1. 理解学习率
在进行机器学习任务时,神经网络中参数众多。其中一部分参数(如连接权重)是在训练过程中自动学习的,而另一部分(如学习率、权重衰减)则需要我们开发者手动设置。
这些需要手动设置的参数称为超参数(Hyperparameters),调整它们的过程称为调优(Fine-tuning)。尤其在面对大规模数据集时,学习率设置不当可能导致模型收敛缓慢、陷入局部最优甚至无法收敛。
本文将重点探讨学习率的作用及其常见设置方法。
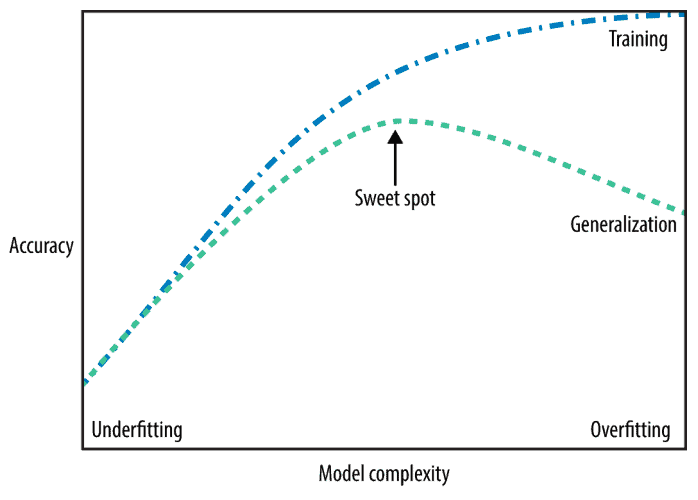
1.1. 泛化能力与过拟合/欠拟合
一个“好”的模型应该具备良好的泛化能力(Generalization),即在训练集和测试集上都能表现良好。
- 欠拟合(Underfitting):模型太简单,无法捕捉数据中的模式。
- 过拟合(Overfitting):模型太复杂,记住了训练数据中的噪声和细节,无法泛化。
我们追求的是“刚刚好”的状态:模型在训练集上表现良好,同时在新数据上也能保持稳定表现。
1.2. 梯度下降基础
大多数深度学习算法都涉及优化问题,目标是最小化损失函数 $ f(\textbf{x}) $。
梯度下降法通过计算损失函数的导数(或梯度),沿着负梯度方向更新参数:
$$ x' = x - \epsilon \triangledown_x f(x) $$
其中,$\epsilon$ 就是我们所说的学习率,它决定了每次参数更新的步长。
1.3. 多输入情况下的梯度
当输入变量不止一个时,我们需要计算偏导数并将其组合成一个梯度向量 $\triangledown_x f(x)$。
梯度方向告诉我们函数上升最快的方向,负梯度方向则是下降最快的方向。
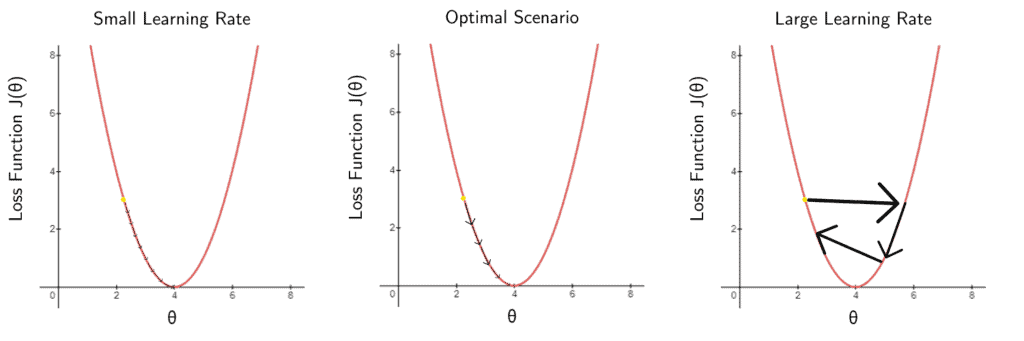
1.4. 学习率不当的影响
学习率设置不合理会导致两种极端情况:
- 学习率太小:收敛缓慢,训练时间长。
- 学习率太大:参数更新剧烈,模型在最小值附近震荡甚至发散。
下图展示了不同学习率对模型训练的影响:
2. 学习率设置方法
2.1. 学习率衰减(Learning Rate Annealing)
这是一种简单但有效的策略:随着训练轮数(epoch)的增加,逐步降低学习率。
例如:
- 前400个epoch使用0.1
- 第400~700个epoch使用0.01
- 最后300个epoch使用0.001
这种策略有助于在训练初期快速探索参数空间,后期精细化调整。
2.2. RMSProp
RMSProp是一种自适应学习率优化器,通过维护梯度平方的移动平均来动态调整学习率:
$$ m_t = \beta m_{t-1} + (1 - \beta) g_t^2 $$ $$ w_t = w_{t-1} - \frac{\alpha}{\sqrt{m_t + \epsilon}} g_t $$
其中:
- $ m_t $:梯度平方的指数加权平均
- $ \beta $:衰减系数,默认为0.9
- $ \epsilon $:防止除以零的小常数
2.3. Adam(自适应矩估计)
Adam结合了RMSProp和动量法(Momentum),维护梯度的一阶矩(均值)和二阶矩(方差):
$$ m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t $$ $$ v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 $$
为避免初始化偏差,Adam还做了偏差校正:
$$ \hat{m}_t = \frac{m_t}{1 - \beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1 - \beta_2^t} $$
最终更新公式为:
$$ w_{t+1} = w_t - \frac{\alpha}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t $$
默认参数:$\beta_1=0.9, \beta_2=0.999$
2.4. Adagrad
Adagrad为每个参数使用不同的学习率,适用于稀疏数据:
$$ w_{t+1,i} = w_{t,i} - \frac{\alpha}{\sqrt{G_{t,ii} + \epsilon}} g_{t,i} $$
其中 $ G_t $ 是历史梯度平方的累加矩阵。
2.5. Adadelta
Adadelta是对Adagrad的改进,不再累加所有历史梯度,而是使用滑动窗口:
$$ E[g^2]t = \gamma E[g^2]{t-1} + (1 - \gamma) g_t^2 $$ $$ w_{t+1} = w_t - \frac{\alpha}{\sqrt{E[g^2]_t + \epsilon}} g_t $$
Adadelta的一个优点是不需要手动设置初始学习率。
2.6. 基于种群的训练(PBT)
PBT是DeepMind提出的一种超参数自动调优方法,结合了随机搜索和早停机制:
- 多个模型并行训练,各自使用不同的超参数
- 定期评估模型表现
- 表现差的模型会被表现好的模型“取代”并继续训练
这种策略可以动态优化学习率等超参数,适合大规模训练任务。
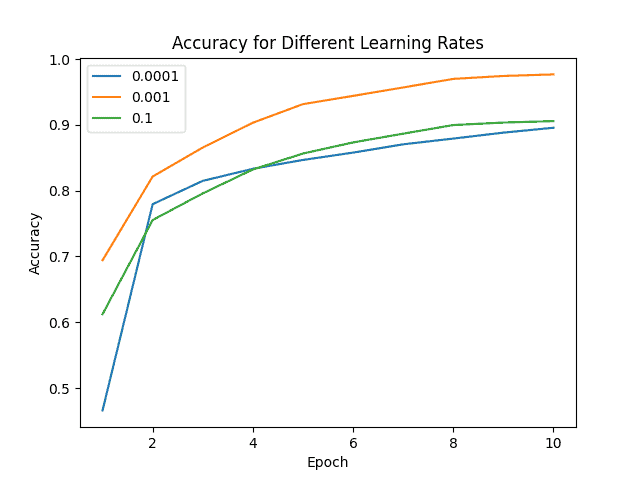
3. 实验对比
我们使用Adam优化器训练一个识别120种犬种的神经网络,比较不同学习率(0.0001、0.001、0.01)的效果:
准确率对比
损失对比
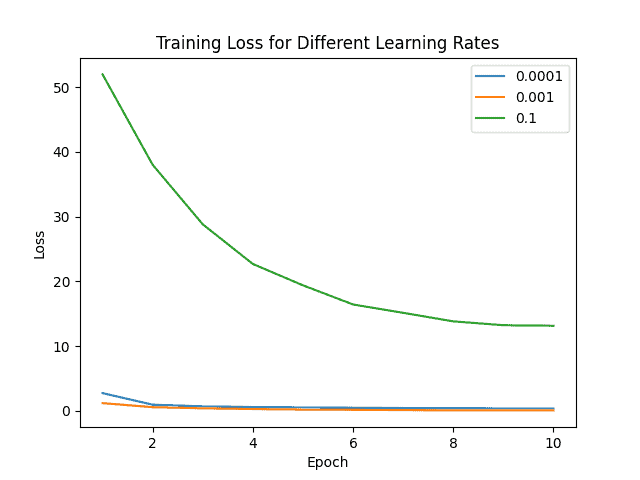
结果表明,学习率为0.001时模型表现最佳。
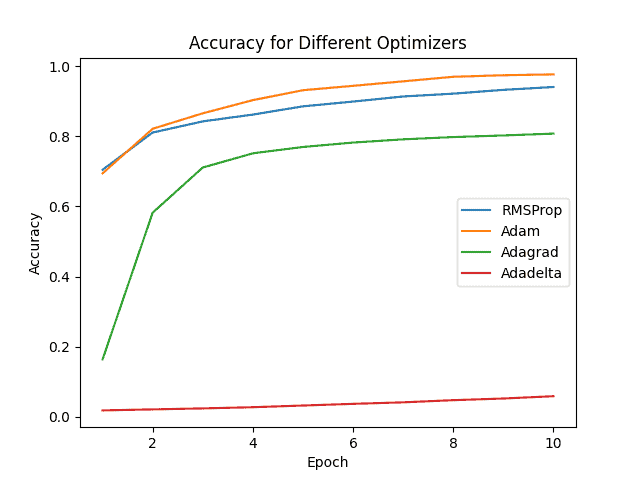
我们还比较了不同优化器在相同学习率下的表现:
多优化器准确率对比
多优化器损失对比
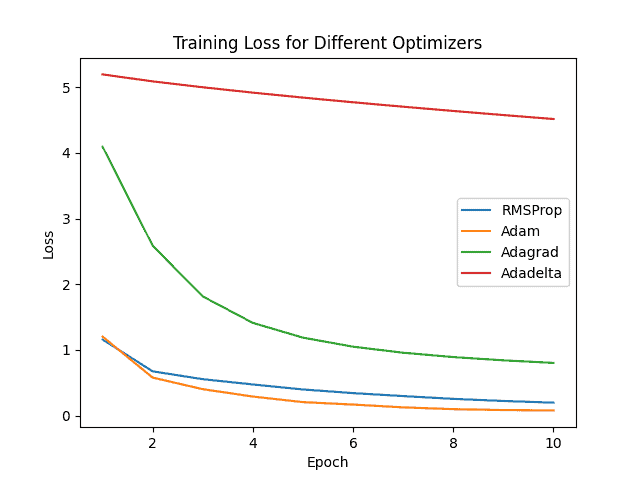
Adam在准确率和损失上均优于其他优化器,是首选的优化策略。
4. 总结
学习率是影响模型训练效果的关键超参数之一。设置不当可能导致模型收敛缓慢、无法收敛或过拟合。
我们介绍了以下几种常用的学习率设置方法:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 学习率衰减 | 实现简单,适合大多数场景 | 需要手动设置衰减策略 |
| RMSProp | 自适应学习率,适合非平稳目标 | 对初始学习率敏感 |
| Adam | 综合性能最佳,适合大多数任务 | 可能收敛到次优解 |
| Adagrad | 适合稀疏数据 | 学习率单调下降,后期更新过慢 |
| Adadelta | 无需手动设置学习率 | 理解和调参较复杂 |
| PBT | 自动调参,适合大规模任务 | 计算资源消耗大 |
✅ 建议:
- 一般建议优先使用Adam优化器
- 学习率建议从0.001开始尝试
- 若训练数据稀疏,可考虑Adagrad或Adadelta
- 对于大规模任务,可尝试PBT自动调参
⚠️ 注意:
- 不要盲目使用过大学习率,容易导致模型不收敛
- 不要忽略学习率衰减策略,尤其是在训练后期
- 对比不同优化器时,保持其他参数一致,便于公平比较
选择合适的学习率和优化策略,是提升模型性能的重要一环。希望本文能为你提供实用的参考。