1. 简介
在本教程中,我们将学习几种计算两个字符串之间 Levenshtein 距离的方法。此外,我们还将探讨基础实现的复杂度,并讨论一些可能的优化策略。
但在那之前,让我们先回顾一下 Levenshtein 距离的基本概念。
2. 非正式定义
Levenshtein 距离是指将一个字符串转换为另一个字符串所需的最小编辑操作次数。编辑操作包括插入、删除和替换。
在下面的例子中,我们需要对单词 INTENTION 执行 5 次操作才能将其转换为 EXECUTION。因此,这两个单词之间的 Levenshtein 距离为 5:
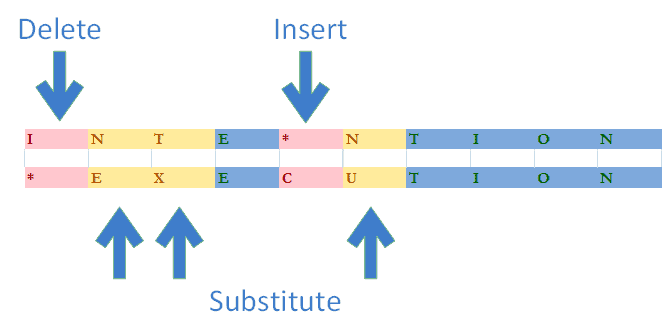
Levenshtein 距离是编辑距离家族中最流行的度量标准。这些距离度量的区别在于它们允许的基本操作集。例如,Hamming 距离仅允许替换操作。而 Damerau-Levenshtein 距离则在 Levenshtein 的基础上允许字符交换。因此,它在实际中常被使用,并通常也被称为 Levenshtein 距离。
在经典 Levenshtein 距离中,每种操作的代价为 1。此外,特殊版本可能会为不同操作分配不同的代价,甚至代价可能依赖于具体字符。我们也可以定义复杂的代价函数来体现字符在视觉或发音上的相似性。
3. 形式化定义与性质
两个字符串 a 和 b 的 Levenshtein 距离记为 lev(a, b),定义如下:

其中,1_{(a_i ≠ b_j)} 是一个指示函数,当 a_i == b_j 时为 0,否则为 1。|a| 表示字符串 a 的长度。
此外,lev(i, j) 表示字符串前缀(即 a 的前 i 个字符和 b 的前 j 个字符)之间的距离。
第一部分表示将一个前缀转换为空字符串所需的插入或删除次数。
第二部分是一个递归表达式,分别对应删除、插入和替换操作。
Levenshtein 距离具有以下性质:
- 它为 0 当且仅当两个字符串相等:

- 它是对称的:

- 它的值最大不超过较长字符串的长度:

- 它的值至少为两字符串长度之差:

- 满足三角不等式:

这些性质对于理解算法的实现原理以及在实际应用中非常有帮助。
特别是三角不等式性质,可用于构建度量空间(Metric Space),从而使用诸如 BK-tree、VP-tree 等结构进行高效索引。
4. 算法实现
现在我们了解了 Levenshtein 距离的理论基础和基本性质,接下来我们将讨论其具体实现方式。我们将从最简单但效率最低的算法开始,逐步介绍优化方法。
以下所有算法均使用 0-based 字符串索引。
4.1. 递归实现(基于定义)
根据定义,我们可以写出一个直观的递归算法:
algorithm LevDist(a, b):
// INPUT
// a = the first string (0-indexed)
// b = the second string (0-indexed)
// OUTPUT
// The Levenshtein distance between strings a and b
if a.size() == 0:
return b.size()
if b.size() == 0:
return a.size()
if a[0] != b[0]:
indicator = 1
else:
indicator = 0
return min(
LevDist(a[1:], b) + 1, // deletion
LevDist(b[1:], a) + 1, // insertion
LevDist(a[1:], b[1:]) + indicator // substitution
)
该算法中,x.substr(n) 返回从第 n 个元素开始的子串。
⚠️ 该实现对相同的前缀重复计算多次,因此效率极低。
4.2. 动态规划(完整矩阵)
利用 Levenshtein 距离的性质,我们可以构造一个大小为 (len(a)+1) x (len(b)+1) 的矩阵,其中 distance[i][j] 表示 a[0..i-1] 与 b[0..j-1] 的距离。
初始化第一行和第一列为 0 到 len(a) 和 len(b)。
然后使用动态规划填充矩阵:
algorithm LevenshteinDistanceIterativeFullMatrix(a, b):
// INPUT
// a = the first string (0-indexed)
// b = the second string (0-indexed)
// OUTPUT
// The Levenshtein distance between a and b
n = a.size()
m = b.size()
for i in 0..n:
distance[i][0] = i
for j in 0..m:
distance[0][j] = j
for i in 1..n:
for j in 1..m:
if a[i-1] != b[j-1]:
indicator = 1
else:
indicator = 0
distance[i][j] = min(
distance[i-1][j] + 1, // deletion
distance[i][j-1] + 1, // insertion
distance[i-1][j-1] + indicator // substitution
)
return distance[n][m]
对 INTENTION → EXECUTION 的转换,我们可得到如下矩阵:
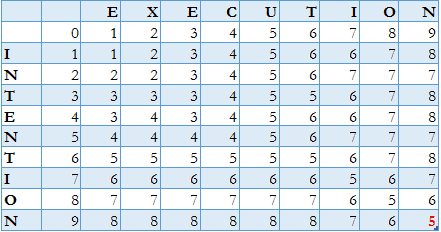
右下角的值 5 正是我们之前观察到的结果。
4.3. 动态规划(双行优化)
为了节省空间,我们只需保留两行:当前行和上一行:
algorithm LevDistIterativeTwoRows(a, b):
// INPUT
// a = the first string (0-indexed)
// b = the second string (0-indexed)
// OUTPUT
// the Levenshtein distance between strings a and b
n = a.size()
m = b.size()
previous = [0..m] // 初始化为 0~m
for i in 0..n-1:
current[0] = i + 1
for j in 0..m-1:
if a[i] != b[j]:
indicator = 1
else:
indicator = 0
current[j+1] = min(
previous[j+1] + 1, // deletion
current[j] + 1, // insertion
previous[j] + indicator // substitution
)
previous = current // 拷贝 current 到 previous
return previous[m]
⚠️ 该优化会丢失编辑路径信息,若需要编辑路径,可以使用 Hirschberg 算法结合分治策略。
4.4. 动态规划(单行优化)
进一步观察,我们发现计算每个位置只需要三个值:上方、左侧和对角线上的值。
因此,可以只使用一行和两个临时变量实现:
algorithm LevenshteinDistanceIterativeSingleRow(a, b):
// INPUT
// a = the first string (0-indexed)
// b = the second string (0-indexed)
// OUTPUT
// The Levenshtein distance between strings a and b
n = a.size()
m = b.size()
row = [0..m]
for i in 0..n-1:
row[0] = i + 1
prevDiag = row[0]
for j in 0..m-1:
if a[i] != b[j]:
indicator = 1
else:
indicator = 0
temp = row[j+1]
row[j+1] = min(
row[j] + 1, // insertion
temp + 1, // deletion
prevDiag + indicator // substitution
)
prevDiag = temp
return row[m]
5. 时间与空间复杂度分析
上述所有迭代算法的时间复杂度均为 O(|a| * |b|)。
- 完整矩阵实现的空间复杂度为
O(|a| * |b|),通常不实用。 - 双行和单行优化将空间复杂度降低至
O(max(|a|, |b|))。 - 若交换字符串,可进一步优化为
O(min(|a|, |b|))。
⚠️ 已有研究表明,除非 强指数时间假设 不成立,否则无法在亚二次时间内计算 Levenshtein 距离。
不过,这只是最坏情况下的结论。我们可以通过以下优化手段提升实际性能。
5.1. 公共前后缀优化
观察 INTENTION 和 EXECUTION,我们发现它们有共同的后缀 TION。这部分不影响距离计算。
✅ 优化思路:移除最长公共前缀和后缀,减少参与完整计算的字符串长度。
algorithm LevDistTweaked(a, b):
prefixLength = findCommonPrefix(a, b)
a = a[prefixLength:]
b = b[prefixLength:]
suffixLength = findCommonSuffix(a, b)
a = a[:len(a)-suffixLength]
b = b[:len(b)-suffixLength]
if a.empty():
return b.size()
if b.empty():
return a.size()
if b.size() > a.size():
swap(a, b)
return LevDist(a, b)
5.2. 设置距离上限
若我们只关心距离小于某个阈值的字符串(如拼写纠错),可以设置一个上限 K,只计算对角线附近 2K+1 区域的值。
✅ 优点:时间复杂度降为 O(min(|a|, |b|) * K),适用于长且相似字符串。
algorithm LevDistBounded(a, b, k):
if abs(len(a) - len(b)) > k:
return -1
previous = [0..min(len(b), k)] + [∞]*(len(b)-k)
current = [∞]*(len(b)+1)
for i in 0..len(a)-1:
stripeStart = max(0, i - k)
stripeEnd = min(len(b), i + k)
for j in stripeStart..stripeEnd:
current[j+1] = min(
previous[j+1] + 1,
current[j] + 1,
previous[j] + (a[i] != b[j])
)
previous = current
return previous[len(b)] if previous[len(b)] <= k else -1
5.3. 综合使用优化策略
我们可以将上述策略组合使用:
✅ 先使用快速近似算法(如 q-gram、Jaro-Winkler)过滤掉大部分不相似字符串
✅ 再对剩余候选使用完整 Levenshtein 距离排序
6. 自动机方法
使用 Levenshtein Automaton,我们可以为字符串 W 和距离 N 构造一个有限状态自动机,接受所有与 W 距离 ≤ N 的字符串。
✅ 优点:匹配时间线性于字符串长度
⚠️ 缺点:自动机构建开销大(但可在 O(|W|) 时间内完成)
7. 应用场景
Levenshtein 距离广泛应用于:
- 拼写检查与纠错
- OCR 识别与语音识别
- 垃圾邮件过滤与记录链接
- 重复检测与自然语言翻译辅助
- RNA/DNA 序列比对(生物信息学)
- 抄袭检测
Java 中常用框架如 Hibernate Search、Solr、Elasticsearch 均有相关实现。
在语言学中,Levenshtein 距离也可用于衡量语言或方言之间的差异。
8. 总结
本文我们讨论了多种实现 Levenshtein 距离的算法,并分析了其复杂度。
尽管最坏情况下的时间复杂度为二次方,但通过多种优化策略(如公共前后缀剪枝、设置距离上限、使用近似算法预筛选),我们可以在实际应用中获得可接受的性能。
最后,我们还提到了自动机方法,为模糊匹配提供了另一种高效思路。