1. 简介
在训练机器学习(ML)模型时,我们通常需要设定一组超参数(hyperparameters),以确保模型在测试集上达到较高的准确率。
这些超参数包括学习率(learning rate)、权重衰减(weight decay)、网络层数、以及 batch size(批量大小)等。
在本教程中,我们将探讨两种主要的 batch 使用方式:
- 使用整个训练集作为一个 batch 来更新模型参数(Batch Gradient Descent)
- 使用 mini-batch(小批量)来逐步更新模型参数
最后,我们还会使用 TensorFlow 展示如何实现不同类型的梯度下降方法。在此之前,我们先回顾一下模型更新的基本原理。
2. 梯度下降原理
在深度学习中,大多数问题都可以被建模为优化问题:我们的目标是最大化或最小化某个函数。其中,最小化问题在 ML 中更为常见,我们通常称该函数为损失函数(loss function)。
如何找到损失函数的最小值?
最常用的方法是梯度下降(Gradient Descent)。其核心思想是利用函数在某一点的导数(即梯度)来判断函数值是上升还是下降,并据此调整参数方向。
以一个简单的二次函数为例:
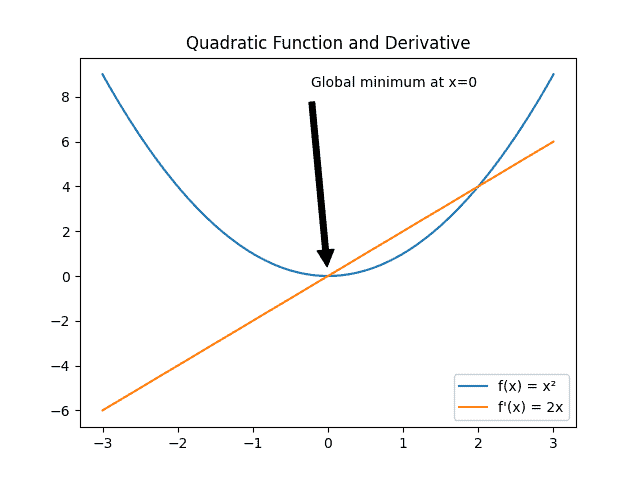
假设我们要找到函数 $ f(x) = x^2 $ 的最小值。
我们从 $ x = -2 $ 开始,计算该点的导数:
$$ f'(-2) = 2 \times (-2) = -4 $$
此时导数为负,说明我们应该向正方向移动一步。
如果我们移动步长为 3,就会到达 $ x = 1 $,再次计算导数:
$$ f'(1) = 2 \times 1 = 2 $$
此时导数为正,说明应该向负方向移动。
只要步长合适,经过多次迭代后,我们最终会收敛到全局最小值 $ x = 0 $。
⚠️ 注意:如果步长太大,我们可能会在最小值附近来回跳动,永远无法收敛;而如果步长太小,则收敛速度会非常慢。
这个步长,就是我们常说的 学习率(learning rate)。
3. Batch Size 的影响
在梯度下降过程中,我们可以通过不同的方式来更新模型参数,其中 batch size 的选择对模型的性能和收敛速度有显著影响。
3.1. 批量梯度下降(Batch Gradient Descent)
批量梯度下降(Batch GD)是最直接的方式:每次更新模型参数时都使用整个训练集。
✅ 优点:
- 每次更新都基于完整的数据集,因此损失函数曲线较为平滑,噪声较少
❌ 缺点:
- 对内存要求高,尤其是当训练集非常大时(比如几十万甚至上百万条数据)
- 更新频率低,容易陷入局部最优或鞍点(saddle point)
3.2. 小批量梯度下降(Mini-Batch Gradient Descent)
Mini-Batch GD 是目前最常用的方式:每次使用一个子集(mini-batch)来更新模型参数。
✅ 优点:
- 更新频率高,能更有效地跳出局部最优
- 内存占用适中,适合大多数实际应用场景
❌ 缺点:
- 每个 batch 的样本分布可能不同,导致损失函数波动较大
3.3. 随机梯度下降(Stochastic Gradient Descent, SGD)
SGD 是一种极端情况的 mini-batch 方法:每次只使用一个样本更新模型参数。
✅ 优点:
- 参数更新频率极高,能快速获得模型性能的初步反馈
- 更容易跳出局部最优,找到全局最优解
❌ 缺点:
- 更新方向噪声大,模型在训练过程中波动较大
- 收敛速度慢,尤其在复杂模型和大数据集上表现不佳
4. TensorFlow 示例演示
为了更直观地展示不同 batch size 对训练效果的影响,我们使用 TensorFlow 实现一个卷积神经网络(CNN)来识别 MNIST 手写数字。
训练集:54000 张 24×24 图像
验证集:6000 张
测试集:10000 张
我们尝试三种不同的 batch size:
| 类型 | Batch Size |
|---|---|
| Batch GD | 27000(受限于内存) |
| Mini-Batch GD | 128 |
| SGD | 1 |
调用训练时,只需调整 batch_size 参数:
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
下图展示了不同 batch size 的准确率与损失曲线对比:
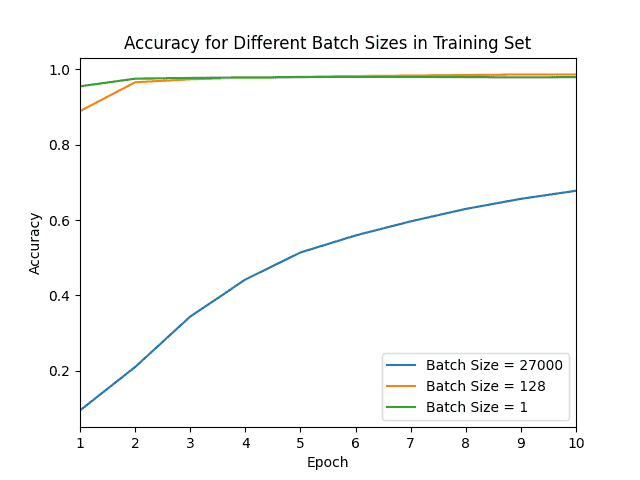
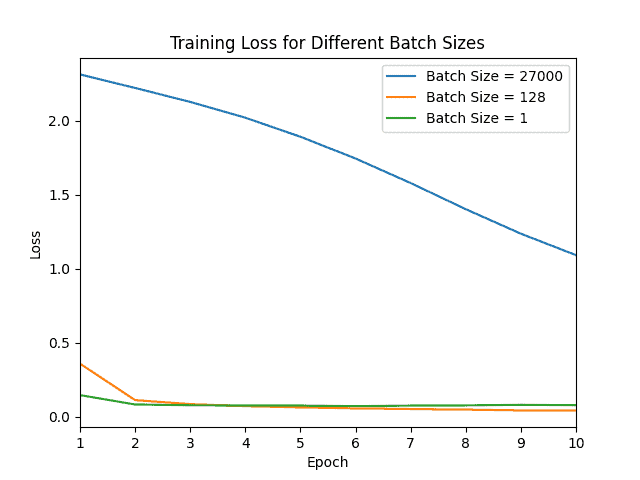
可以看到:
- 使用 batch size = 27000(近似 Batch GD)时,损失最大,准确率最低
- Mini-Batch 和 SGD 在前两个 epoch 就接近了最大准确率,说明它们能更快地反映模型性能
这说明:
- Batch GD 虽然稳定,但更新频率低,收敛慢
- Mini-Batch 和 SGD 虽然噪声大,但更适合大数据集和非凸优化问题
5. 总结
选择合适的 batch size 是一项重要的调参工作,没有统一的标准。以下是一些经验建议:
✅ 适合使用 Batch GD 的场景:
- 损失函数是凸函数(convex)
- 数据量较小,内存足够
✅ 适合使用 Mini-Batch 或 SGD 的场景:
- 数据量巨大,且损失函数可能有多个局部最优
- 需要更快地了解模型性能,便于早期调优
⚠️ 踩坑提醒:
- 不要盲目使用 SGD,虽然更新快,但容易震荡,训练不稳定
- 太大的 batch size 容易导致模型陷入局部最优,且对内存要求高
总之,mini-batch 是大多数实际场景下的首选方式,它在训练速度和模型性能之间取得了良好的平衡。