1. 概述
在本教程中,我们将介绍学习机器学习和人工智能所需掌握的前置知识。我们会先梳理与机器学习密切相关的三个主要分支:数据科学、机器学习工程和人工智能之间的区别。通过这些区别,我们可以选择不同的职业发展方向。
接着,我们会列出学习机器学习所需掌握的几个核心学科,包括统计学、概率论、线性代数、微积分和编程。这些是机器学习的基石,无论你选择哪个方向都必须掌握。
最后,我们会介绍一些较少被提及但同样重要的替代性方法,如心理学、系统理论、基于代理的建模和复杂性理论。这些知识虽然冷门,但掌握后在职业市场上具有独特优势。
2. 数据科学、机器学习工程与人工智能
虽然在日常交流中,我们经常将“数据科学”、“机器学习”和“人工智能”混用,但它们其实是三个不同的概念。理解它们之间的区别有助于我们做出更清晰的职业规划。
- 数据科学:专注于数据分析和提取人类可理解的洞察
- 机器学习:是软件工程的一个分支,关注构建和优化统计模型和数据流水线
- 人工智能:是一个更广义的术语,指在人工系统中复制人类认知能力的学科
它们之间有交集,但又不完全等同。我们可以用一个维恩图来更直观地表示这种关系:
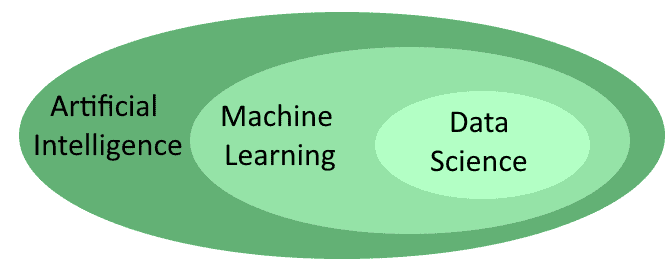
2.1. 各分支的从业人群
- 数据科学家:通常在企业或机构中负责处理大量数据,并从中提取有价值的洞察,帮助管理层做出决策
- 机器学习工程师:是软件工程师,负责构建数据管道、模型训练与部署,是当前AI领域最主流的职业路径
- 人工智能研究人员:多为学术界人士,可能来自计算机科学、心理学、神经科学、哲学等多个领域
2.2. 如何选择方向?
- 数据科学:适合对统计学、数学有浓厚兴趣的人,也适合有经济、市场、社会等背景但希望进入AI领域的人
- 机器学习工程:适合有编程背景、熟悉Python、Java、C++等语言,但不想深入数学理论的开发者
- 人工智能研究:适合对基础研究感兴趣、愿意深入认知科学、心理学等领域的研究人员
无论选择哪个方向,都需要掌握一些基础学科。接下来我们详细看看这些必备知识。
3. 机器学习的传统前置知识
无论你选择数据科学、机器学习工程还是人工智能,以下五门学科是必须掌握的:
✅ 统计学
✅ 概率论
✅ 线性代数
✅ 微积分
✅ 编程
3.1. 统计学
统计学是识别、提取和泛化观察数据中模式的学科。虽然不是所有机器学习都基于统计学,但大多数模型(如回归分析、聚类、假设检验)都依赖统计方法。
机器学习中常见的统计概念包括:
- 观测值、特征、数据集
- 模式提取与统计建模
- 回归分析(如线性回归)
- 神经网络虽然不完全属于统计学,但也广泛使用统计方法
3.2. 统计学与可重复性问题
统计学的一个核心前提是现象必须是可重复的。如果一个现象是唯一的、不可重复的(例如17世纪的超新星爆发),那么就无法使用统计方法进行建模,机器学习也无法处理。
✅ 理解统计学的适用边界,有助于判断机器学习是否适用于某个问题
3.3. 概率论
概率论研究的是不确定事件的发生。机器学习模型(尤其是贝叶斯模型)大量依赖概率论。理解概率论有助于我们判断模型是否适用,以及如何解释模型输出的不确定性。
3.4. 线性代数
线性代数是处理向量、矩阵和张量运算的数学分支。在数据挖掘和统计建模中,我们经常处理矩阵运算,因此线性代数是必须掌握的基础。
✅ 理解矩阵维度、矩阵乘法、特征值、主成分分析(PCA)等内容非常重要
3.5. 微积分
微积分研究的是连续变化的数学。虽然计算机本质上是离散的,但我们通常假设变量是连续的,这样就可以使用微积分工具进行建模。
比如神经网络中的梯度下降(Gradient Descent)就依赖于导数计算。
3.6. 为什么微积分重要?
虽然计算机不能真正处理连续变量,但我们可以近似地使用微积分进行建模。理解导数、偏导数、链式法则等基本概念,有助于我们理解模型训练过程。
⚠️ 初学者只需掌握常见激活函数的导数即可,不需要深入复杂数学理论
3.7. 编程
编程是机器学习的工具,不是最终目标。不同方向对编程能力的要求不同:
- 数据科学家:Python、R
- 机器学习工程师:Python、C/C++
- JVM平台:Java、Scala、Kotlin
- 多智能体仿真:C#(Unity)、NetLogo
✅ 掌握至少一门主流语言,理解数据结构与算法
4. 被忽视但同样重要的替代性方法
除了上述传统知识,还有一些冷门但非常有价值的方向:
4.1. 心理学与认知科学
人工智能起源于对人类认知的研究。神经网络模拟人脑结构,属于“连接主义”(Connectionism);而知识图谱、自然语言处理等则属于“符号主义”(Symbolism)。
✅ 理解人类认知机制,有助于设计更符合人类思维的AI系统
4.2. 系统理论与控制论
系统理论研究的是系统的通用原则,控制论则研究系统内部的反馈与通信机制。
机器学习系统从来不是孤立存在的,它必须嵌入更大的系统中运行(如机器人、社交网络等)。
✅ 系统理论帮助我们理解机器学习系统与环境的交互关系
4.3. 基于代理的建模(Agent-Based Modeling)
代理建模是一种从个体行为出发研究系统整体行为的方法。它强调“智能”是代理与环境交互的结果。
例如:在模拟市场行为时,我们先定义每个个体的目标和感知能力,再观察整体市场行为的涌现。
✅ 适用于研究复杂系统的行为模式
4.4. 复杂性理论与非线性动力学
复杂系统的行为不能简单地通过其组成部分推导出来。例如房价预测模型本身会影响房价,形成反馈循环。
这类系统往往具有非线性特征,传统的线性模型无法准确建模。
✅ 理解复杂系统有助于处理现实世界中动态变化的AI问题
5. 总结
本文我们梳理了机器学习相关的三个主要分支:数据科学、机器学习工程和人工智能,并分析了它们的区别与联系。
我们还详细列出了学习机器学习所需掌握的五个核心学科,并解释了它们的重要性。
最后,我们介绍了几种被忽视但同样重要的替代方法,包括心理学、系统理论、代理建模和复杂性理论。
无论你选择哪个方向,扎实的数学基础和编程能力都是不可或缺的。而掌握一些冷门知识,往往能在职业发展中带来意想不到的优势。