1. 概述
在人工智能和博弈论领域,我们经常遇到搜索类问题。这类问题通常可以用一个图来表示,图中每个节点代表一种可能的状态,节点之间通过边连接。
智能体(Agent)需要评估每个节点,从而在图中“走”出一条路径,到达一个尽可能好的状态(最优或次优)。
但有些问题无法直接使用传统的图搜索算法解决。本文将介绍这类问题,并深入讲解一个经典解决方案 —— Minimax 算法。
2. 算法简介
Minimax 是一种用于对抗性问题的简单但有效的算法。所谓对抗性问题,通常指的是多智能体系统,每个智能体在决策时都要考虑对手可能采取的策略。
在两人博弈中,一个玩家(称为 Max)希望最大化自己的收益,而另一个玩家(称为 Min)则试图最小化对方的收益。这个过程通过一个效用函数(Utility Function)来衡量每个状态的价值。
这也正是 Minimax 名字的由来:Max 玩家试图最大化收益,而 Min 玩家则试图最小化它。
3. 示例解析
我们通过一个简单例子来理解 Minimax 的工作原理。假设 Max 和 Min 在玩一个树状博弈游戏,如下图所示:
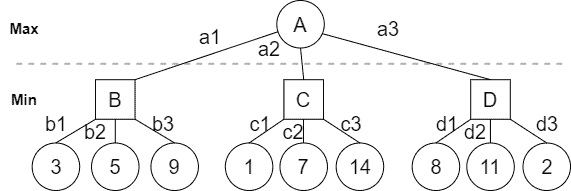
其中圆圈表示 Max 的回合,方块表示 Min 的回合,叶子节点表示游戏结束,下方数字是效用值。
我们从叶子节点开始向上回溯,根据当前玩家是 Max 还是 Min 来决定该节点的值:
- 如果 Max 选择节点 B,Min 会选择 b₁(值为 3),因为这是 Min 能获得的最小值;
- 如果 Max 选择 C,Min 会选择 c₁(值为 1);
- 如果 Max 选择 D,Min 会选择 d₃(值为 2);
因此,各节点值如下:
B = min(3, 5, 9) = 3
C = min(1, 7, 14) = 1
D = min(8, 11, 2) = 2
最后,Max 会从 B、C、D 中选择最大值,即:
A = max(B, C, D) = max(3, 1, 2) = 3
所以 Max 会选择 B,Min 会选择 b₁,最终效用值为 3。
4. 算法实现细节
Minimax 本质上是一个深度优先搜索(DFS)算法,非常适合用递归实现。以下是其伪代码实现:
algorithm RecursiveMinimax(S, Maximizing = True):
// S: 当前状态节点
// Maximizing: 当前是否为 Max 玩家回合
if S 是叶子节点:
return Utility(S)
if Maximizing:
v = -∞
for 每个子节点 child in S:
v = max(v, RecursiveMinimax(child, false))
return v
else:
v = +∞
for 每个子节点 child in S:
v = min(v, RecursiveMinimax(child, true))
return v
时间复杂度分析
- 假设树的深度为
d,每个节点有n个子节点。 - 则总节点数为
n^d,时间复杂度为 **O(n^d)**。
这意味着在实际应用中,比如国际象棋、围棋等复杂博弈中,Minimax 会非常慢,甚至无法完成。
5. 优化策略:Alpha-Beta 剪枝
为了解决 Minimax 的性能问题,引入了 Alpha-Beta 剪枝(Alpha-Beta Pruning)技术。其核心思想是:提前剪掉那些不可能影响最终结果的子树分支,从而减少递归次数。
示例说明
再次看前面的例子:
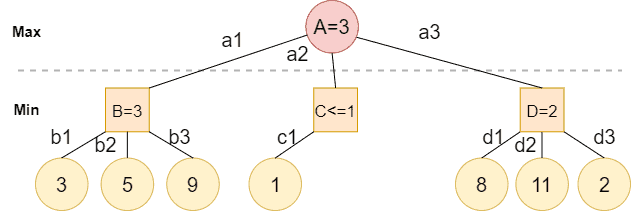
- Max 先评估节点 B,得到值为 3;
- 接下来评估节点 C,发现第一个子节点值为 1;
- 此时可以判断 C 的最终值不会超过 1;
- 因为 Max 已知 B 的值为 3,大于 1,所以 C 的后续子节点可以跳过,无需再评估。
这样就跳过了两个节点,节省了计算时间。
实际效果
在复杂博弈中,Alpha-Beta 剪枝可以将 Minimax 的性能提升 接近两倍,从而使得搜索深度大大增加。
6. 局限性与改进方向
尽管 Alpha-Beta 剪枝可以显著提升性能,但 Minimax 仍存在以下限制:
✅ 优点:
- 适用于状态有限、可穷举的博弈场景;
- 逻辑清晰,易于实现;
❌ 缺点:
- 指数级时间复杂度 O(n^d),不适用于深度或分支因子极大的场景;
- 无法处理随机性问题(如掷骰子);
- 对于复杂游戏(如围棋)效率低下;
改进方向
为应对这些问题,研究者提出了以下方案:
- 使用启发式函数(Heuristic)估算非叶子节点的价值,从而限制搜索深度;
- 引入蒙特卡洛树搜索(MCTS)等随机采样方法;
- 结合深度学习模型预测节点价值,如 AlphaGo 使用的策略网络和价值网络。
7. 总结
Minimax 是博弈搜索中最基础、最经典的算法之一。它通过模拟双方玩家的最优策略,找出当前状态下的最佳决策路径。
虽然存在性能瓶颈,但结合 Alpha-Beta 剪枝后,可以在实际中广泛使用。对于更复杂的问题,需要引入启发式评估和随机搜索策略。
掌握 Minimax 及其优化方法,是进入博弈 AI 领域的第一步,也是构建更复杂智能决策系统的基础。