1. 引言
在本文中,我们将深入探讨 梯度提升树(Gradient Boosting Trees) 和 随机森林(Random Forests) 之间的核心区别。两者都属于决策树集成模型,但它们在训练方式和集成策略上存在显著差异。
在进入正题之前,我们先简要回顾一下决策树的基本概念。
2. 决策树
决策树是一种基于特征进行逐层判断以做出预测的树形结构。 它的每个节点代表一个特征判断,叶子节点则代表最终的预测结果。例如,下面是一个判断某天是否适合外出的决策树示例:
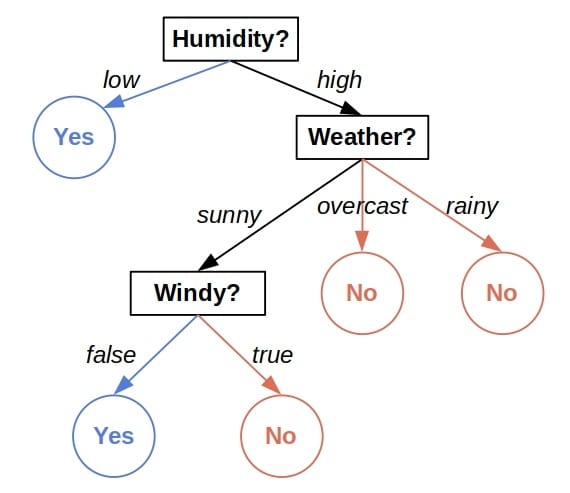
每个内部节点检查一个特征,并根据特征值决定进入哪个子树。叶子节点包含通过该路径的所有训练样本,并输出该样本的多数类别(分类任务)或平均值(回归任务)。
⚠️ 但决策树存在两个主要问题:
- 不稳定性:训练数据的微小变化可能导致生成完全不同的树。
- 泛化能力有限:在某些数据集上,单棵决策树的表现可能不如其他模型。
因此,我们引入了集成学习来提升其性能和稳定性。
3. 随机森林
随机森林是由多个决策树组成的集合模型,每棵树独立训练,且使用的是不同的数据子集和特征子集。 其核心思想是:
✅ 虽然单棵树可能不准确,但多棵树的集体判断往往更可靠。
举个例子,假设我们有一个训练集  ,包含 200 个样本和 4 个特征 A、B、C、D。我们训练每棵树时会:
,包含 200 个样本和 4 个特征 A、B、C、D。我们训练每棵树时会:
- 从 中随机抽取一个样本子集

- 随机选择部分特征(例如 A 和 C)
- 用这些数据和特征训练一棵树
重复这个过程,直到训练出足够数量的树。
3.1. 优缺点分析
| 优点 | 缺点 |
|---|---|
| ✅ 比单棵树更稳定、更准确 | ❌ 可解释性差(多路径决策) |
| ✅ 可并行训练(每棵树互不依赖) | ❌ 训练耗时(树数量多) |
4. 梯度提升树
梯度提升树是当前最流行、效果最稳定的集成学习方法之一。与随机森林不同,它通过逐层训练决策树来逐步修正误差。
我们以一个回归问题为例,数据如下:
$$ \begin{matrix} x & y \ \hline x_1 & 10 \ x_2 & 11 \ x_3 & 13 \ x_4 & 20 \ x_5 & 22 \end{matrix} $$
目标是通过多棵树逐步逼近真实值。
4.1. 第一棵树的训练
我们先训练第一棵树 $ f_1 $,使用全部数据和特征,然后计算预测值与真实值的残差:
$$ \begin{matrix} x & y & f_1(x) & y - f_1(x) \ \hline x_1 & 10 & 9 & 1\ x_2 & 11 & 13 & -2\ x_3 & 13 & 15 & -2\ x_4 & 20 & 25 & -5\ x_5 & 22 & 31 & -9 \end{matrix} $$
4.2. 第二棵树的训练
接着,我们训练第二棵树 $ f_2 $,目标是拟合第一棵树的残差。如果 $ f_2 $ 能准确预测残差,那么:
$$ f_1(x) + f_2(x) \approx y $$
更新后的新残差为:
$$ \begin{matrix} x & y & f_1(x) & f_2(x) & y - f_1(x) - f_2(x)\ \hline x_1 & 10 & 9 & 0.5 & 0.5\ x_2 & 11 & 13 & 1 & -3\ x_3 & 13 & 15 & -1 & -1\ x_4 & 20 & 25 & -2 & -3\ x_5 & 22 & 31 & -4 & -5 \end{matrix} $$
如果残差仍较大,继续训练 $ f_3 $,依此类推,直到误差收敛或达到预设的最大树数。
4.3. 优缺点分析
| 优点 | 缺点 |
|---|---|
| ✅ 准确率高(逐步修正误差) | ❌ 易过拟合(尤其在噪声多的数据上) |
| ✅ 可建模复杂模式 | ❌ 训练慢(必须串行) |
4.4. 与随机森林的核心区别
| 对比维度 | 随机森林 | 梯度提升树 |
|---|---|---|
| 训练方式 | ✅ 并行 | ❌ 串行 |
| 集成方式 | ✅ 多数投票 / 平均 | ✅ 残差修正 |
| 可解释性 | ❌ 较差 | ❌ 更差 |
| 对噪声敏感度 | ✅ 相对稳健 | ❌ 容易过拟合 |
4.5. “梯度”从何而来?
虽然前面我们用的是残差,但“梯度提升”这个名字来源于损失函数的负梯度方向。
以平方损失函数为例:
$$ J = \frac{1}{2} \sum_{i=1}^{n} (y_i - f(x_i))^2 $$
其梯度为:
$$ \frac{\partial J}{\partial f(x_i)} = f(x_i) - y_i $$
这其实就是残差的负值。如果我们用下式更新预测值:
$$ f(x_i) \leftarrow f(x_i) - \rho \cdot \frac{\partial J}{\partial f(x_i)} $$
这就是梯度下降法。在梯度提升中,我们每训练一棵树 $ f_2 $,其实就是在做一次梯度下降更新。
⚠️ 注意:当使用其他损失函数时,我们不再拟合残差,而是拟合负梯度。这也是“梯度提升”这一名称的由来。
5. 总结
| 维度 | 随机森林 | 梯度提升树 |
|---|---|---|
| 训练方式 | 并行 | 串行 |
| 集成方式 | 投票 / 平均 | 残差修正 |
| 适用场景 | 快速建模、稳定性要求高 | 高精度需求、可接受较长训练时间 |
| 抗过拟合能力 | 较强 | 需调参控制 |
✅ 选择建议:
- 如果你追求快速训练、模型稳定性强,选 随机森林
- 如果你追求高精度、能接受较长训练时间,选 梯度提升树
两者各有千秋,实际应用中应根据数据特性和业务需求灵活选择。