1. 概述
Google 的“Did You Mean?”功能在用户搜索时非常实用。当用户输入拼写错误的关键词时,Google 会自动提示“Did you mean: xxx”,帮助用户找到他们真正想搜索的内容。
本文将深入探讨这个算法的实现机制。我们会从用户视角出发,分析其行为数据,进而构建一个基于用户历史行为的拼写纠错模型。最后我们会理解 Google 是如何利用大规模用户数据来训练这个模型的。
2. 我们知道你想查什么
2.1 用户看到的是什么?
当用户在 Google 中输入一个拼写错误的词时,Google 通常不会直接返回该错误拼写的结果,而是尝试猜测用户的真实意图,并返回更可能相关的结果。
例如,用户输入 “baledung”,Google 会自动将其替换为 “balinese”:
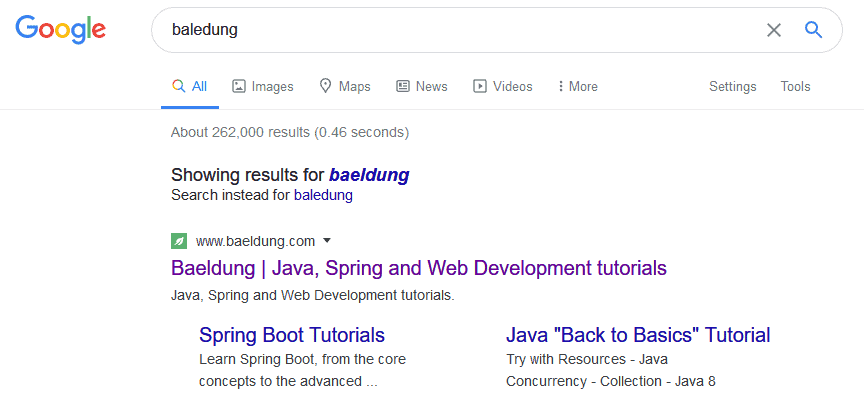
如果错误比较严重,Google 会明确提示建议拼写,并给出原始查询结果:
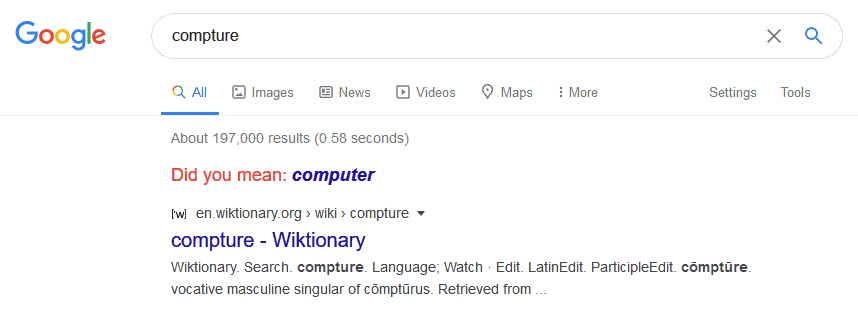
✅ 这种机制背后是一个基于概率的拼写纠错系统。
2.2 初步黑盒分析
我们可以将“Did You Mean?”算法看作一个黑盒系统,通过输入输出关系来推测其工作原理。
实验表明,Google 会根据输入的拼写错误词,找出最可能的正确拼写,并返回对应的结果。如果错误轻微,它直接返回修正后的内容;如果错误较严重,它会返回原始搜索结果,并附带建议拼写。
⚠️ 这说明 Google 的系统并不是简单地查词典,而是基于某种概率模型来预测用户意图。
3. 通过聚合行为预测用户意图
3.1 问题规模
如果我们想手动建立一个拼写纠错表,那将是极其庞大的。例如:
| 用户输入 | 最可能的词 | 次可能的词 | 不太可能的词 |
|---|---|---|---|
| absense | absence | adsense | absinthe |
| cheif | chief | chef | chaff |
| sieze | seize | sieve | cease |
| wether | weather | whether | wetter |
英文单词数量超过 50 万,加上各种拼写变体,手工维护几乎不可能。因此必须依赖自动化方法。
3.2 利用用户行为
我们可以通过观察用户行为来训练纠错模型。比如:
- 用户输入一个错误拼写
- 没有找到想要的结果
- 修改关键词后最终找到了目标内容
我们可以通过分析这些关键词序列,构建一个“用户拼写路径”模型。
3.3 识别用户成功与失败
我们可以通过以下流程建模用户行为:
- 用户首次输入查询词
- 如果找到目标内容,点击链接并结束搜索
- 否则修改查询词,重复搜索
✅ 这个模型的关键在于:我们可以通过用户点击行为来判断搜索是否成功。
在 Web 环境下,我们可以通过 Cookie 或 Session 来追踪用户的搜索历史:
3.4 你其实不是这个意思
通过聚合所有用户的搜索路径,我们可以统计出哪些初始查询最终导向了相同的正确关键词。
例如:
baledung → balinese
baledung → bali
baledung → bali hotel
如果大多数用户最终都搜索到了 “bali”,那么当新的用户输入 “baledung” 时,系统就可以推荐 “Did you mean: bali”。
✅ 用户输入路径越一致,纠错准确率越高。
4. 总结
Google 的“Did You Mean?”功能并非基于静态词典,而是通过大规模用户行为数据训练出的拼写纠错模型。
核心思想是:
- 通过 Cookie 或 Session 跟踪用户搜索路径
- 统计用户从错误拼写到正确拼写的转化路径
- 建立概率模型预测用户真实意图
这种做法的优势在于:
- 自动化程度高,无需人工标注
- 随着用户行为积累,纠错效果不断提升
- 可以适应新词、流行词等动态变化
💡 踩坑提醒:如果你自己实现类似功能,请务必注意用户隐私合规问题,不能直接记录用户搜索词和行为路径,应做匿名化处理。