1. 简介
在本文中,我们将探讨如何使用 K-Means 聚类算法 来进行分类任务。虽然 K-Means 本质上是一种无监督学习算法,但通过适当调整,它可以在有监督或半监督的场景中辅助分类器的构建。
2. 聚类 vs 分类
聚类(Clustering)和分类(Classification)是机器学习中两个不同的任务:
- 分类:数据是有标签的,我们的目标是训练一个模型,能够准确预测新数据的类别标签。
- 聚类:数据是无标签的,我们的目标是根据数据点之间的相似性将它们分组。
✅ 但聚类算法(如 K-Means)也可以与分类器结合使用,甚至可以用于辅助训练分类器。
3. K-Means 作为预处理步骤
假设我们有一组无标签的数据,例如经典的 Iris 数据集,如下图所示:
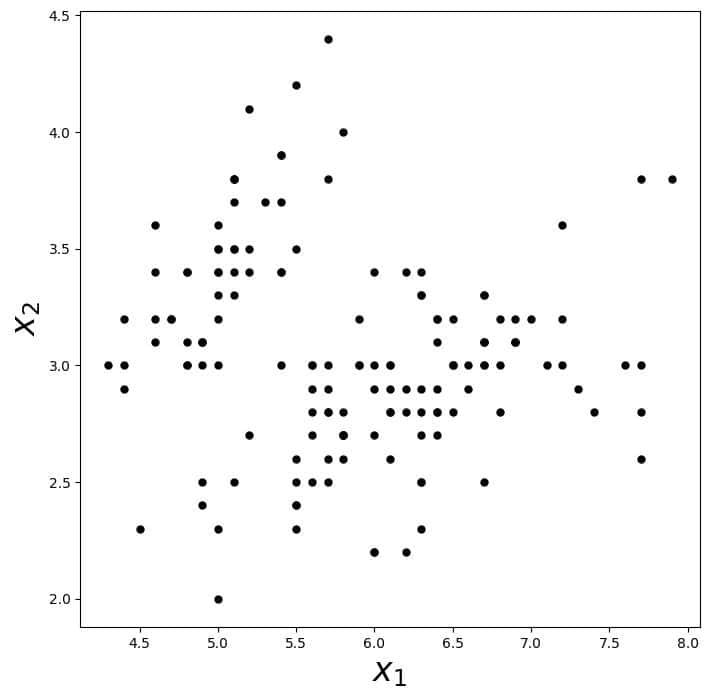
其中,x₁ 是花瓣长度(sepal length),x₂ 是花瓣宽度(sepal width)。
虽然我们不知道这些数据点的真实标签,但我们知道它们属于两个或多个类别。此时,我们可以先使用 K-Means 进行聚类,然后将每个聚类视为一个类别,从而为后续的分类任务打上伪标签。
✅ 也就是说:我们先从数据中“学习”出标签,再基于这些标签训练分类器。
例如,K-Means 在上述数据中可能找到如下三个聚类和对应的质心:
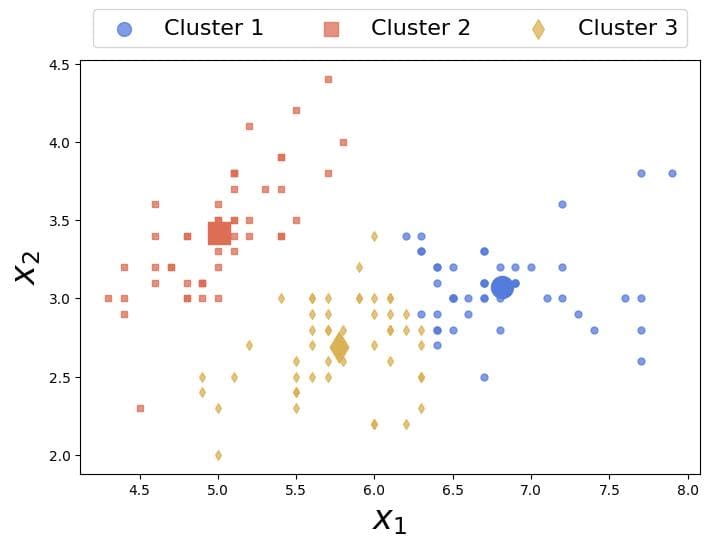
之后,我们可以用这些聚类结果训练一个神经网络来区分这三类。
4. 基于 K-Means 的简单分类器
我们也可以不引入额外的分类器,而是直接使用 K-Means 的聚类质心进行分类。
分类逻辑很简单:将新样本分配到离它最近的聚类质心所对应的类别中。
如下图所示:
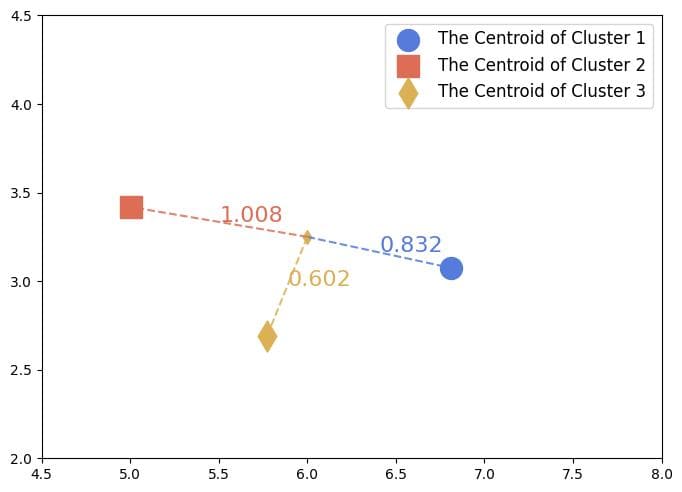
对于位于三个聚类之间的样本点,由于它离第三个聚类的质心最近,因此我们将其分类为 y=3。
5. 存在的问题
上述两种方法都依赖于无标签数据上 K-Means 的聚类结果,但这种方法存在一些潜在问题:
❌ 聚类误差可能不可忽略。K-Means 要求我们预先设定聚类数 k,这通常通过肘部法则(Elbow Method)来估计,但这个估计值可能不准确。
❌ 即使我们设定了正确的聚类数量,K-Means 的聚类结果也可能与真实类别不一致,尤其是当使用的距离度量不能准确反映类别相似性时。
⚠️ 更严重的是:由于我们从无标签数据出发,无法用真实标签来验证聚类结果的准确性。
所以,即使我们通过聚类“发现”了类别,最终仍需要人工来判断每个聚类代表什么。
6. 使用 K-Means 进行分类
即使数据是带标签的,我们依然可以使用 K-Means,只需稍作调整即可。此时我们可以将 K-Means 视为一种有监督的训练手段。
✅ 我们可以设定聚类数等于类别数,并使用真实标签来评估聚类质量。
分类时,我们依然基于新样本与各个聚类质心的距离来进行分类。
6.1. 无监督 K-Means
假设我们有一个数据集:
$$ { (x_i, y_i)}_{i=1}^{n} $$
其中 $x_i$ 是样本,$y_i$ 是其类别标签。
在标准 K-Means 中,我们通过最小化组内距离平方和来寻找最优聚类中心:
$$ J(c_1, c_2, \ldots, c_d) = \sum_{j=1}^{d}\frac{1}{n_j}\sum_{i : x_i \in \mathcal{C}_j} ||x_i - c_j||^2 $$
通常使用 期望最大化(EM)算法 来求解。
6.2. 有监督 Gini 不纯度优化
既然我们有真实标签 $y_i$,就可以引入 Gini 不纯度 来衡量聚类的质量:
$$ G_j = 1 - \sum_{k=1}^{d} \left( \frac{n_{k, j}}{n_j} \right)^2 $$
其中,$n_{k,j}$ 表示第 j 个聚类中属于第 k 类的样本数量。
我们可以通过最小化平均 Gini 不纯度来提高聚类的类别一致性:
$$ \frac{1}{d}\sum_{j=1}^{d}G_j $$
进一步地,我们还可以将聚类内距离和 Gini 不纯度结合起来,同时优化这两个目标:
$$ J(c_1, c_2, \ldots, c_d) = \left( \sum_{j=1}^{d}\frac{1}{n_j}\sum_{i : x_i \in \mathcal{C}j} ||x_i - c_j||^2 \right) + \frac{1}{d}\sum{j=1}^{d}G_j $$
6.3. 聚类作为正则化手段
有趣的是,K-Means 的过程可以看作一种 正则化机制。通过将相似样本聚在一起,可以防止模型过拟合。
我们可以引入一个正则化系数 $\lambda > 0$ 来控制聚类紧凑性和分类准确性的平衡:
$$ J(c_1, c_2, \ldots, c_d) = \lambda \left( \sum_{j=1}^{d}\frac{1}{n_j}\sum_{i : x_i \in \mathcal{C}j} ||x_i - c_j||^2 \right) + \frac{1}{d}\sum{j=1}^{d}G_j $$
- ✅ $\lambda$ 越大,模型越注重聚类的紧凑性;
- ❌ $\lambda$ 越小,模型更关注分类准确率,可能导致聚类形状松散。
7. 小结
本文介绍了如何使用 K-Means 聚类算法进行分类任务:
- ✅ K-Means 可以作为预处理步骤,为无标签数据生成伪标签。
- ✅ 可以直接基于聚类质心进行分类。
- ⚠️ 聚类结果可能不准确,需谨慎使用。
- ✅ 在有标签数据中,K-Means 可结合 Gini 不纯度进行优化,提升分类性能。
- ✅ K-Means 也可以作为正则化工具,提升模型泛化能力。
虽然 K-Means 是一种无监督算法,但通过巧妙设计,它也能在分类任务中发挥作用。