1. 概述
隐马尔可夫模型(HMM) 与 条件随机场(CRF) 都属于机器学习中的图模型家族。
本文将介绍它们的基本定义、相似点与关键差异,帮助你在实际任务中选择合适模型。虽然两者都可以用于序列标注任务(如词性标注),但它们在建模方式、训练策略和性能表现上存在显著区别。
2. 隐马尔可夫模型(HMM)
HMM 是一种生成式模型,它通过建模观测序列和隐藏状态之间的联合概率分布 p(x, y) 来进行序列建模。
以一个英文句子为例:
“Math is the language of nature.”
我们希望为每个词标注其词性(noun、verb、preposition 等)。在这个过程中,词是观测变量(灰色节点),词性是隐藏状态(白色节点)。
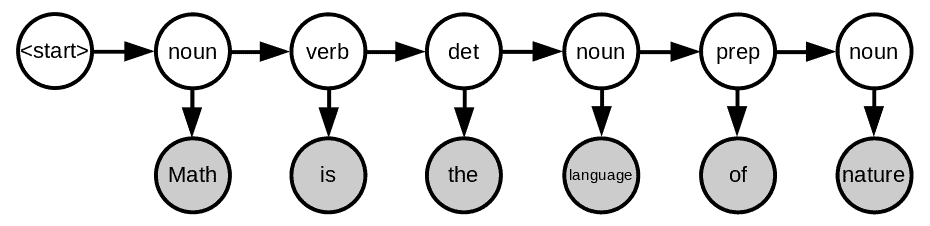
这是一个一阶隐马尔可夫模型,因为每个隐藏状态只依赖于前一个状态。其图结构如下:
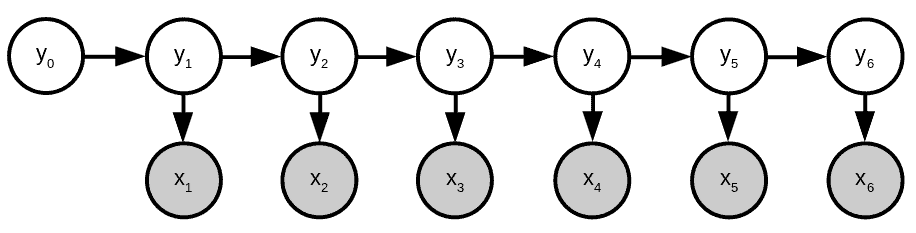
整个序列的概率可以表示为:
$$ p(\textbf{x},\textbf{y}) = \prod_{i=0}^{i=n} p(x_i|y_i)p(y_i|y_{i-1}) $$
其中:
- $ p(x_i|y_i) $ 是发射概率(emission probability)
- $ p(y_i|y_{i-1}) $ 是转移概率(transition probability)
HMM 是一种生成模型,因为它建模了观测和隐藏变量的联合分布。
2.1 示例:词性标注
假设我们有如下训练语料:
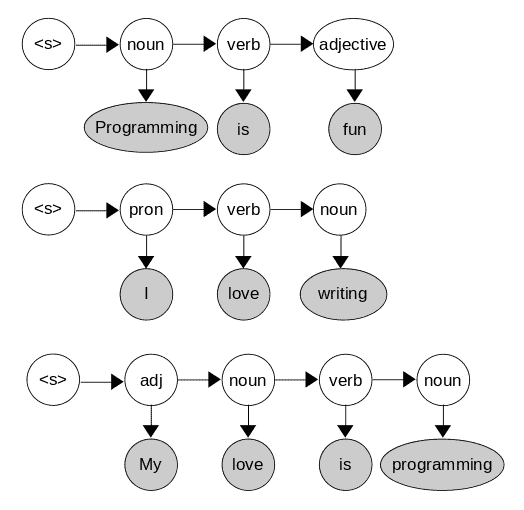
我们可以统计出发射概率表:
| 单词 | noun | verb | adjective | pronoun |
|---|---|---|---|---|
| programming | 0.5 | 0 | 0 | 0 |
| is | 0 | 0.67 | 0 | 0 |
| fun | 0 | 0 | 0.5 | 0 |
| my | 0 | 0 | 0.5 | 0 |
| love | 0.25 | 0.33 | 0 | 0 |
| I | 0 | 0 | 0 | 1 |
| writing | 0.25 | 0 | 0 | 0 |
以及转移概率表:
| 当前状态 → | noun | verb | adjective | pronoun |
|---|---|---|---|---|
| start | 0.33 | 0 | 0.33 | 0.33 |
| noun | 0 | 0.5 | 0 | 0 |
| verb | 0.67 | 0 | 0.33 | 0 |
| adjective | 0.5 | 0 | 0 | 0 |
| pronoun | 0 | 1 | 0 | 0 |
我们可以通过遍历所有可能的状态序列,找到概率最高的那一个。例如:
$$ p(\text{pron}|\texttt{start}) \times p(\text{I}|\text{pron}) \times p(\text{verb}|\text{pron}) \times p(\text{love}|\text{verb}) \times p(\text{noun}|\text{verb}) \times p(\text{programming}|\text{noun}) $$
$$ = 0.33 \times 1 \times 1 \times 0.33 \times 0.67 \times 0.5 = 0.0364815 $$
对于更长的句子,我们通常使用 Viterbi 算法 或 前向-后向算法 进行高效解码。
3. 条件随机场(CRF)
CRF 是一种判别式模型,它直接建模 p(y|x),即给定观测序列后隐藏状态的条件概率。
与 HMM 不同,CRF 是无向图模型,它通过定义特征函数(feature functions)来捕捉观测与状态之间的关系。
3.1 特征函数
特征函数描述了词在特定上下文中的属性。例如:
- “当前词是名词,且上一个词也是名词”
- “当前词是疑问词,且句子以问号结尾”
- “当前词是动词,且位于句子的第二个位置”
这些函数可以是状态函数(红色)或转移函数(绿色):
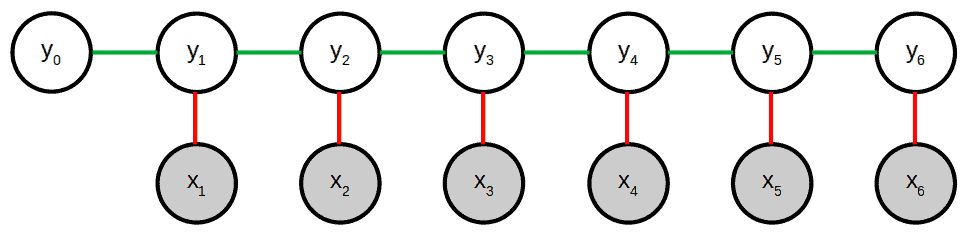
3.2 数学表达
CRF 的条件概率公式如下:
$$ p(\textbf{y}|\textbf{x}) = \frac{1}{Z(\textbf{x})} \prod_{t=1}^{T} \exp \left{ \sum_{k=1}^{K}\theta_k f_k(y_t, y_{t-1}, \textbf{x}_t) \right} $$
其中:
- $ f_k(y_t, y_{t-1}, \textbf{x}_t) $ 是特征函数,取值为 0 或 1
- $ \theta_k $ 是该特征函数的权重
- $ Z(\textbf{x}) $ 是归一化因子
训练时我们使用梯度下降法来学习最优的权重参数。
3.3 示例:词性标注
假设我们定义以下特征函数:
f1:词以 ing 结尾,且为名词f2:词是第二个词,且为动词f3:前一个词是动词,当前词是名词f4:词属于{I, you, he, she, we, they},且为代词f5:词属于{my, your, his, her, their, our},且为形容词f6:词在形容词之后,且为名词f7:词在动词 is 之后,且为形容词
通过训练数据,我们可以学习这些特征函数的权重,使得模型能更准确地进行标注。
4. HMM vs CRF 对比
| 特性 | HMM | CRF |
|---|---|---|
| 类型 | 生成式模型 | 判别式模型 |
| 训练方法 | 最大似然估计(MLE) | 梯度下降 |
| 推理方法 | 前向-后向 / Viterbi | 前向-后向 / Viterbi |
| 图结构 | 有向图 | 无向图 |
| 上下文建模 | 局部上下文 | 全局 + 局部上下文 |
| 计算复杂度 | 较低 | 较高 |
| 准确率 | 一般 | 更高 |
✅ HMM 的优势
- 实现简单,训练快速
- 适合小数据集或对计算资源敏感的场景
✅ CRF 的优势
- 可定义任意特征函数,建模更灵活
- 支持非连续上下文建模(如句子首尾关系)
- 在复杂任务中表现更优
⚠️ CRF 的劣势
- 归一化因子 $ Z(\textbf{x}) $ 难以精确计算
- 训练过程更慢,参数调优更复杂
5. 总结
| 项目 | HMM | CRF |
|---|---|---|
| 模型类型 | 生成式 | 判别式 |
| 训练方式 | MLE(统计频率) | 梯度下降 |
| 推理算法 | 前向-后向 / Viterbi | 前向-后向 / Viterbi |
| 图结构 | 有向图 | 无向图 |
| 上下文建模 | 局部 | 全局+局部 |
| 计算复杂度 | 低 | 高 |
| 应用场景 | 小数据、实时性要求高 | 高精度、复杂上下文任务 |
6. 结论
HMM 和 CRF 是两种经典的序列建模方法:
- HMM 更适合资源受限或对速度要求高的场景
- CRF 更适合需要高精度和复杂特征建模的任务
在实际应用中,可以根据任务需求和数据特点选择合适的模型。如果你需要更高的标注精度,CRF 是更好的选择;而如果你需要快速实现和部署,HMM 仍然是一个不错的选择。