1. 概述
在本篇文章中,我们将从基础理论出发,探讨未标记数据(unlabeled data)与标记数据(labeled data)之间的区别与相似之处。
学习完本文后,你将理解这两类数据之间的本质差异,以及在不同任务中如何选择使用其中一种。我们将从一个不常见的角度切入,帮助你更深入理解先验知识(prior knowledge)与数据收集之间的关系。
2. 数据、信息与知识
我们先从一个通用 AI 系统的构建思路谈起,看看是否能从中推导出为何需要对数据进行标记。如果可以,那说明数据是否被标记并非由具体任务决定,而是由系统的贝叶斯先验(Bayesian prior)所决定。
2.1. 机器学习系统的概念架构
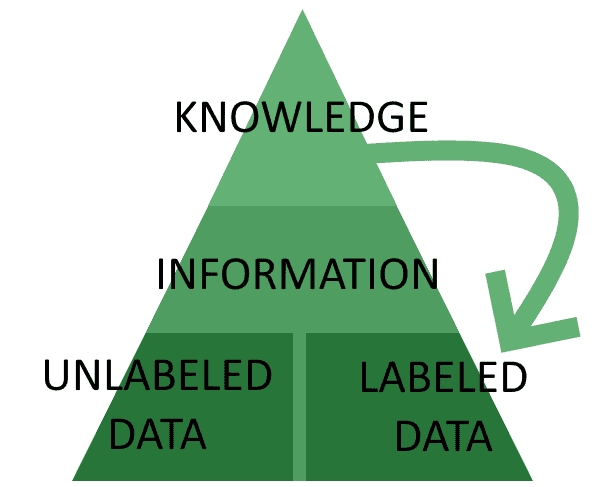
传统的 AI 系统开发架构中,常将数据、信息和知识分层排列,形成所谓的“知识金字塔”(DIK 金字塔):
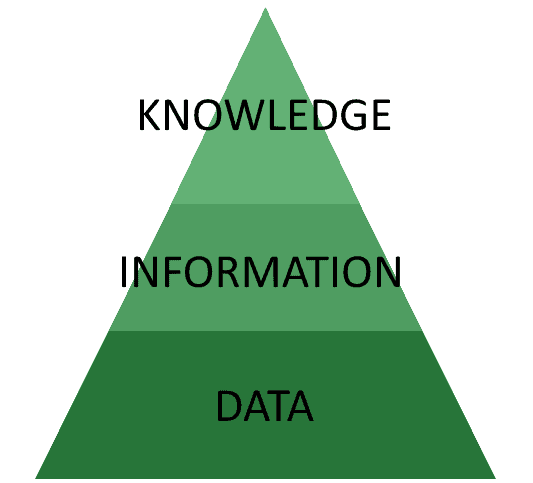
这个结构通常被称为“知识金字塔”或“DIK 金字塔”(Data-Information-Knowledge)。尽管这一模型在学术界存在争议,但它依然是 AI 系统开发中常用的理论框架。
在这个模型中,AI 系统通过将数据聚合为信息,再提取知识,最终指导后续的数据收集。
接下来我们将进一步拆解这个模型的核心组成部分。
2.2. 数据与测量
金字塔的最底层是数据,它是机器学习系统与现实世界之间的桥梁。我们可以将数据理解为传感器采集的原始测量值或观测值,形式上是未加工或未结构化的。
例如:
- 包含数字的矩阵
- 文本字符串
- 分类值的列表
- 音频采样频率
在这个语境下,“数据”指的就是数据结构中包含的值或值集合。
我们稍后会进一步区分本文讨论的两类数据。
2.3. 信息与数据聚合
数据可以通过多种方式进行聚合,从而提取出其中的模式(patterns)。这些模式指的是数据分布中的规律性,通常通过数学或统计模型来识别:
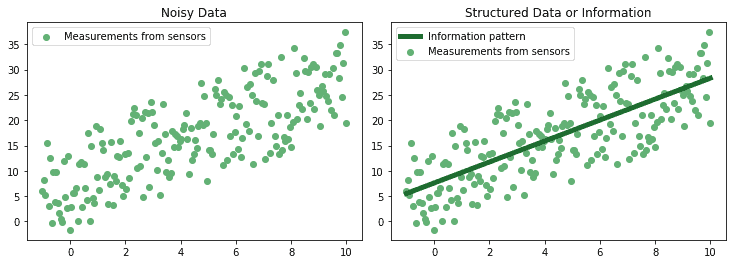
这些反映数据规律的模式通常被称为“信息”。
✅ 信息比原始数据更能概括现实世界的复杂性,因此它位于金字塔的更高层。
✅ 另一种理解方式是:信息或数据模式允许我们对未来测量结果进行预测,而原始数据本身无法做到这一点。
2.4. 知识与信息的关系
一旦从数据中提取出模式,就可以用它们来预测系统行为所导致的未来世界状态。例如,我们发现自由落体物体的位置随时间变化的模式:
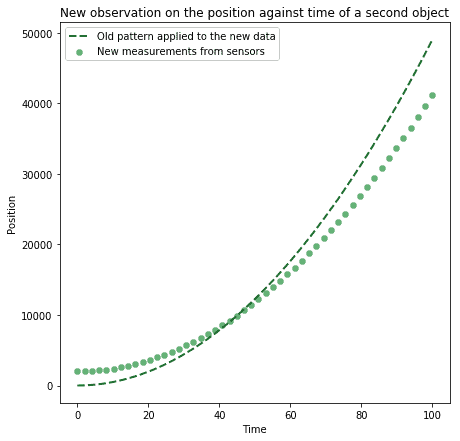
识别出自由落体运动的合适模式后,我们可以做到两件事:
- 预测自由落体物体的未来位置
- 推动物体使其以任意设定的速度下落
然后我们可以将这种模式推广到未来未见过的情况。一旦我们学习到自由落体物体的位置随时间变化的方式,我们就可以假设:如果某个物体的位置随时间变化的方式与该模式足够相似,那么它也是自由落体:
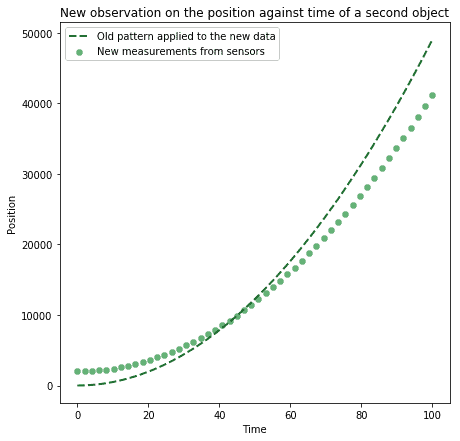
最后,我们可以将代表相同现实世界现象的数据归为一类。如果我们这样做了,就是在为数据分配标签(label),从而可以以可预测和已知的方式对其进行操作。
2.5. 知识与标签之间的关系
正如上面所讨论的,知识对应于对世界运作方式的先验假设。这种假设反过来塑造了我们对尚未进行或已经进行的测量结果的预期。
当我们或机器学习系统进行数据收集时,我们可以使用这些知识来提前预测数据的某些特征。这些特征来源于我们对世界的总体认知或其运作方式。在这种情况下,我们可以说我们从知识中提取了我们假设数据具有的某些特征。
我们也可以用贝叶斯术语来表达这个观点。即:我们对传感器和测量方式的了解,对应于我们对所收集数据至少具有一些与其它类似情况中数据相同特征的充分信心。这种知识将未标记数据(传感器接收到的原始数据)转化为带有先验知识的数据:
2.6. 关于猫狗的先验知识将未标记数据转化为标记数据
假设我们想用卷积神经网络(CNN)来分类两类图像,分别是“猫”和“狗”。这些图像隐含了一个先验假设,即它们要么属于“猫”类,要么属于“狗”类。
从机器学习系统的角度来看,这个假设可以表述为:“在这个世界中,我拥有的传感器提供的数据属于两类中的一类。”因此,该系统拥有一个先验信念:对于任意一张图像,P(cat ∨ dog) = 1。
这并不是世界真实运作的方式,而是该系统所隐含的世界观。从某种意义上说,这也是本文提出的核心观点:所有数据本质上都是未标记的,只有我们为其附加的先验知识才使其成为标记数据。
3. 标记数据与未标记数据
我们已经从理论上解释了标记数据与未标记数据之间的区别,现在我们来看看这两类数据在技术上有哪些特征,以及分别适用于哪些机器学习任务。
3.1. 未标记数据
未标记数据是在没有先验知识的情况下收集的原始数据。例如,当你打开传感器或睁开眼睛,对环境一无所知时,你所收集的就是未标记数据。
例如:
- 数字
n = 5 - 向量
x = {2, 9, 3} - 矩阵
M = [[3, 1, 5], [4, 3, 2]]
这些都属于未标记数据。它们之所以“未标记”,是因为我们无法从中得知这些数据是由哪些传感器采集的,也无法得知采集时的环境状态。我们也不需要知道世界是如何运作的。
✅ 未标记数据几乎没有任何附加的先验知识。
3.2. 标记数据
标记数据是附加了先验知识的数据。一个人类或自动标注者必须使用他们的先验知识来为数据添加额外信息。这种信息不是直接从测量中获得的。
常见示例包括:
- 一张标注为“猫”或“狗”的图片
- 产品评论文本及其用户评分
- 房屋特征及其售价
在标注过程中使用的贝叶斯先验有时并不明显。例如,我们可能会问:一张猫的照片和“猫”这个词怎么会不相关?

这个问题在哲学上属于认识论范畴,不在本文讨论范围。简而言之,系统所拥有的知识并不必然是绝对或普遍的,而只是相对于该系统有意义的。人类标注者需要基于他们的先验知识为图像分配“猫”的标签,因为这个标签本身并不存在:

在这一语境下,标记数据是我们在原始数据基础上叠加了一个非测量结果的贝叶斯先验。这个先验来源于人类或机器学习系统的知识,它决定了数据“应该是什么”,无论它“是不是”或“是不是”。
✅ 所有基于该先验得出的结论的有效性,取决于该先验本身的正确性。
⚠️ 因此,准确标注是数据集准备过程中至关重要的一步。
4. 何时使用它们
标记数据与未标记数据之间的区别很重要,因为它们支持的机器学习任务不同。某些任务只能使用标记数据,另一些则只能使用未标记数据。
选择使用哪类数据通常基于以下标准:
- 任务类型
- 任务目标
- 数据可用性
- 标注所需知识的通用性或专业性
- 决策函数的复杂度
我们来详细看看这些标准。
4.1. 任务类型
✅ 标记数据支持回归和分类任务,属于监督学习(supervised learning)范畴。
典型回归任务包括:
- 使用多元回归预测未知值
- 找出两个变量之间的映射函数
- 实证检验科学假设
分类任务包括:
- 为观测值分配类别
- 常用于计算机视觉和语音识别系统中的实体识别
例如图像识别系统中,我们需要识别输入对应的标签:
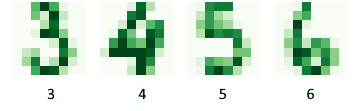
✅ 未标记数据支持聚类和降维任务,属于无监督学习(unsupervised learning)范畴。
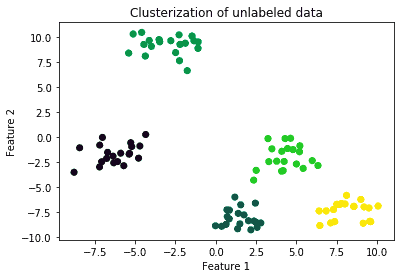
聚类任务包括:
- 识别共享共同特征的子集(如在向量空间中彼此靠近)
- 常见算法有 K-Means、KNN、DBSCAN:
降维任务包括:
- 减少数据集复杂度以节省计算资源
- 包括 PCA、Autoencoding、特征选择、t-SNE 等技术
另一个常见任务是特征缩放(Feature Scaling),用于标准化或归一化数据集,便于后续神经网络训练,通常在输入神经网络前进行,以帮助梯度下降(gradient descent)收敛。
4.2. 任务目标
另一个区分使用哪类数据的标准是任务的目标。
✅ 无监督学习基于数据的定量特征提取洞察,所需先验知识较少,目标通常不复杂。
例如:
- 降维(用于节省训练资源)
- 自编码器(autoencoder)构建抽象表示
✅ 监督学习目标更复杂,因为它基于对现象的深入理解。
可能包括:
- 图像中物体识别
- 股票价格预测
- 基于 X 光扫描的医学诊断
这些目标意味着数据集、模型与外部世界之间的关系,不仅仅是数学抽象,而是基于对世界某些特征影响另一些特征的稳定、可预测理解。
4.3. 数据可用性
最后一个关键标准是数据标签的可用性。
⚠️ 人工标注是非常昂贵的过程,往往超过机器学习系统开发的其他所有成本。
⚠️ 同时也非常耗时。即使是最高效的图像标注工具,也需要大量时间来构建足够大的标签数据集。
这意味着我们选择任务时,往往是基于已有数据,而非先选定任务再收集数据。
当然,也有例外,比如某些特定领域任务(如医学图像分析)会专门收集数据。
4.4. 通用知识 vs 专业知识
标签数据的可用性也取决于标签所包含的知识是通用还是专业。
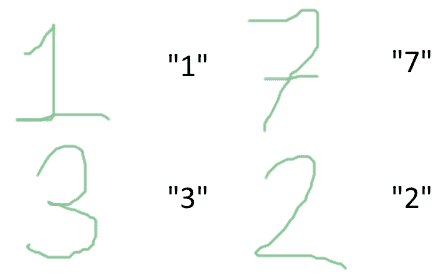
✅ 通用知识是指我们合理期望任何标注者都具备的知识。例如识别猫狗图片、将语音转为文本。
这类标注通常便宜,可以通过众包完成,例如手写数字识别:
❌ 专业知识是指只有经验丰富的专业人士才具备的知识。例如 X 光片中识别骨折或牙病。
这类任务必须由专业医生完成,标注成本高昂,因为他们的工资水平高。
4.5. 决策函数复杂度与标注数据量
随着问题复杂度增加,标注成本也会迅速上升。机器学习系统要学习的决策函数越复杂,就需要越多的标注数据。
✅ 决策函数越复杂,标注数据集必须越大,以便更好地采样决策空间:
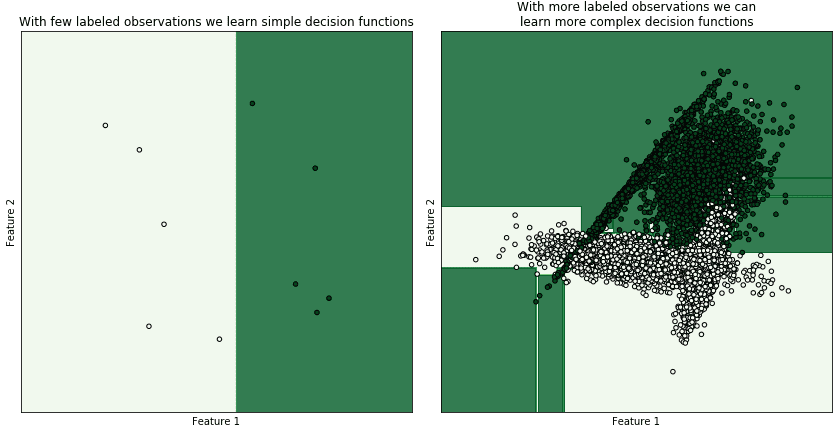
不过,如果数据集中的聚类非常清晰,可能只需少量标注样本即可完成分类任务,从而削弱这一限制。
5. 总结
在本文中,我们从贝叶斯理论和信息论的角度解释了标记数据与未标记数据之间的区别。
✅ 我们提出:所有来自传感器或测量的数据本质上都是未标记的。
✅ 只有我们为其附加了结构或功能的先验知识后,才成为标记数据。
我们还从机器学习系统架构的基本原理出发,解释了标记数据与未标记数据之间的区别。标记数据是受到世界运作方式假设所塑造的数据。
最后,我们总结了选择使用哪类数据的标准:任务类型、任务目标、数据可用性等。这些因素共同决定了我们在实际项目中如何做出选择。