1. 简介
k-近邻算法(k-Nearest Neighbors,简称 k-NN)是一种基础的机器学习模型,广泛用于分类和回归任务,尤其在分类场景中更为常见。
该算法的核心思想是:相似的数据点彼此靠近。当我们需要预测一个新数据点的类别或数值时,会考察它最近的 k 个邻居,然后根据这些邻居的信息做出预测,比如取平均值或加权平均值。
在本篇文章中,我们将探讨:
- 如何选择合适的 k 值和距离度量方式以提高准确率
- k-NN 在高维数据下的表现
- 高维数据带来的挑战及应对策略
2. k-近邻算法(k-NN)
✅ 优点
- 算法思想简单,易于实现
- 不需要训练阶段,是典型的“惰性学习”(Lazy Learning)算法
- 适用于分类和回归任务
- 可随时向数据集中添加新样本
- 输出结果直观易懂
- 仅需调整一个超参数 k
❌ 缺点
- 依赖于历史数据,存储开销大
- 对噪声、异常值和缺失值敏感
- 要求特征标准化处理
- 对类别型特征处理困难
- 大数据集下计算距离代价高
- 高维数据下计算效率低
2.1. 如何选择 k 值
通常建议将 k 值设为奇数,以避免在二分类任务中出现平票(tie)情况。例如,在 k=3 时,如果两个邻居是红色,一个邻居是蓝色,则最终预测为红色。
k 值的选择直接影响分类结果:
如下图所示,当 k=3 时,预测为红色;而当 k=5 时,预测为蓝色:
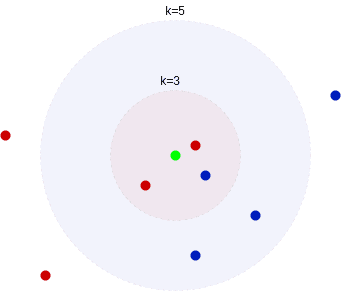
k 值对决策边界的影响:
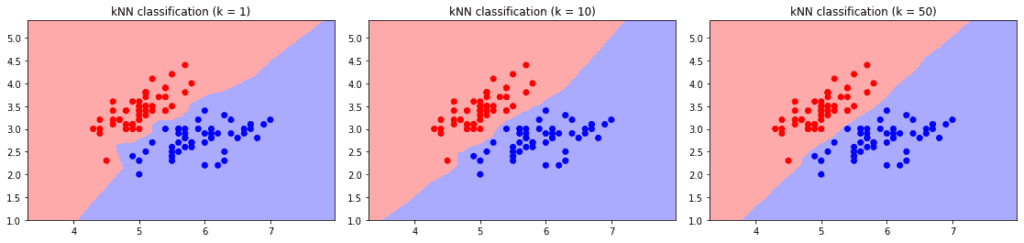
- 大 k 值:导致高偏差,决策边界更平滑,忽略局部细节,可能将所有样本归为多数类。
- 小 k 值:导致高方差,决策边界波动大,容易过拟合,对训练数据的小变化非常敏感。
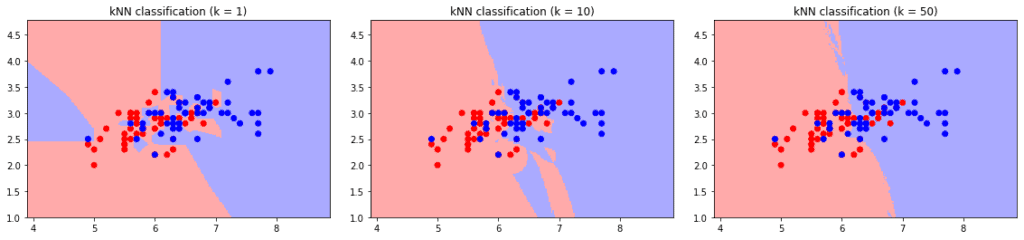
在类别交界区域,这种波动更为明显:
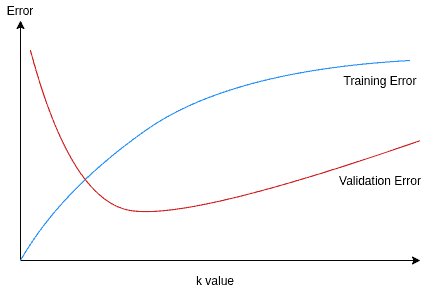
选择 k 值的建议:
- 通过训练误差和验证误差来选择最优 k 值
- 训练误差在 k=1 时最小(为 0),但验证误差在 k 过小或过大时都会上升
- 最佳 k 值通常对应验证误差最低的点
2.2. 距离度量方式
虽然距离度量不是超参数,但其选择直接影响模型效果。以下是几种常用的度量方式:
1. 欧几里得距离(Euclidean Distance)
适用于连续数值空间,是默认的常用距离方式:
$$ d(x, y) = \sqrt{\sum_{i=1}^{n}(x_i - y_i)^2} $$
2. 曼哈顿距离(Manhattan Distance)
也称 L1 距离,适合高维稀疏数据:
$$ d(x, y) = \sum_{i=1}^{n}|x_i - y_i| $$
3. 切比雪夫距离(Chebyshev Distance)
只考虑各维度的最大差值:
$$ d(x, y) = \max(|x_i - y_i|) $$
4. 明可夫斯基距离(Minkowski Distance)
上述三种距离的通用形式:
$$ d(x, y) = \left(\sum_{i=1}^{n}|x_i - y_i|^p\right)^{1/p} $$
- p=1:曼哈顿距离
- p=2:欧几里得距离
- p→∞:切比雪夫距离
⚠️ 在高维数据中,推荐使用较小的 p 值,如曼哈顿距离(p=1),以提升计算效率。
5. 汉明距离(Hamming Distance)
用于比较等长字符串或整数向量:
$$ d(x, y) = \sum_{i=1}^{k}|x_i - y_i| $$
6. 杰卡德距离(Jaccard Distance)
用于布尔型向量,衡量集合重叠程度。
7. 余弦相似度(Cosine Similarity)
虽然不是严格意义上的“距离”,但常用于文档、基因序列等向量分类任务,衡量方向相似性。
3. 高维数据的挑战
随着特征维度的增加,k-NN 的性能显著下降,这就是所谓的“维度灾难(Curse of Dimensionality)”。
主要问题:
- 计算距离的代价变高
- “相似数据点靠近”的假设失效
原因分析:
假设数据均匀分布于 [0,1] 区间,k=10,n=1000:
- 在二维空间中,边长为 0.1 的正方形即可覆盖 10 个样本点
- 在三维空间中,边长需增加到约 0.63
- 在 100 维空间中,边长约为 0.955
- 在 1000 维空间中,边长接近 0.995
公式为:
$$ s = \left(\frac{k}{n}\right)^{1/f} $$
可见,随着维度 f 增加,我们不得不在一个非常大的区域内搜索邻居,导致所有点之间的距离变得“差不多”,从而失去区分度。
应对策略
3.1. 数据降维(Dimension Reduction)
通过特征选择或特征提取降低维度,同时保留数据结构:
- 特征选择:剔除冗余特征,保留关键特征
- 特征提取:将原始特征映射到低维空间,如 PCA(主成分分析)
✅ PCA 是一种常用方法,能将高维数据压缩到低维,同时保留最大方差信息。
- 核方法(Kernel Methods):适用于非线性结构数据
- 数量缩减(Numerosity Reduction):减少样本数量,降低计算量
3.2. 使用近似 k-NN(Approximate k-NN)
在高维数据中,精确查找最近邻代价太高,可使用近似算法:
- 局部敏感哈希(LSH):将相似项哈希到同一桶中,实现快速近似查找
- 随机投影(Random Projection):将高维数据映射到低维空间,保持欧几里得距离不变
- 随机投影森林(rpForests):高效实现近似聚类和最近邻查找
4. 总结
本文介绍了 k-近邻算法的基本原理、优缺点、k 值选择策略和距离度量方式。
我们还分析了 k-NN 在高维数据下的性能退化问题,并探讨了应对维度灾难的策略,包括:
- 数据降维(PCA、特征选择)
- 使用近似算法(LSH、随机投影)
k-NN 是一个简单但强大的模型,但在高维场景下需要谨慎使用。合理选择参数、优化距离计算、结合降维技术,可以显著提升其在实际应用中的表现。