1. 引言
在计算机科学中,优化算法种类繁多,模糊搜索(Fuzzy Search)算法是其中一种用于近似字符串匹配(Approximate String Matching)的技术。
在本教程中,我们将探讨模糊匹配的含义和作用,然后介绍几种常见的模糊匹配算法及其应用场景。
最后,我们会选择一个具体示例来演示如何通过算法解决近似字符串匹配问题。
2. 什么是模糊匹配?
模糊匹配(Fuzzy Matching)也被称为近似字符串匹配(Approximate String Matching),是计算机科学中一个备受关注的问题。
它是一种增强型文本识别技术,能够在两个字符串不完全一致的情况下,判断它们是否“近似”相似。
换句话说,当数据库中没有精确匹配的字符串时,模糊匹配方法可以尝试找到一个相似度超过预设阈值的匹配结果。
3. 模糊匹配的应用场景
模糊匹配广泛应用于多个领域,例如:
- 拼写纠错:处理用户因打字错误、快速输入或拼写习惯不同而产生的不一致
- 语音识别:基于发音或语音特征的匹配
- 生物信息学:匹配DNA序列等生物数据
- 垃圾邮件过滤:识别变体拼写的垃圾邮件关键词
- 数据清洗与去重:在不同来源的数据中识别重复或相似记录
4. 常见的模糊匹配算法
以下是一些常用的模糊匹配算法:
4.1. 暴力匹配算法(Naive Algorithm)
暴力匹配算法是最基础的模式查找算法。它没有预处理步骤,直接对主字符串中的每个位置进行模式匹配检查。
✅ 优点:实现简单
❌ 缺点:效率较低,时间复杂度为 O(n * m)
4.2. 汉明距离算法(Hamming Distance)
汉明距离用于衡量两个等长字符串之间的差异,即在相同位置上字符不同的个数。
例如:
abc与abd的 Hamming Distance 为 1abc与def的 Hamming Distance 为 3
⚠️ 注意:仅适用于等长字符串
4.3. 编辑距离算法(Levenshtein Distance)
Levenshtein 距离衡量两个字符串之间的最小编辑操作次数(插入、删除、替换)。
例如:
"test"与"tent"的 Levenshtein Distance 为 1(只需替换一个字符)"kitten"与"sitting"的 Levenshtein Distance 为 3
这是模糊匹配中最常用的距离算法之一。
4.4. N-Gram 算法
N-Gram 是一种将文本切分为连续 n 个词或字符的模型。它常用于文本分类、语音识别、拼写纠错等领域。
例如,对于字符串 "hello",其 2-Gram 表示为:["he", "el", "ll", "lo"]
✅ 优点:适合处理拼写错误和语音识别
❌ 缺点:占用内存较大
4.5. BK 树算法(BK Tree)
BK 树是一种专为离散度量空间设计的树结构,常用于构建模糊搜索的索引结构。
它通过预计算字符串之间的编辑距离,构建一个树形结构,便于快速查找与目标字符串近似的候选项。
✅ 优点:适合大规模模糊搜索
❌ 缺点:实现复杂,构建成本高
4.6. Bitap 算法
Bitap 算法是一种基于位操作的模糊字符串匹配算法,它利用位运算快速判断一个字符串是否与目标字符串在编辑距离 k 内相似。
✅ 优点:效率极高,适合短模式匹配
❌ 缺点:只适用于小范围编辑距离
5. 模糊匹配算法示例:暴力匹配算法
我们以暴力匹配算法为例,来演示如何实现模糊匹配。
5.1. 算法逻辑
该算法通过逐个比较主字符串中所有可能的起始位置,来查找模式字符串的匹配。
伪代码如下:
algorithm NaiveStringMatcher(t, p):
// INPUT
// t = the text to search within
// p = the pattern to search for
// OUTPUT
// Prints the positions where the pattern occurs in the text
n <- t.length
m <- p.length
for s <- 0 to n - m:
if p[1 : m] = t[s + 1 : s + m]:
print "Pattern occurs with shift" s
5.2. 示例说明
我们定义如下:
主字符串 T(长度为6):

模式字符串 P(长度为3):

匹配过程如下:
起始位置 0:
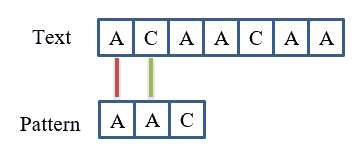
- 第一个字符匹配:
P[0] == T[0] - 第二个字符不匹配:
P[1] ≠ T[1]
- 第一个字符匹配:
起始位置 1:
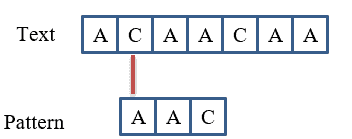
P[0] ≠ T[1],跳过
起始位置 2:
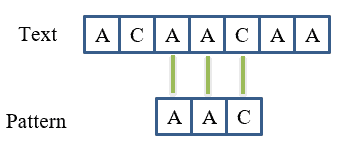
P[0] == T[2]P[1] == T[3]P[2] == T[4]✅ 匹配成功
起始位置 3:
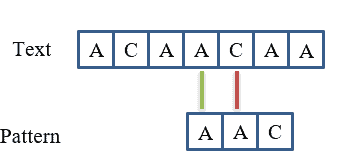
P[0] == T[3]P[1] ≠ T[4]❌ 匹配失败
最终,模式字符串 P 在主字符串 T 中的匹配位置为索引 2。
6. 总结
本文介绍了模糊匹配的基本概念及其常见应用场景,并列举了多种模糊匹配算法。
我们以暴力匹配算法为例,展示了其在近似字符串匹配中的实现逻辑和具体应用。
虽然暴力匹配算法效率不高,但它的实现简单,在某些特定场景下仍然具有实用价值。
如需处理大规模数据或追求高性能,建议结合其他优化算法如 Bitap、BK 树等来提升模糊匹配效率。