任务中,车牌号本身也可以作为特征,比如我们想分析哪些车牌频繁出现在某条道路上。
这说明:特征的定义是主观的,取决于任务目标和我们对问题的理解。
2.3 特征的常见类型
常见的特征类型包括:
✅ 数值型(Numerical)
- 整数(int)、浮点数(float)、双精度浮点数(double)
- 适用于线性回归、K-Means 等算法
✅ 文本型(Textual)
- 字符串(string)
- 用于自然语言处理(NLP),但需要经过预处理(如分词、向量化)
✅ 类别型(Categorical)
- 名义类别(Nominal):无顺序,如颜色(红、绿、蓝)
- 有序类别(Ordinal):有顺序,如学历(高中、本科、硕士)
2.4 数值型特征
数值型特征是最常见、最直观的特征类型。例如:
double temperature = 25.3;
int speed = 60;
这类特征可以直接用于机器学习模型,如线性回归、K-Means 等。
以下是一个线性回归示意图:
2.5 文本作为特征?
文本通常不能直接作为特征使用,需要进行预处理:
- 分词(Tokenization)
- 词干提取(Stemming) / 词形还原(Lemmatization)
- 向量化(Vectorization)
例如,原始文本:
"The pen is on the table"
预处理后可能变为:
["pen", "table", "on"]
未经处理的文本信息密度低,直接使用会导致维度爆炸和模型性能下降。
2.6 类别型特征
类别型特征分为两种:
✅ 名义类别(Nominal):
- 无内在顺序,如颜色、性别、品牌
- 示例:苹果颜色(红、绿、黄)
✅ 有序类别(Ordinal):
- 有内在顺序,如学历、评分等级
- 示例:教育程度(高中、本科、硕士、博士)
⚠️ 注意:类别型特征通常需要进行编码(如 One-Hot 编码、Label 编码)才能输入模型。
3. 标签(Label)
标签是监督学习中的输出变量。它是我们希望模型预测的目标。
3.1 标签作为目标变量
在监督学习中,特征是输入,标签是输出。例如:
| 特征 | 标签 |
|---|---|
| 温度、湿度 | 是否下雨 |
| 用户年龄、浏览记录 | 是否购买商品 |
我们可以构建一个函数:label = f(features)
例如,预测股票组合价格:
| 股票1 | 股票2 | 股票3 | 组合价格 |
|---|---|---|---|
| -1.2 | 0.5 | 0.2 | -230 |
| 0.3 | -0.26 | 0.6 | -86 |
我们可以将前三列作为特征,最后一列作为标签进行建模。
3.2 标签作为贝叶斯先验
标签的选取也反映了我们对问题的先验知识。例如,在自动驾驶的目标识别任务中:
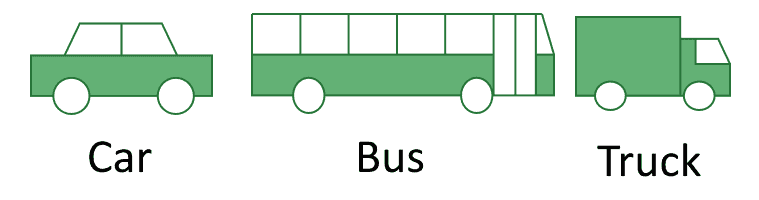
我们预设标签集合为 {car, bus, truck},这意味着我们假设所有目标都属于这三个类别。这种预设会限制模型的识别能力,比如它无法识别下图中的自行车:
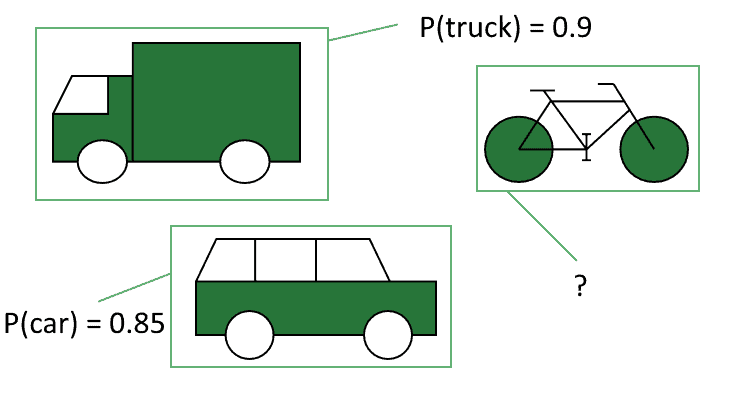
因此,标签不仅是输出变量,更是我们对世界认知的压缩表示。
4. 总结
本文我们介绍了:
✅ 特征的定义与常见类型
✅ 标签的作用与选取原则
✅ 特征与标签之间的主观性与关联性
✅ 标签选择对模型性能的深远影响
📌 核心要点:
- 特征是观测或测量结果
- 标签是我们希望预测的目标
- 特征与标签的划分取决于任务目标和先验知识
- 标签选择体现了模型的偏见(bias)
避免将标签当作特征使用,是构建高质量模型的关键之一。同时,理解标签背后的先验假设,有助于我们更好地设计模型并提升其泛化能力。