1. 概述
本文将介绍文件结构的基本概念,帮助理解文件在磁盘上的组织方式。我们将先简要介绍文件结构的设计背景,然后介绍几种常见的文件结构类型。
2. 引言
尽管磁盘访问速度比内存慢,但它提供了更大的存储容量,且具备非易失性,即使断电后数据也不会丢失。文件结构设计的核心驱动力正是磁盘的慢速访问和大容量非易失特性。
在深入细节之前,我们先来区分一下数据结构与文件结构这两个概念:
- 数据结构:处理的是主存中的数据;
- 文件结构:处理的是像硬盘这样的二级存储设备中的数据。
两者都涉及数据的表示方式和访问机制,因此在文献中容易混淆。但可以明确的是,内存访问技术的发展直接影响了文件结构的研究方向。
3. 文件结构
文件结构是文件中数据表示方式和访问操作的组合。 它允许应用程序进行数据的读取、写入和修改操作,甚至能支持按条件查找数据。一个高效的文件结构可以让应用程序的性能提升数百倍。
文件结构设计的主要目标是:最小化访问磁盘的次数。 理想情况下,我们希望在一次磁盘访问中就能获取所需信息,或者尽可能少地进行磁盘读取。
✅ 一个良好的文件结构应具备以下特点:
- 快速访问海量数据
- 减少磁盘访问次数
- 支持数据集合的扩展(通过拆分等方式)
当文件内容不变时,设计满足上述目标的文件结构相对容易。但一旦文件频繁变更、增长或缩减,设计出具备上述特性的结构就变得复杂得多。
3.1. 文件结构发展简史
20世纪50年代,大多数文件都存储在磁带上,只能进行顺序访问,访问成本与文件大小成正比。随着文件体积增大和硬盘等存储设备的普及,索引机制被引入文件系统。 这些索引保存了键值和指针,使得查找速度大幅提升。
不过,这些索引仍然存在部分顺序访问的问题,管理起来也较为困难。
到了60年代初期,研究人员开始尝试将树结构应用于文件系统。然而,树结构在记录频繁增删的情况下容易失衡,导致查找效率下降。
3.2. AVL树
研究人员继续优化树结构,最终提出了AVL树,这是一种自平衡的二叉搜索树,非常适合内存中的数据组织。随后,文件系统研究者也开始尝试将其应用于文件结构中。
3.3. B树与B+树
经过十年的设计演进,最终提出了B树。虽然B树性能优秀,但它在顺序访问方面效率不高。为了解决这个问题,研究人员引入了链表结构,从而诞生了B+树。
下图展示了B树与B+树的主要区别:
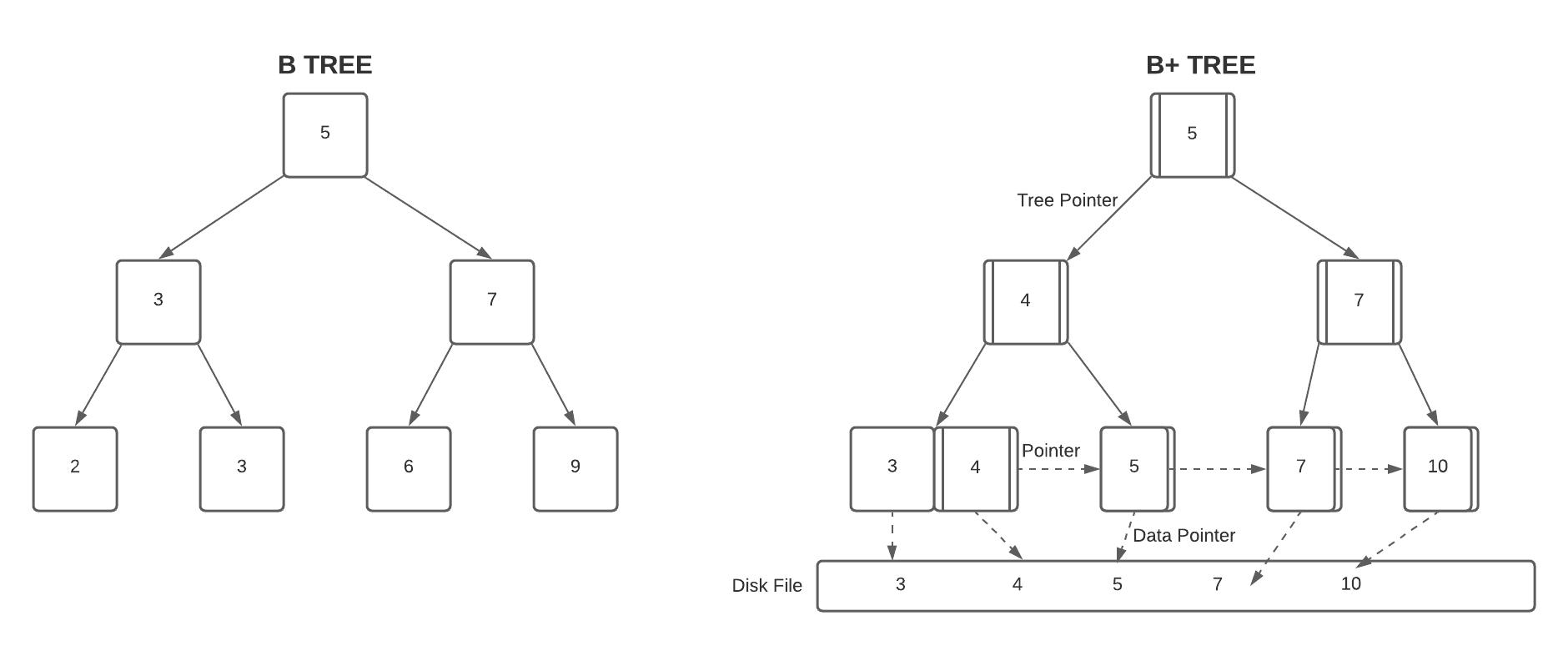
多年来,B树和B+树已成为许多文件系统的标准结构,因为它们的访问时间与  成正比,其中:
成正比,其中:
- N 是文件中的条目数
- k 是单个B树块中索引的条目数
这意味着在实际应用中,即使面对数百万个文件,我们通常也只需3到4次磁盘访问即可定位目标文件。
3.4. 哈希(Hashing)
三次或四次磁盘访问已经非常高效了,但还有更优的方案:一次访问就获取所需数据。
哈希技术就是实现单次访问的核心机制。 当文件大小固定时,线性哈希表现良好。但面对动态变化的文件,传统哈希效率较低。研究人员通过引入动态哈希解决了这一问题,无论文件多大,都能通过一次访问获取数据。
下图展示了哈希机制的工作原理:
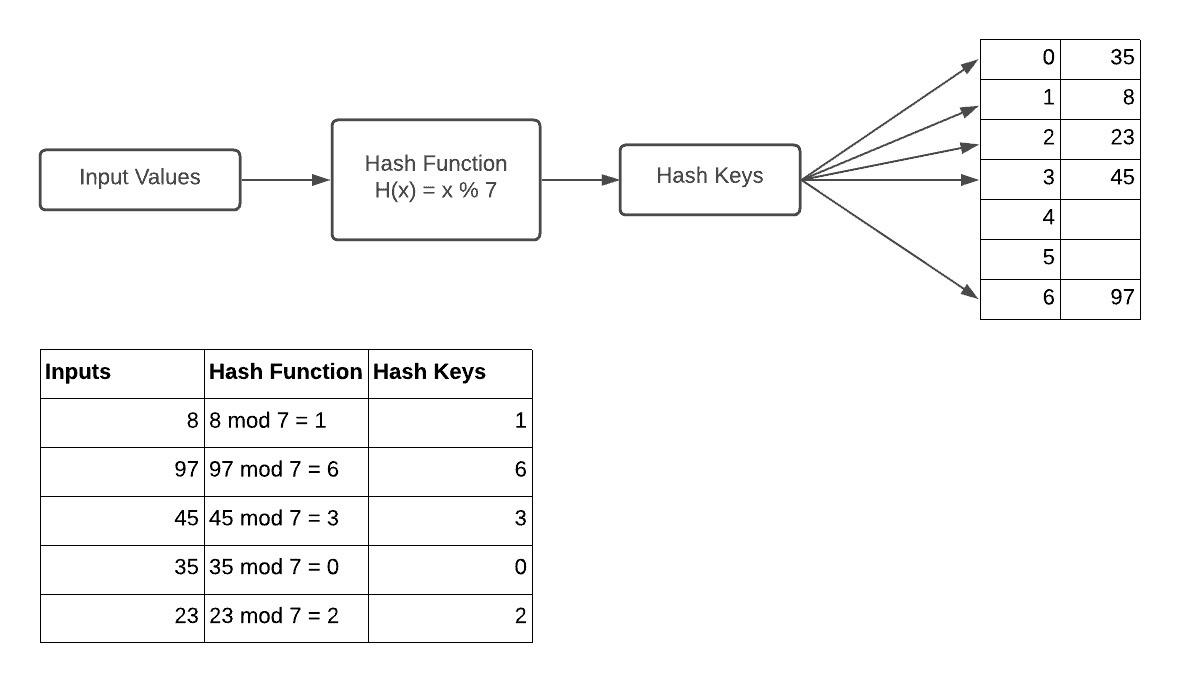
如图所示,哈希是一种将任意输入转换为固定长度输出的算法过程。其核心思想是使用一个哈希函数,将输入转换为一个较小的数值,并用这个数值作为索引,在一个称为哈希表的数据结构中进行查找。
4. 总结
本文简要介绍了文件结构的基本概念,明确了数据结构与文件结构之间的区别。
同时,我们还介绍了几种常见的文件结构类型,包括:
- AVL树:适用于内存中自平衡查找
- B树与B+树:适用于磁盘文件系统的高效索引结构
- 哈希结构:支持单次访问的高效数据定位机制
这些结构在文件系统和数据库系统中广泛应用,是提升系统性能的关键因素之一。