1. 引言
如今,一些卷积神经网络(CNN)架构,如 GPipe,参数量高达 5.57 亿。在我们日常使用的普通计算机上,训练这样的模型在计算资源上几乎不可行。
本文将介绍“微调(Fine-tuning)”,这是一种解决该问题的常用策略。
2. 什么是微调?
在深入细节之前,先来了解我们为何需要微调,以及它的定义。
2.1. 背景动机
假设我们要训练一个模型,用于检测人体细胞中的癌症。为了获得较好的效果,我们决定使用一个大型的深度神经网络架构。
假设我们的训练数据集只有 1000 个样本,但我们手头已经有一个在 20 万个组织图像上训练好的模型,这个模型结构复杂、层数和神经元都很多。
与其从头开始训练一个新模型,不如复用已有模型。我们可以在新数据上继续训练,但将初始权重设为组织分类模型的权重。 这就是微调的一个典型应用场景。
如果不采用这种方式,初始权重将是随机的。在这种情况下,复杂的网络结构将需要大量时间进行反向传播(Backpropagation)训练。
此外,如果我们在小数据集上直接使用一个非常深的网络,且没有像上面那样的智能初始化策略,模型很容易出现过拟合(Overfitting)。
2.2. 定义
简而言之,微调是指使用一个已经训练好的网络的权重作为新网络训练的初始值:
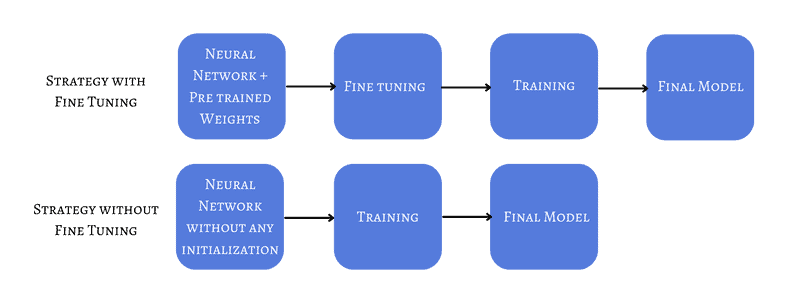
目前的最佳实践建议:使用在大规模数据集上预训练的模型来解决与当前任务相似的问题。这在我们当前任务数据量少,但有相关问题的丰富数据时特别有用。
当然,如果微调策略选择不当,也可能导致过拟合等问题。
3. 微调策略
我们将介绍两种常见的微调策略,实际中通常会结合使用。
3.1. 冻结层(Freezing Layers)
最常见的方法是冻结部分网络层。 这是什么意思?
我们可以直接加载预训练模型的权重,并对所有层进行训练。但在很多情况下,我们只希望微调部分层,而保持其它层不变。
冻结部分层的依据是:早期层通常学习的是通用特征(如边缘、纹理等),这些特征在很多任务中是通用的。因此,我们可以冻结这些层,只训练后面的层。
- ✅ 可冻结前几层,训练后面的层
- ✅ 如果输出类别数不同,需修改最后一层
- ✅ 可在原模型基础上添加新的层,仅训练新增层
3.2. 示例
假设我们有两个任务:
- 第一个任务是使用大量数据训练的模型,用于分类车辆:汽车、摩托车、自行车
- 第二个任务是我们自己的任务:使用少量数据分类汽车品牌(如 35 个品牌)
此时,我们可以冻结前几层(比如 $h_1$ 和 $h_2$),只训练后续层:
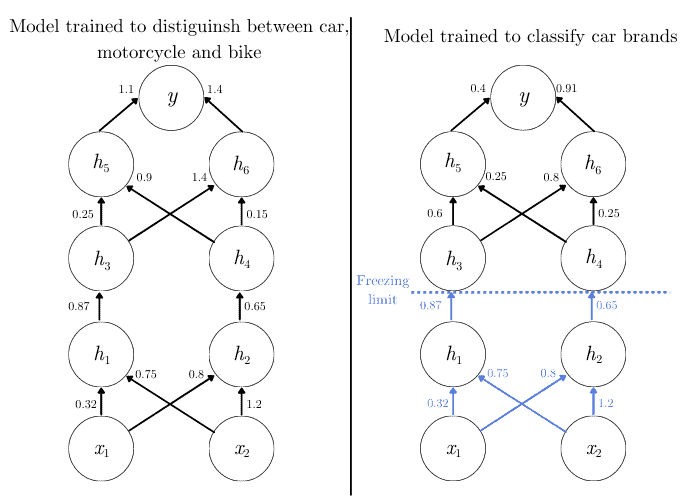
这样,我们保留了模型对通用特征的学习能力,同时让后续层专注于特定任务的学习。
⚠️ 注意:最后一层输出维度需要根据新任务进行调整。例如,原来输出 3 个类别,现在需要输出 35 个品牌。
3.3. 调整学习率(Learning Rate)
微调的一个隐含前提是:新旧数据集的分布不能相差太大。
因此,我们不希望模型权重发生剧烈变化。这意味着我们需要设置一个较小的学习率。
- ✅ 推荐使用比常规训练小 10 倍的学习率
- ✅ 例如:原学习率为 0.01,微调时可设为 0.001
举个例子:
- 原模型用于区分猫狗,学习率为 0.01
- 现在我们要微调模型用于识别猫的品种,可将学习率设为 0.001
这样可以让模型在原有知识的基础上,以更小的步长适应新任务,避免破坏已学到的特征。
4. 微调的局限性
虽然微调有很多优势,但它并不是万能的解决方案。
4.1. 领域相似性要求高
微调的前提是源任务和目标任务之间有较高的相似性。如果两者差异较大,微调反而可能带来负面影响。
4.2. 架构修改受限
如果我们希望对网络结构进行较大改动(如替换某些层),则微调可能不再适用,因为原有权重无法直接复用。
4.3. 参数设置不当可能影响效果
错误的微调策略(如冻结了不该冻结的层、学习率设置不当)可能导致模型陷入局部最优,甚至完全无法收敛。
✅ 如果我们拥有足够多的数据,从头训练(Training from Scratch)可能是一个更稳妥的选择。
5. 总结
本文介绍了神经网络中的微调技术:
- ✅ 微调能显著减少训练时间
- ✅ 利用已有模型的特征提取能力,提升小数据集下的模型性能
- ✅ 避免过拟合,提高泛化能力
- ❌ 但也存在领域匹配、学习率设置、层冻结策略等关键挑战
建议: 在数据量有限、任务相似度高、已有预训练模型可用时,优先考虑微调。但在数据量充足、任务差异大或需要大幅修改网络结构时,应谨慎使用微调。