1. 概述
Merge Sort 是一种经典的分治排序算法,因其高效稳定而被广泛使用。本文将对比其两种实现方式:Top-Down(自顶向下) 和 Bottom-Up(自底向上)。
我们会分别介绍两种实现的原理、伪代码、时间与空间复杂度,并通过图示帮助理解。虽然两者最终效果一致,但在实现方式和资源使用上存在明显差异。
2. 自顶向下(Top-Down)实现
自顶向下方式基于递归,是 Merge Sort 的标准实现。其基本思想是:
✅ 将数组不断二分,递归排序左右两半,最后合并结果。
这种实现方式从数组的“顶部”开始,逐层向下拆分,直到子数组只剩一个元素,然后开始向上合并。
2.1 工作原理图示
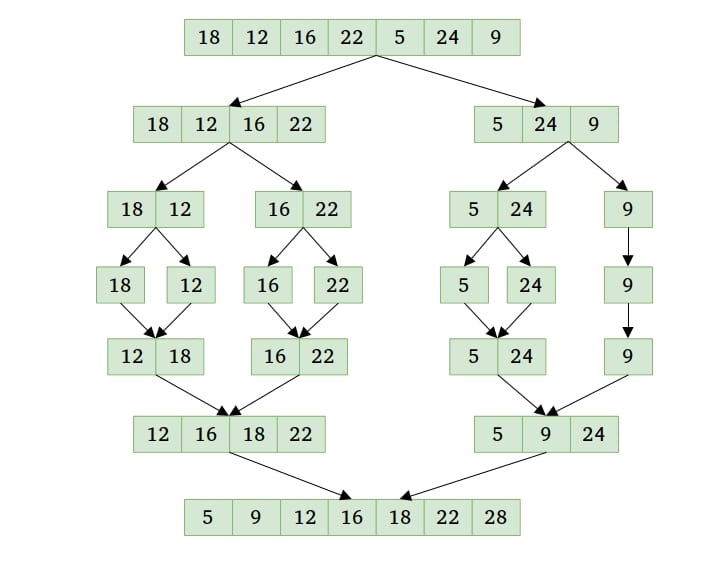
图中展示了数组 [5, 2, 4, 7, 1, 3, 2, 6] 的完整排序过程。可以看到,数组被不断二分,直到不能再分,再逐层合并。
2.2 伪代码
algorithm TopDownMergeSort(S):
// INPUT
// S = sequence with n elements
// OUTPUT
// sorted sequence S
if S.size > 1:
(S1, S2) <- partition(S, n/2)
TopDownMergeSort(S1)
TopDownMergeSort(S2)
S <- merge(S1, S2)
2.3 时间与空间复杂度
时间复杂度:
O(n log n)
无论输入数据如何,每次拆分都是log n层,每层合并耗时O(n)。空间复杂度:
O(n log n)
递归调用栈深度为log n,每次合并需要额外的O(n)空间,因此总空间为O(n log n)。
⚠️ 注意:递归调用可能导致栈溢出,尤其在处理非常大的数组时。
3. 自底向上(Bottom-Up)实现
Bottom-Up 实现使用迭代而非递归,是 Merge Sort 的非递归版本。
✅ 从最小单位(单个元素)开始,逐步合并相邻有序段,直到整个数组有序。
这种方式不需要递归调用,避免了栈溢出风险,更适合在内存受限或递归深度受限的环境中使用。
3.1 工作原理图示
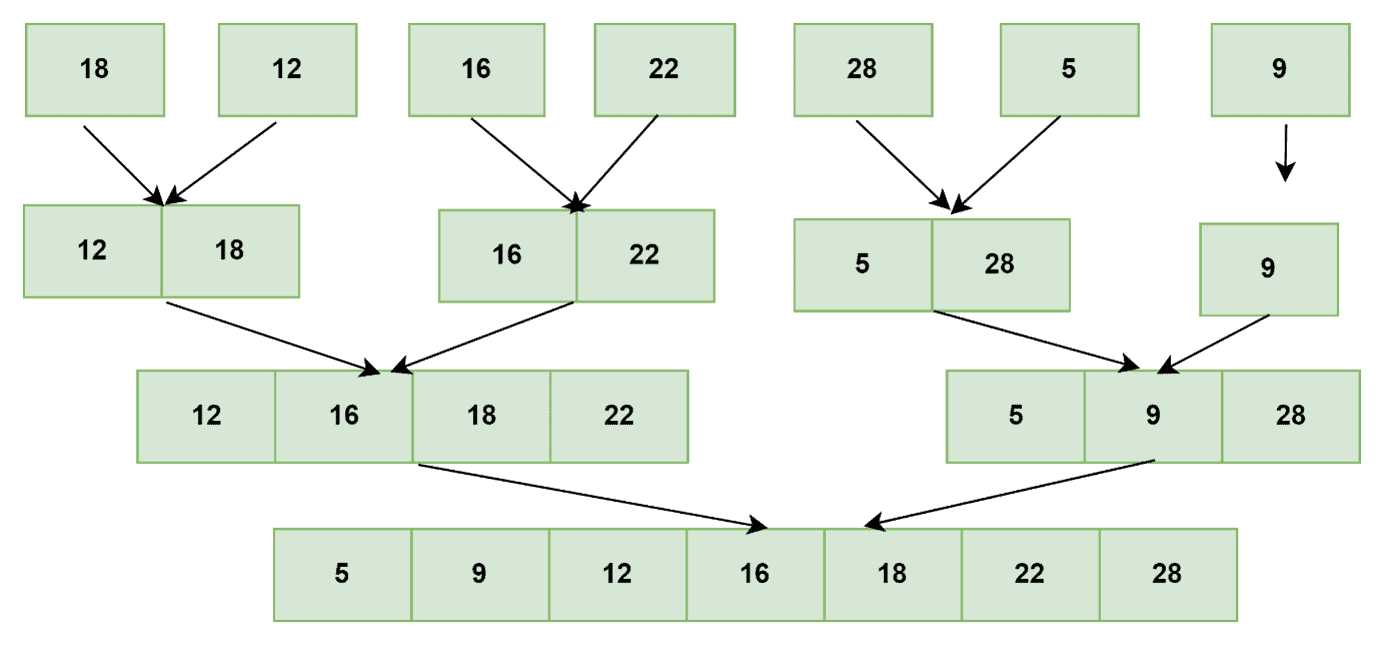
图中展示了数组 [5, 2, 4, 7, 1, 3, 2, 6] 的迭代排序过程。可以看到,初始每次合并两个元素,然后是四个,依此类推。
3.2 伪代码
algorithm BottomUpMergeSort(S, n):
// INPUT
// S = sequence with n elements
// OUTPUT
// sorted sequence S
if n < 2:
return
i <- 1
while i < n:
j <- 0
while j < n - i:
if n < j + i * 2:
merge(A + j, A + j + i, A + n)
else:
merge(A + j, A + j + i, A + j + i * 2)
j += i * 2
i = i * 2
3.3 时间与空间复杂度
时间复杂度:
O(n log n)
每次合并操作需要遍历整个数组,共需log n轮合并。空间复杂度:
O(n)
只需要一个临时数组用于合并,不依赖递归栈,因此空间效率更高。
✅ 优势总结:
- 无需递归调用,减少栈溢出风险
- 空间更优(
O(n)vsO(n log n)) - 更适合嵌入式系统或大数组排序
4. 总结与选择建议
| 特性 | Top-Down | Bottom-Up |
|---|---|---|
| 实现方式 | 递归 | 迭代 |
| 空间复杂度 | O(n log n) |
O(n) |
| 时间复杂度 | O(n log n) |
O(n log n) |
| 适用场景 | 简单实现、教学 | 工业级、内存敏感环境 |
✅ 推荐:
- 学习/教学时使用 Top-Down,逻辑清晰,便于理解。
- 实际开发/嵌入式环境使用 Bottom-Up,性能更稳定,资源占用更少。
⚠️ 踩坑提醒:
- 使用 Top-Down 时注意递归深度限制,尤其在处理大数据集时。
- Bottom-Up 实现稍复杂,合并逻辑需仔细处理边界条件。
如果你希望看到 Java 或其他语言的完整实现代码,请告诉我,我可以继续补充。