1. 简介
爬山算法(Hill Climbing Algorithm)是最早被提出、也是最简单的一种局部搜索优化算法。它广泛应用于解决某些特定类型的优化问题,尤其适用于目标函数具有凸性(convex)的问题。在本篇文章中,我们将从原理、实现方式、局限性以及其进阶版本(如模拟退火)等方面对爬山算法进行深入解析。
2. 基本概念
在深入理解爬山算法之前,先明确几个关键术语,有助于我们构建正确的认知框架:
- 数学优化问题:寻找目标函数的最大值或最小值,通常依赖于输入变量的取值。
- 启发式搜索(Heuristic Search):在缺乏精确数学模型的情况下使用,能快速找到近似最优解,但不一定能找到全局最优解。
- 局部搜索(Local Search):通过在当前解的邻域中寻找更优解来逐步改进当前解,适合用于启发式搜索。
- 凸优化(Convex Optimization):如果目标函数是凸函数,局部最优解即为全局最优解,这类问题非常适合局部搜索策略。
爬山算法本质上是一种启发式局部搜索算法。它通过在当前解的邻域内不断寻找更优解,逐步逼近最优解。对于凸优化问题,它可以找到全局最优;而对于非凸问题,通常只能找到局部最优。
3. 爬山算法的工作原理
我们以最大化问题为例来说明爬山算法的运行机制。
算法流程如下:
- 从一个初始解出发;
- 在当前解的邻域中生成一个或多个候选解;
- 如果某个候选解的目标函数值优于当前解,则接受该候选解作为新的当前解;
- 重复上述过程,直到满足终止条件(如达到最大迭代次数、无法再找到更优解等)。
✅ 特点:
- 贪心策略:每一步都朝着目标函数值增大的方向移动;
- 无回溯机制:只关注当前状态,不记录历史状态;
- 生成-测试机制:每次生成候选解后进行测试决定是否接受;
- 增量式改进:通过小步调整逐步优化当前解。
下面是爬山算法的基本伪代码(以最大化为例):
State current = initial_state;
while (true) {
State next = selectNextNeighbor(current);
if (next == null || next.value <= current.value) {
break;
}
current = next;
}
return current;

4. 爬山算法的局限性
爬山算法虽然简单高效,但存在一些明显的局限性,尤其在面对复杂的非凸问题时。我们可以借助状态空间图来直观理解这些问题:

4.1. 局部极大值(Local Maximum)
当算法到达一个局部极大值时,所有邻域内的解都不如当前解,因此无法继续前进。
4.2. 平台区(Plateau 或 Flat Local Maximum)
在一个平台区域中,多个邻近解的目标函数值与当前解相同,算法无法判断下一步应向哪个方向移动。
4.3. 山脊(Ridge)
山脊区域中,虽然存在全局最优方向,但由于邻域内的解目标函数值都低于当前解,算法无法感知“坡度”而陷入停滞。
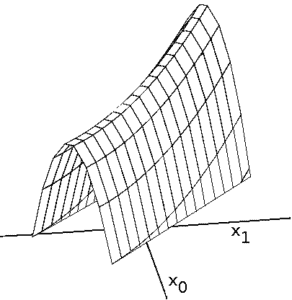
4.4. 肩部(Shoulder)
肩部是平台的一种变体,其中一个边缘方向可以继续提升目标函数值。但由于没有明显的梯度变化,算法难以识别。
5. 爬山算法的变体与改进
为了解决上述问题,人们提出了多种改进版本的爬山算法:
5.1. 最陡爬山法(Steepest Hill Climbing)
每次在当前解的邻域中选择目标函数值最高的解作为下一个状态。
State next = findBestNeighbor(current);
if (next.value > current.value) {
current = next;
}
5.2. 随机爬山法(Stochastic Hill Climbing)
随机选择一个邻域解,如果其目标函数值更高,则接受。
List<State> neighbors = generateNeighbors(current);
State randomNeighbor = pickRandom(neighbors);
if (randomNeighbor.value > current.value) {
current = randomNeighbor;
}
5.3. 首选爬山法(First-choice Hill Climbing)
依次检查邻域解,一旦发现比当前解更好的解就立即接受,不再继续比较。
for (State neighbor : neighbors) {
if (neighbor.value > current.value) {
current = neighbor;
break;
}
}
这些变体在一定程度上缓解了原始算法的局限性,但依然存在陷入局部最优的风险。
6. 模拟退火(Simulated Annealing)
模拟退火可以看作是爬山算法的一个高级变种,尤其擅长跳出局部最优。
6.1. 物理类比:退火过程
模拟退火的灵感来源于固体退火过程。在高温状态下,粒子具有较高的能量,可以自由移动;随着温度下降,粒子逐渐趋于稳定状态。
目标函数值类似于粒子的能量,温度控制算法接受较差解的概率。
Boltzmann 分布公式如下:
$$ n(E) = n_0 \exp\left(-\frac{E}{kT}\right) $$
其中:
- $ n_0 $:总粒子数
- $ k $:玻尔兹曼常数
- $ T $:温度
6.2. Metropolis 准则
模拟退火的核心是 Metropolis 准则,允许算法在某些情况下接受较差的解:
- 若新解目标函数值更大,则接受;
- 若新解目标函数值更小,则以一定概率接受:
$$ P = \exp\left(-\frac{f_0 - f_1}{T}\right) $$
其中:
- $ f_0 $:当前解的目标函数值
- $ f_1 $:新解的目标函数值
- $ T $:当前温度
Java 示例代码如下:
double temperature = 1.0;
double coolingRate = 0.99;
while (temperature > 1e-6) {
State candidate = generateNeighbor(current);
double delta = candidate.value - current.value;
if (delta > 0 || Math.random() < Math.exp(delta / temperature)) {
current = candidate;
}
temperature *= coolingRate;
}
随着温度下降,算法接受较差解的概率逐渐降低,最终趋于稳定。
7. 总结
爬山算法是一个简单但实用的启发式局部搜索算法,特别适用于目标函数具有凸性的优化问题。它在市场营销、机器人路径规划、任务调度等领域有广泛应用。
尽管存在局部最优、平台区、山脊等局限性,但通过引入随机性、温度机制(如模拟退火)等方法,可以有效扩展其适用范围。
模拟退火作为爬山算法的进阶形式,能够在搜索初期接受较差解,从而跳出局部最优,最终逼近全局最优。在实际工程中,尤其是在多模态问题中,模拟退火有时甚至优于遗传算法等更复杂的优化方法。
✅ 踩坑提醒:
- 不要盲目使用标准爬山算法处理非凸问题;
- 在实现模拟退火时,温度下降速率和初始温度的选择对结果影响很大;
- 适当引入随机性可以提升算法的跳出局部最优能力。
爬山算法虽简单,但其思想影响深远,是理解现代优化算法的重要基础。