1. 编译器的基本作用
编程语言的诞生是为了让开发者能够编写出人类可读的源代码。然而,计算机只能理解并执行机器码(machine code),而人类几乎无法直接编写或阅读这种代码。因此,编译器的作用就是将高级语言的源代码翻译成特定机器可以执行的机器码。
在本文中,我们将深入分析编译过程的各个阶段,探讨编译器与解释器之间的区别,并介绍一些现代编程语言中使用的编译器实例。
2. 编译过程的六个阶段
编译过程的核心目标是将高级语言转换为低级机器码。此外,编译器还需要检测并报告源代码中的错误,尤其是语法错误。
整个编译过程通常包括以下六个主要阶段:
- 词法分析(Lexical Analysis)
- 语法分析(Syntax Analysis)
- 语义分析(Semantic Analysis)
- 中间代码生成(Intermediate Code Generation)
- 优化(Optimization)
- 代码生成(Code Generation)
下面我们将逐一介绍这些阶段。
2.1 词法分析
词法分析是编译的第一步。在这个阶段,编译器会将源代码拆分成一个个称为“词素(lexeme)”的片段。
✅ 举个例子:
String greeting = "hello";
这段代码会被拆分为以下五个词素:
Stringgreeting="hello";
然后,每个词素会被封装为一个“记号(token)”,记号不仅包含词素本身,还描述了它的类型(如关键字、标识符、字符串字面量等)以及在源码中的位置信息。这一过程也被称为“记号化(tokenization)”。
2.2 语法分析
在语法分析阶段,编译器使用上一步生成的记号序列来构建一个“抽象语法树(Abstract Syntax Tree, AST)”。AST 是程序逻辑结构的树状表示。
✅ 语法分析主要完成两个任务:
- 检查源代码的语法是否正确
- 构建 AST,供后续阶段使用
如果语法有误(如缺少分号或括号不匹配),编译器会报错并中止编译。
2.3 语义分析
语义分析阶段使用 AST 来检查代码的逻辑是否合理。例如:
❌ 常见语义错误包括:
- 将错误类型赋值给变量
- 同一作用域内重复声明变量
- 使用未声明的变量
- 使用语言关键字作为变量名
语义分析通常包括以下步骤:
- 类型检查(Type Checking):确保赋值、运算和函数调用中的类型匹配
- 控制流检查(Flow Control Checking):验证控制结构(如循环、条件判断)是否正确使用
- 标号检查(Label Checking):确保标签和标识符使用合法
语义分析最终会生成一个带有附加信息的 AST(即“注解 AST”),用于后续阶段。
2.4 中间代码生成
在完成语义分析后,编译器会生成一种中间代码(Intermediate Code),它是一种接近机器码但又与具体硬件无关的表示形式。
✅ 中间代码的优势:
- 不依赖具体机器架构,便于跨平台使用
- 更容易进行优化操作
中间代码通常有两种形式:
- 高级中间代码:接近源语言,便于优化源码性能
- 低级中间代码:接近机器码,便于进行底层优化
2.5 优化
优化阶段的目标是提升代码的运行效率,同时确保其语义不变。
✅ 优化应遵循三个原则:
- 不能改变程序原有的语义
- 应该减少资源消耗并提高执行速度
- 优化过程本身不能显著增加编译时间
✅ 常见优化技术包括:
- 函数内联(Function Inlining):将函数调用替换为函数体
- 死代码消除(Dead Code Elimination):移除永远不会执行的代码
- 循环合并(Loop Fusion):将多个结构相似的循环合并为一个
- 指令合并(Instruction Combining):如将
x = x + 10; x = x - 7;合并为x = x + 3;
2.6 代码生成
在最后阶段,编译器将优化后的中间代码转换为目标机器的机器码。生成的代码必须保持源代码的语义,并在内存和 CPU 资源使用上尽可能高效。
同时,代码生成过程本身也需高效,以避免影响整体编译性能。
2.7 实例流程图
下图展示了一个简单语句在编译过程中各阶段的流转过程:
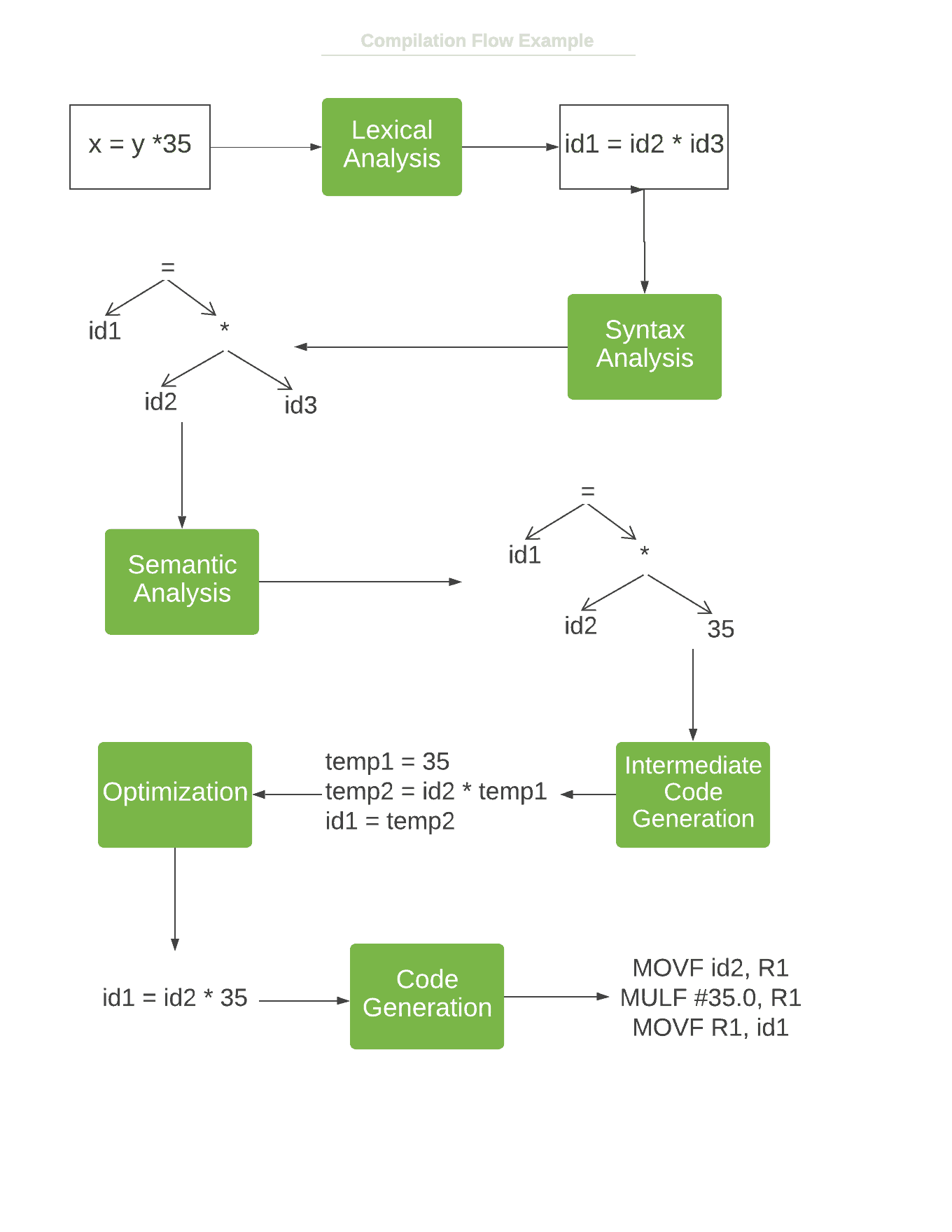
3. 编译器 vs 解释器
编译器和解释器都能将源代码转化为可执行代码,但它们的工作方式不同。
✅ 编译器:
- 将源代码一次性转换为机器码,不执行
- 需要了解目标机器特性
- 每条指令只翻译一次
- 执行速度快,但编译耗时较长
- 生成中间代码,占用内存较多
- 示例:Java、C++、Swift、C#
❌ 解释器:
- 直接执行源代码或中间代码
- 不需要了解目标机器
- 同一条指令可能被多次解析
- 执行速度较慢,但启动更快
- 直接执行代码,内存占用少
- 示例:Ruby、Lisp、PHP、PowerShell
⚠️ 有些语言(如 Java)使用的是混合方式:先由编译器生成字节码,再由解释器(JVM)执行。
4. 现代编译器实例
4.1 Javac
Java 编译器 javac 将 Java 源代码编译为字节码(bytecode),然后由 JVM 解释执行。这种方式使 Java 具备了跨平台能力。
✅ 其他语言如 Kotlin、Scala 也可以编译为 JVM 字节码,说明 JVM 是一个多语言执行平台。
4.2 Mono
Mono 是一个 .NET 平台的开源实现,包含 C# 编译器和运行时环境。它允许 .NET 应用在 Linux、macOS 等非 Windows 平台上运行。
✅ Mono 编译器将 C# 源代码编译为 IL(Intermediate Language)字节码,然后由 Mono 运行时执行。
4.3 GNU Compiler Collection (GCC)
GCC 是 GNU 项目的一部分,支持多种编程语言和平台。它不仅是一个编译器集合,还负责调用汇编器和链接器,最终生成可执行文件。
✅ GCC 支持的语言包括:
- C(gcc)
- C++(g++)
- Objective-C(gobjc)
- Fortran(g77 / GFortran)
- Java(gcj)
- Ada(gnat)
GCC 的跨平台能力和广泛的硬件支持使其成为 Linux 系统中最常用的编译器工具链。
5. 总结
本文介绍了编译器的基本作用及其六个核心编译阶段。我们还比较了编译器与解释器的区别,并列举了几个现代编程语言中广泛使用的编译器实例。
✅ 编译器是连接高级语言与机器执行的关键桥梁。理解其工作原理有助于我们更好地编写高效、健壮的代码。