1. 概述
机器学习是通过数学和统计方法,让机器从数据中“学习”规律的一门技术。它主要分为四大类方法:
✅ 监督学习(Supervised Learning)
✅ 半监督学习(Semi-supervised Learning)
✅ 无监督学习(Unsupervised Learning)
✅ 强化学习(Reinforcement Learning)
本文将介绍这些方法的基本概念、适用场景以及它们的工作原理,并通过简单示例帮助理解。
2. 监督学习(Supervised Learning)
监督学习是指使用带标签的数据来训练模型的一种方法。这类数据通常来源于经验,也称为经验数据(empirical data)。在训练前,数据通常需要进行清洗、补全和优化。
举个例子,我们有如下葡萄酒类型的数据集:
| Type | Acidity | Dioxide | pH |
|---|---|---|---|
| white | 0.27 | 45 | 3 |
| red | 0.3 | 14 | 3.26 |
| white | 0.28 | 47 | 2.98 |
| white | 0.18 | 3.22 | |
| red | 16 | 3.17 |
经过数据清洗和标准化后,可能变成如下形式:
| Type | Acidity | Dioxide | pH |
|---|---|---|---|
| 1 | 0.75 | 0.94 | 0.07 |
| 0 | 1 | 0 | 1 |
| 1 | 0.83 | 1 | 0 |
| 1 | 0.52 | 0.86 | 0.67 |
| 0 | 0.68 | 0.06 | 0.68 |
我们通过将“red”和“white”转换为数字标签(0 和 1),并填补缺失值,使数据更适合模型训练。
根据任务目标不同,监督学习又分为两类:
- 分类(Classification):输出是类别标签,如“猫”或“不是猫”
- 回归(Regression):输出是一个具体数值,如预测身高
2.1 分类(Classification)
假设我们有一个包含汽车图片的数据集,目标是识别每张图片是“轿车”、“卡车”还是“面包车”。这种情况下,我们会使用分类模型。
训练时,我们给模型输入大量带标签的图像,模型通过学习这些特征进行分类。测试阶段,模型会处理从未见过的图像,评估其泛化能力。
模型的成熟度通常通过准确率(Accuracy)或损失函数(Loss Function)来衡量。例如,垃圾邮件过滤模型的准确率要求可以较低,而自动驾驶模型则要求极高。
以下是一个简单的分类模型示意图,区分“猫”与“非猫”:
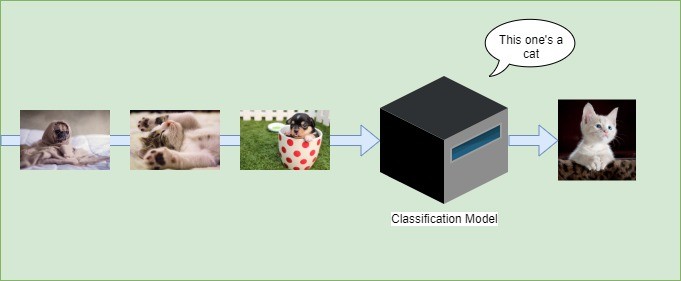
常用分类算法包括:
- 逻辑回归(Logistic Regression)
- 随机森林(Random Forest)
- 决策树(Decision Tree)
- 支持向量机(Support Vector Machine)
- K近邻(K-Nearest Neighbors)
2.2 回归(Regression)
回归模型的输出是一个数值预测值,而不是类别标签。例如,我们可以通过年龄预测身高,这就是一个典型的回归任务。
训练方式与分类类似,也需要训练集和测试集。区别在于输出是一个连续值,而不是离散的类别。
以下是一个线性回归模型的示意图,预测身高与年龄的关系:
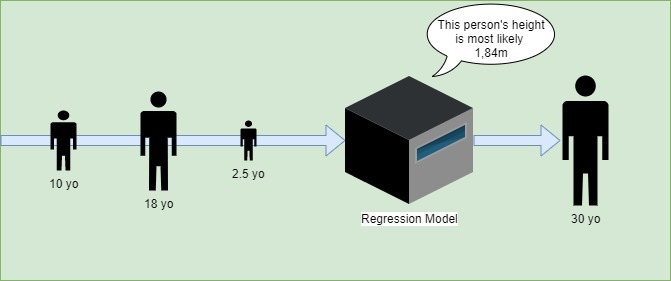
常用回归算法包括:
- 线性回归(Linear Regression)
- 随机森林回归(Random Forest Regressor)
- 决策树回归(Decision Tree Regressor)
- 支持向量回归(Support Vector Regressor)
- K近邻回归(KNN Regressor)
3. 无监督学习(Unsupervised Learning)
与监督学习不同,无监督学习使用的是无标签数据。这类数据通常难以获得标签,要么是因为知识不足,要么是标注成本太高。
由于没有标签,无法像监督学习那样直接评估模型效果,但仍然可以通过一些方法发现数据中的隐藏模式。
3.1 聚类(Clustering)
聚类的目标是将数据分成若干组(称为“簇”),每组内的数据具有相似特征。这种技术常用于客户分群、图像分割等场景。
例如,我们有一组汽车数据,虽然没有标签,但聚类算法可以自动将它们按颜色分组:
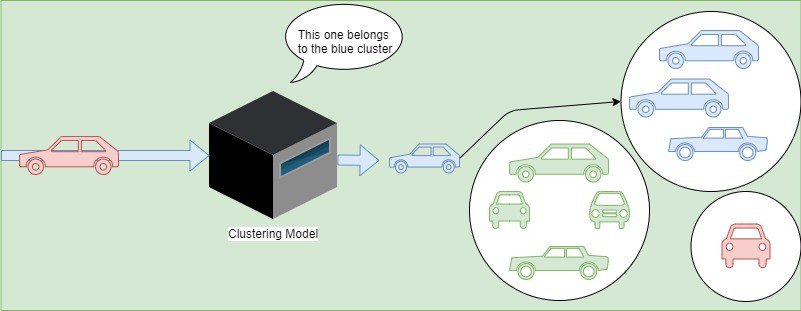
常见聚类算法包括:
- K均值(K-Means Clustering)
- 层次聚类(Hierarchical Clustering)
3.2 降维(Dimensionality Reduction)
降维的目标是减少数据集的特征数量,同时保留关键信息。这样可以提升模型训练效率,避免“维度灾难”。
例如,两个特征可能提供相同的信息(如“体重(kg)”和“体重(磅)”),降维算法会识别并去除冗余信息。
降维后的数据集更简洁,便于后续建模:
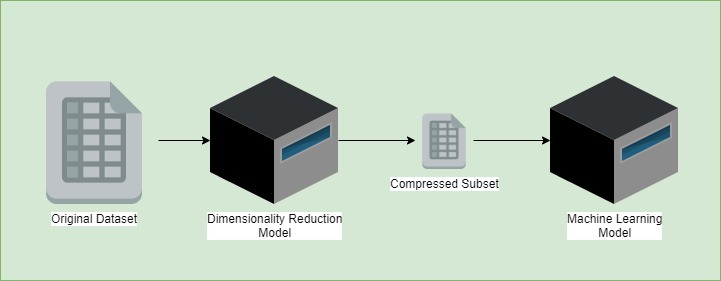
常见降维算法包括:
- 主成分分析(PCA)
- 线性判别分析(LDA)
- 核主成分分析(Kernel PCA)
- 广义判别分析(GDA)
4. 半监督学习(Semi-supervised Learning)
半监督学习结合了监督学习和无监督学习的特点:数据集部分有标签,部分无标签。
这种方法通常用于数据标注成本高或数据质量差的场景。比如医学影像中,医生标注癌症图像是一项昂贵且耗时的工作,因此只标注了一部分图像。
半监督模型通过利用少量带标签数据和大量未标注数据,仍然可以实现较好的准确率。
下图展示了医生标注部分数据,其余为未标注数据的场景:

5. 强化学习(Reinforcement Learning)
强化学习是一种通过试错与环境交互来学习策略的方法。模型根据执行动作后获得的奖励(Reward)或惩罚(Punishment)来调整行为。
例如,一个玩电子游戏的AI模型,每次得分时获得正向奖励,失败时获得负向惩罚。模型通过不断试错,学习最优策略。
强化学习的核心是构建短期与长期奖励机制,从而形成策略。
模型会随着每次动作和反馈不断进化,最终学会完成任务并最大化奖励。
下图展示了强化学习的基本流程:
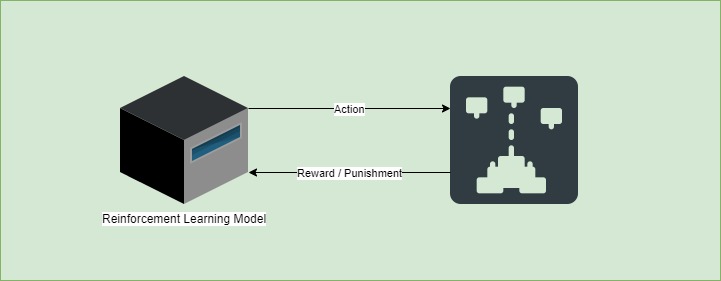
常见强化学习算法包括:
- SARSA(State-Action-Reward-State-Action)
- Q-Learning
- 汤普森抽样(Thompson Sampling)
- 置信区间上界(Upper Confidence Bound)
- 蒙特卡洛树搜索(Monte Carlo Tree Search)
6. 如何选择合适的学习方法?
没有一种“万能算法”,每种方法都有其适用场景和局限性。选择方法时应考虑以下因素:
- ✅ 问题类型:分类?回归?聚类?还是策略优化?
- ✅ 数据量:数据是否足够?是否需要半监督或强化学习?
- ✅ 模型复杂度 vs 数据量:模型太复杂但数据太少容易过拟合
- ✅ 预期准确率:对精度要求高,可能需要更复杂的模型和更长时间训练
例如,朴素贝叶斯、K近邻、线性SVM等算法在小数据集上表现良好;而深度学习模型则需要大量数据。
7. 总结
本文介绍了机器学习的四大类方法:监督学习、无监督学习、半监督学习和强化学习。虽然它们的应用场景和实现方式各不相同,但核心思想都基于数学与统计方法。
理解这些方法的差异与适用性,是构建有效机器学习系统的前提。在实际项目中,往往需要根据问题背景、数据情况和资源限制进行权衡和选择。