1. 概述
在本教程中,我们将探讨有向图与无向图之间的区别,并学习在什么情况下更适合使用其中一种图结构。
我们会从图论的基本概念出发,逐步分析它们在建模实际关系时的适用性,并引入图的熵(entropy)这一信息论概念,帮助我们从信息量角度理解两种图结构的本质差异。
2. 图、边与关系
2.1. 图还是网络?
程序员经常提到“网络”这个词,但当话题转向“图”时,常常会混淆两者。实际上,在图论中,图(Graph)是网络的数学抽象,而网络是图在现实世界中的体现。
例如,我们可以将互联网或局域网建模为一个网络:每个节点是一台计算机,每条边表示它们之间的连接。这类网络具有涌现性(Emergent Behavior),即整体行为不能简单归结为个体行为的总和。
在图论中,这些概念被形式化为:
| 网络理论 | 图论 |
|---|---|
| 网络 | 图 |
| 节点 | 顶点 |
| 连接 | 边 |
这种术语对应关系贯穿全文,请牢记。
2.2. 图在信息论中的意义
图不仅是计算机科学中重要的数据结构,还能帮助我们研究对象之间的关系而不仅仅是对象本身。典型应用场景包括:
- 知识表示
- 符号推理
- 多智能体仿真
- 动态系统建模
此外,图在信息论中也有深入研究,尤其是图的熵,它是衡量图结构复杂性的重要指标。
2.3. 图与熵
图的熵通常通过邻接矩阵(Adjacency Matrix)来定义。邻接矩阵是一个 N×N 的矩阵,其中:
- 每一行表示边的起点(tail)
- 每一列表示边的终点(head)
邻接矩阵的元素为 0 或 1,表示是否存在从 i 到 j 的边。
我们可以通过以下步骤计算图的熵:
- 将邻接矩阵展平(flatten)为一个随机变量 x
- 使用香农熵公式计算:
$$ H(x) = -\sum_{i=1}^{N^2} {p(x_i) \cdot \log(p(x_i))} $$
图的熵越高,说明图结构越复杂、不确定性越大。这也是我们不能将有向图和无向图等同视之的根本原因。
3. 有向图
3.1. 有向图的定义
有向图(Directed Graph)中的边具有方向性,不保证对称性。也就是说,如果顶点 a 到 b 有边,不代表 b 到 a 也一定有边。
边的方向通常用箭头表示,起点为箭尾,终点为箭头。
✅ 有向图是最通用的图结构,因为它不要求边的对称性。
3.2. 常见应用场景
有向图非常适合建模方向性明确、非对称的关系。例如:
- 家谱树(Genealogical Tree):一个人可以是某个关系中的父母,也可以是另一个关系中的子女,但不能同时互为父母与子女
- 网页链接:A 页面可以链接到 B 页面,但 B 页面不一定反向链接 A 页面
图示如下:
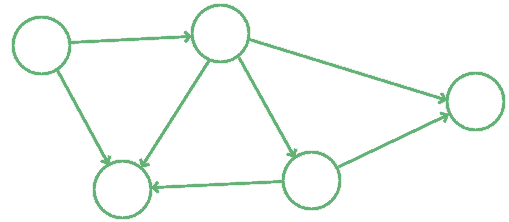
4. 无向图
4.1. 无向图的定义
无向图(Undirected Graph)要求边具有对称性。如果顶点 a 和 b 之间有边,则 a 到 b 和 b 到 a 都存在边。
这相当于说:无向图的邻接矩阵是对称的。
✅ 无向图更适用于建模双向、对称的关系。例如:
- 朋友关系:“A 是 B 的朋友”意味着“B 也是 A 的朋友”
- 局域网连接:设备 A 与设备 B 连接,意味着 B 也连接 A
图示如下:
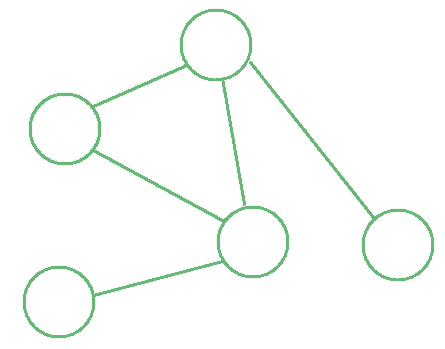
4.2. 常见应用场景
无向图广泛应用于以下场景:
- 计算机网络拓扑:设备之间是双向连接的
- 社交网络:好友关系是双向的
- 行人路径网络:两个交叉口之间可以双向通行
图示如下:

4.3. 对称的有向图就是无向图
我们可以通过邻接矩阵是否对称来判断一个图是否是无向图:
✅ 一个图是无向图当且仅当其邻接矩阵沿主对角线对称。
这为我们提供了一个从有向图推导出对应无向图的方法,也让我们可以进行信息论上的比较。
⚠️ 但要注意:一个无向图可能对应多个不同的有向图。
图示如下:

5. 有向图与无向图的熵比较
5.1. 比较的前提条件
为了比较有向图与无向图的熵,我们假设两者具有相同的顶点集合,但边可能不同。
- 有向图 D:边数为 e
- 对应的无向图 U:边数在 e(D 是对称的)到 2e(D 中无反向边)之间变化
这为我们提供了一个统一的比较基础。
5.2. 熵的计算与比较
设:
- D 的邻接矩阵对应的随机变量为 d
- U 的邻接矩阵对应的随机变量为 u
香农熵公式如下:
$$ H(d) = - \left( \frac{e}{N^2} \cdot \log \left( \frac{e}{N^2} \right) + \left(1 - \frac{e}{N^2} \right) \cdot \log \left(1 - \frac{e}{N^2} \right) \right) $$
对于无向图:
- 若 D 对称:H(u) = H(d)
- 若 D 中无反向边:H(u) =
$$ H(u) = - \left( \frac{2e}{N^2} \cdot \log \left( \frac{2e}{N^2} \right) + \left(1 - \frac{2e}{N^2} \right) \cdot \log \left(1 - \frac{2e}{N^2} \right) \right) $$
下图展示了 N = 10 时,H(d) 与 H(u) 的对比:
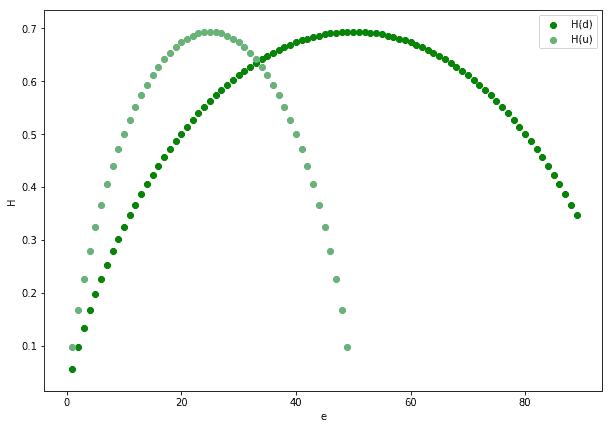
结论是:**除了极少数情况外,H(d) ≠ H(u)**。这说明我们不能随意将有向图当作无向图处理,否则会损失信息。
6. 如何选择使用哪种图结构?
选择图结构时,应根据实际关系的性质来决定:
✅ 使用有向图的情况:
- 关系具有方向性且非对称(如“是某人的孩子”)
- 网络稀疏,信息损失大(如网页链接)
✅ 使用无向图的情况:
- 关系对称且双向(如“是朋友”)
- 不需要区分主客体(如社交网络、局域网连接)
✅ 同一系统可以建模为两种图的情况:
- 家庭关系:研究血缘时用有向图,研究家族归属时用无向图
7. 总结
- 有向图边具有方向性,适合建模非对称关系
- 无向图边是对称的,适合建模双向关系
- 两者在信息论上具有本质差异,不能随意互换
- 选择图结构应根据建模对象的性质决定
⚠️ 踩坑提醒:很多开发者在处理图结构时,容易忽略方向性带来的信息损失,导致模型偏差。务必根据实际业务逻辑选择合适的图结构。