1. 引言
在机器学习中,检测和处理数据集中的异常值(Outlier)是一项关键任务。监督学习算法通过学习数据集中的模式进行预测,而如果数据集中存在噪声,训练出的模型预测能力会大打折扣。
某些算法(如 kNN)对异常值非常敏感。而基于树的方法(如随机森林)则对异常值具有更强的鲁棒性。
在本文中,我们将了解什么是异常值,讨论常见的异常值检测方法,并探讨如何处理这些异常值。
2. 什么是异常值
在统计学中,异常值是指显著偏离数据集整体分布的观测点。换句话说,这些数据点的值与数据集整体行为不一致。
导致异常值出现的原因有很多。例如,可能是测量错误或输入错误。比如我们期望“年龄”字段为正整数,若某条记录的年龄为“-1”或“abc”,这显然是错误的。
但有时异常值也可能是合法的。例如某人的年龄为112岁,虽然非常罕见,但并非不可能。此时删除该值会导致信息丢失。
在分类任务中,尤其是在数据不平衡的场景下,异常值可能包含关键信息。例如在欺诈检测中,异常交易往往才是关注的重点。此时去除异常值可能会丢失有价值的信号。
但另一方面,异常值也可能引入噪声,影响模型训练效果。特别是在数据量较大的情况下,去除不符合数据整体特征的观测点有助于提升模型性能。
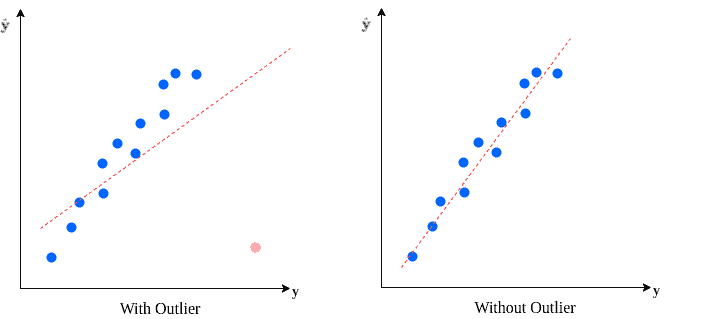
如下图所示,如果我们在一个线性回归模型中包含异常值,最终拟合结果会受到明显影响:
3. 异常值检测方法
检测异常值并不是一件简单的事情。我们需要识别那些不符合数据集整体特征的观测点。
根据数据集的不同,可以选择不同的方法。下面介绍几种常用的异常值检测方法。
3.1. 数据可视化
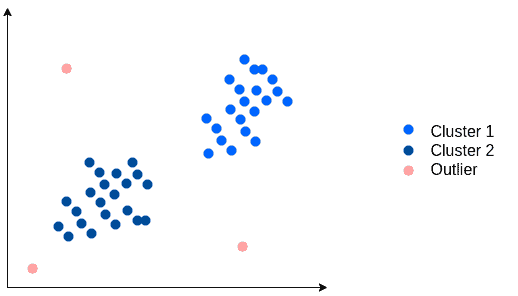
数据可视化是一种简单且有效的异常值检测方法。尤其在低维数据集中,我们可以通过散点图直观地识别出异常值:
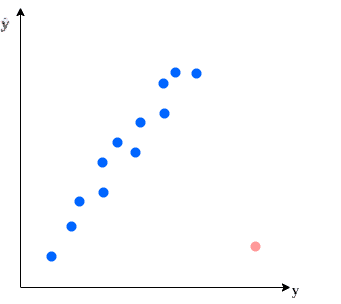
但随着维度的增加,可视化变得困难,尤其在高维空间中,难以通过图形识别异常值。因此,我们需要借助其他数学方法。
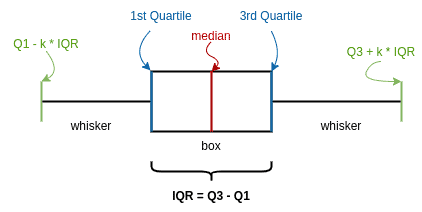
3.2. 四分位分析(Quartile Analysis)
我们可以通过统计方法定义异常值候选。首先介绍几个关键概念:
- Q₁(第一四分位数):代表数据的25%分位数
- Q₃(第三四分位数):代表数据的75%分位数
定义 IQR(Interquartile Range,四分位距) 为:
$$ IQR = Q_3 - Q_1 $$
在四分位分析中,我们通常将超出 $ k \times IQR $ 范围的值定义为异常值。常用的 k 值为1.5:
$$ \text{正常范围:} \quad Q_1 - 1.5 \times IQR < x < Q_3 + 1.5 \times IQR $$
我们可以通过箱线图(Boxplot)来可视化这一过程:
3.3. Z-Score
Z-Score 用于衡量某个观测值偏离均值的标准差数,适用于数据呈正态分布的情况。
计算公式如下:
$$ z = \frac{x - \mu}{\sigma} $$
其中:
- $ x $:观测值
- $ \mu $:均值
- $ \sigma $:标准差
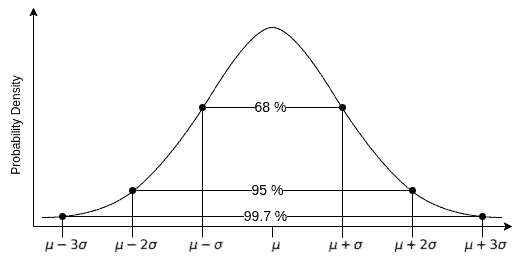
根据经验法则:
- $ \mu \pm \sigma $ 覆盖约68.27%
- $ \mu \pm 2\sigma $ 覆盖约95.45%
- $ \mu \pm 3\sigma $ 覆盖约99.73%
因此,我们通常设定一个阈值(如2.5、3.0等),将绝对值超过该阈值的点视为异常值:
$$ |z| > \text{Threshold} $$
3.4. DBSCAN 聚类
DBSCAN 是一种基于密度的聚类算法,常用于异常值检测。它将数据点分为三类:核心点、边界点和噪声点。
其中,噪声点即为异常值。使用 DBSCAN 的优势在于无需预先指定聚类数量。
使用前建议先对数据进行标准化处理,尤其在使用欧几里得距离等度量方式时。
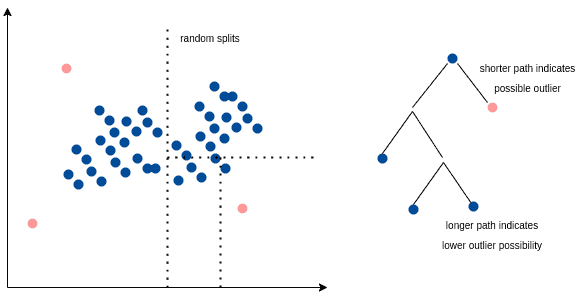
3.5. Isolation Forest(孤立森林)
Isolation Forest 是一种专门用于异常检测的算法。其核心思想是:异常值更容易被孤立。
算法通过随机选择特征和分割点,构建多个孤立树(Isolation Trees)。每棵树记录将某个样本孤立所需的路径长度。平均路径越短的样本越可能是异常值。
✅ 优点:无需假设数据分布
✅ 适用性广:适合高维数据
❌ 缺点:对参数敏感,需调参
4. 异常值处理方法
检测到异常值后,下一步是决定如何处理它们。这并不是一个标准化流程,需要根据具体场景灵活应对。
4.1. 删除异常值
- ✅ 适用场景:明确知道是录入错误或测量错误(如年龄为“abc”)
- ❌ 注意:不要盲目删除,尤其在小数据集中,可能造成信息丢失
4.2. 替换异常值(Imputation)
- 可以用均值、中位数、众数等替换
- 或使用模型预测合理的值(如回归、KNN)
4.3. 截断(Winsorizing)
- 适用于数据量大、极端值可能是合法值的场景
- 例如将“年龄”大于80的值统一替换为80
4.4. 分箱(Binning)
- 将连续值离散化为区间
- 例如将年龄分为 [0-20], [21-40], [41-60], [61-120]
4.5. 咨询领域专家
- 有时异常值背后隐藏着重要的业务逻辑或特殊场景
- 与业务方或领域专家沟通,有助于判断异常值是否应该保留
5. 小结
在本文中,我们学习了异常值的基本概念及其在机器学习中的重要性。我们讨论了几种常见的异常值检测方法,包括:
| 方法 | 适用场景 | 是否适合高维 |
|---|---|---|
| 数据可视化 | 低维数据 | ❌ |
| 四分位分析 | 单变量检测 | ❌ |
| Z-Score | 正态分布数据 | ❌ |
| DBSCAN | 无监督聚类 | ✅ |
| Isolation Forest | 高维数据 | ✅ |
最后,我们也讨论了几种处理异常值的策略,包括删除、替换、截断、分箱以及结合业务逻辑判断。
💡 建议:
- 异常值处理前先理解其来源
- 不要盲目删除或替换
- 结合数据分布、算法特性、业务背景综合决策
📌 结语:异常值不是敌人,也不是朋友。它们是数据的一部分,理解它们、处理它们,是构建高质量模型的关键一步。