1. 引言
在某些机器学习应用中,我们希望定义一系列步骤来解决特定问题。例如,一个机器人试图穿越布满障碍和墙壁的迷宫,最终找到出口。我们的模型关注点在于,如何定义一个从初始状态到目标状态的完整动作序列。
这类问题通常由强化学习(Reinforcement Learning, RL)这一子领域处理,它利用马尔可夫决策过程(Markov Decision Process, MDP)来建模其部分架构。强化学习的一个挑战就是找到一个最优策略来完成我们的任务。
在本教程中,我们将先介绍马尔可夫模型的基础知识,然后解释为何使用一个叫做“值迭代(Value Iteration)”的算法来寻找这个最优解是合理的。
2. 马尔可夫模型
为了建模样本之间的依赖关系,我们使用马尔可夫模型。在这种模型中,输入是一系列由参数化随机过程生成的动作序列。
本文中我们采用如下记号:一个系统有 N 个可能状态 $ S_1, S_2, ..., S_N $,在时间 $ t=1,2,... $ 时系统处于状态 $ q_t $。等式 $ q_3 = S_2 $ 表示在时间 3 时系统处于状态 $ S_2 $。
注意:这里的下标 $ t $ 表示时间,但它也可以是其他维度,比如空间。
那么,我们如何表示系统中所有状态之间的关系呢?答案就是使用马尔可夫建模策略。
2.1 理论基础
如果我们在时间 $ t $ 处于状态 $ S_i $,那么在时间 $ t+1 $ 时进入状态 $ S_j $ 的概率是:
$$ P(q_{t+1}=S_j | q_t=S_i, q_{t-1}=S_k, ...) $$
为了让模型更简单,我们假设只有前一个状态影响下一个状态,而不是所有前面的状态。也就是说,只有当前状态对下一个状态有影响,这就是一阶马尔可夫模型:
$$ P(q_{t+1}=S_j | q_t=S_i) $$
进一步简化模型,我们去掉时间依赖性,定义从状态 $ S_i $ 转移到 $ S_j $ 的转移概率为:
$$ a_{i,j} = P(q_{t+1}=S_j | q_t=S_i) $$
理解这些概念最简单的方式是通过一个两个状态的马尔可夫模型图:
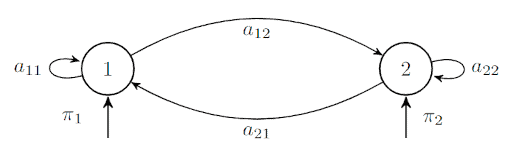
变量 $ \pi_i $ 表示从状态 $ i $ 开始的概率。由于我们已经去除了时间依赖性,所以在任何时刻,从状态 1 转移到状态 2 的概率始终为 $ a_{12} $,无论 $ t $ 是多少。
此外,对于某个给定状态 $ S_i $ 的转移概率必须满足:
$$ \sum_{j=1}^{N} a_{ij} = 1 $$
对于 $ \pi_i $ 的情况也有类似条件,因为所有初始状态的概率总和应为 100%:
$$ \sum_{i=1}^{N} \pi_i = 1 $$
最后,如果我们知道所有状态 $ q_t $,那么输出就是从初始状态到终止状态的状态序列,我们称之为观察序列 $ O $。该序列的概率可以这样计算:
$$ P(O=Q|\boldsymbol{A,\Pi}) = P(q_1) \prod_{t=2}^{T} P(q_t|q_{t-1}) = \pi_{q_1} a_{q_1 q_2} ... a_{q_{T-1} q_T} $$
其中 $ \boldsymbol{\Pi} $ 表示初始概率的总和,$ \boldsymbol{A} $ 是转移概率的向量。$ \pi_{q_1} $ 表示从状态 $ q_1 $ 开始的概率,而 $ a_{q_1 q_2} $ 表示从 $ q_1 $ 转移到 $ q_2 $ 的概率。
举个例子,假设 $ \pi_1=0.7 $,$ \pi_2=0.3 $,并定义如下转移概率:
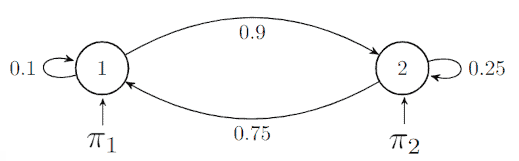
我们考虑观察序列为 $ O = {1, 2, 2} $,其概率为:
$$ P(O=Q|\boldsymbol{A,\Pi}) = P(q_1) \cdot P(q_2|q_1) \cdot P(q_2|q_2) $$
代入已知值:
$$ = \pi_1 \cdot a_{12} \cdot a_{22} = 0.7 \cdot 0.9 \cdot 0.25 = 0.1575 $$
2.2 隐马尔可夫模型(HMM)
在上面的例子中,所有状态都是可观测的,因此称为可观测状态。当状态不可观测时,就称为隐马尔可夫模型(Hidden Markov Model, HMM)。
要定义一个状态的概率,我们需要先访问该状态,然后记录观测值的概率。一个好的 HMM 模型应该能够使用真实世界的数据来模拟源数据。
在 HMM 中,我们有两个随机性来源:
- 状态的观测值
- 状态之间的转移
我们通常会遇到两个主要问题:
- 给定模型 $ \lambda $,我们希望计算 $ P(O|\lambda) $,即任意观测序列的概率
- 找到生成该观测序列的最可能状态序列
3. 强化学习
正如引言中所述,某些机器学习问题的解决方案应是一系列动作,而不是一个数值或标签。
在强化学习中,有一个决策主体(agent)负责在环境中选择动作。
3.1 示例
在任意给定状态下,agent 会采取动作,环境会返回奖励或惩罚。一系列动作称为策略(policy),强化学习的核心目标就是找到一个最优策略以最大化总奖励。
回到机器人穿越迷宫的例子,机器人就是学习 agent,迷宫就是环境:
我们可以类比马尔可夫模型,因为这个问题的解也是一系列动作。
马尔可夫决策过程用于建模 agent,因为 agent 会生成一系列动作。在现实世界中,状态可以是可观测的、隐藏的或部分可观测的,取决于应用场景。
3.2 数学模型
我们假设 agent 在离散时间 $ t $ 处于状态 $ s_t $,所有可能状态集合记为 $ S $。可用动作集合记为 $ A(s_t) $,执行动作后从 $ s_t $ 转移到 $ s_{t+1} $,并获得奖励 $ r_{t+1} $。
如前所述,这是一个一阶马尔可夫模型,因为下一个状态和奖励只依赖于当前状态和动作。
我们定义策略 $ \pi $ 是状态到动作的映射 $ \pi: S \to A $。如果我们在状态 $ s_t $,策略会指示应采取的动作。
策略的价值 $ V^\pi(s_t) $ 是从该状态开始的所有奖励的期望值:
$$ V^\pi(s_t) = E[r_{t+1} + r_{t+2} + \ldots + r_{t+T}] = E\left[ \sum_{i=1}^{T} r_{t+i} \right] $$
如果步骤数 $ T $ 未定义,我们使用一个折扣因子 $ \gamma $ 来惩罚未来奖励:
$$ V^\pi(s_t) = E[r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \ldots] = E\left[ \sum_{i=1}^{\infty} \gamma^{i-1} r_{t+i} \right] $$
我们的目标是找到最优策略 $ \pi^* $,使累积奖励最大化:
$$ V^*(s_t) = \max : V^\pi(s_t), \forall s_t $$
我们也可以使用状态-动作对来表示采取某个动作的影响:
$$ V^*(s_t) = \max : Q^*(s_t, a_t) $$
$$ V^*(s_t) = \max \left( E[r_{t+1}] + \gamma \sum_{s_{t+1}} P(s_{t+1}|s_t,a_t) V^*(s_{t+1}) \right) $$
$$ Q^*(s_t,a_t) = E[r_{t+1}] + \gamma \sum_{s_{t+1}} P(s_{t+1}|s_t,a_t) \max : Q^*(s_{t+1},a_{t+1}) $$
4. 值迭代
最后,为了找到给定场景下的最优策略,我们可以使用上述定义的价值函数和一个称为“值迭代”的算法,该算法能保证模型收敛。
该算法是迭代的,持续执行直到连续两次迭代 $ l $ 和 $ l+1 $ 的最大差异小于一个阈值 $ \delta $:

我们来看一个值迭代算法模拟环境的简单例子。
整个地图是一个 $ 6 \times 6 $ 的网格,但我们只考虑一个 $ 3 \times 3 $ 的子区域,中心有一个奖励值 50,初始值设为 0。
机器人可以采取四个动作:上、下、左、右。如果它撞到右边的墙,会受到 20 的惩罚:
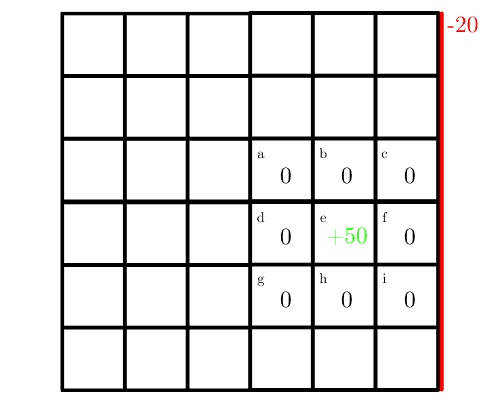
这是一个随机模型,每个动作都有概率。机器人有 70% 的概率按指定方向移动,其他三个方向各 10%。
如果 agent 决定向上移动,有 70% 概率向上,10% 概率向下、向左或向右。只有在动作完成后才会获得奖励,而不是在转移过程中。
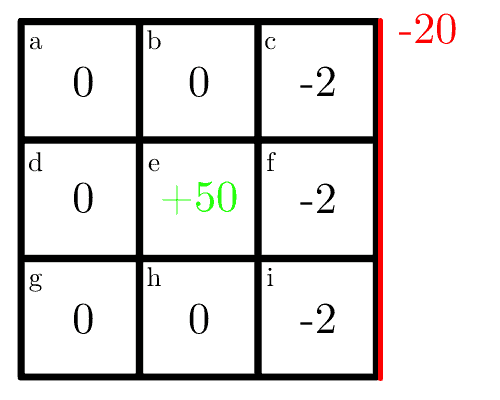
第一次迭代中,每个格子接收其即时奖励。例如,格子 c 的最优动作是向下,有 10% 概率撞墙,即时奖励为 $ 0.1 \times 20 = -2 $,地图变为:
接下来我们使用折扣因子 $ \gamma = 0.9 $。在第二次迭代中,我们先看格子 f,其最优动作是向左:
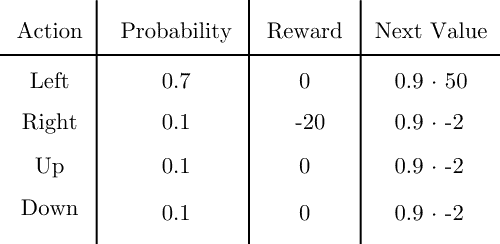
状态值为奖励与下一状态值乘以概率的总和:
$$ 0.7 (0 + 0.9 \times 50) + 0.1(-20 + 0.9 \times -2) + 0.1(0 + 0.9 \times -2) + 0.1(0 + 0.9 \times -2) = 31.5 - 2.18 - 0.18 - 0.18 = 28.96 $$
类似地,格子 d 的最优动作是向右,其他方向预期奖励为 0,状态值为:
$$ 0.7 (0 + 0.9 \times 50) = 31.5 $$
计算所有格子后,地图变为:
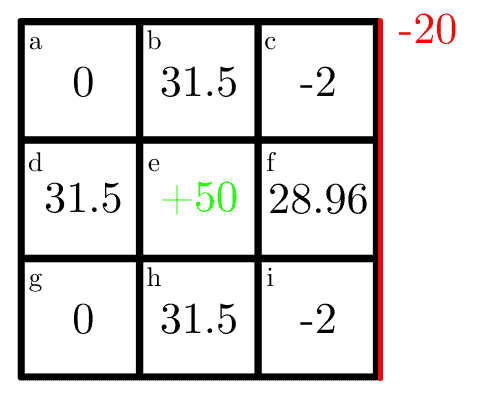
我们只进行了两次迭代,但该算法会持续进行,直到达到指定的迭代次数或阈值。
5. 结论
在本文中,我们讨论了如何实现一个动态规划算法来寻找强化学习问题的最优策略,即值迭代策略。
这是非常重要的一个话题,因为在这个模型中最大化奖励是许多现实应用的核心。由于该算法能保证找到最优值并收敛,因此在实现我们的解决方案时应优先考虑。