1. 概述
本文我们将深入探讨卷积神经网络(CNN)中的两个核心组件:ReLU(线性整流函数) 和 Dropout 层,并通过一个示例网络结构来理解它们的作用。
学完本文后,你将明白为什么要在 CNN 中引入这两个组件,以及在实际项目中如何正确实现它们。
2. CNN 中的维度灾难问题
构建任何神经网络时,我们通常需要满足两个前提假设:
- 输入特征之间是线性独立的
- 输入空间的维度较低
但我们在 CNN 中处理的数据(如图像、音频、文本、视频)通常都不满足这两个条件。这也是我们选择 CNN 而非其他神经网络架构的原因之一。
在 CNN 中,通过训练过程中的卷积(convolution)和池化(pooling)操作,隐藏层的神经元会学习输入数据的抽象表示,并通常会降低其维度。
此时,网络假设这些抽象表示之间是相互独立的,而非原始输入特征。这些抽象表示通常存在于 CNN 的隐藏层中,其维度通常远低于输入维度:

因此,CNN 能够有效缓解“维度灾难”问题,即随着输入维度的线性增长,完成机器学习任务所需的计算量呈指数级增长的现象。
3. ReLU 的作用与优势
3.1. 为什么 CNN 不使用 Sigmoid 函数?
在训练后的 CNN 中,隐藏层的神经元代表了对输入数据的抽象表示。面对新的输入数据,CNN 并不确定哪些抽象表示是相关的。
对于隐藏层中的某个神经元来说,它可能属于两种情况之一:相关或不相关。
如果该神经元不相关,这并不意味着其他抽象表示也会不相关。如果使用输出范围包含负数的激活函数(如 Sigmoid 或 Tanh),那么在某些输入下,该神经元的输出会对整个网络的输出产生负面影响。
这通常是不希望出现的情况。因为我们假设所有学到的抽象表示是相互独立的。因此,在 CNN 中,更倾向于使用非负的激活函数。
最常用的非负激活函数是 ReLU(Rectified Linear Unit),其定义为:
$$ f(x) = \max(0, x) $$
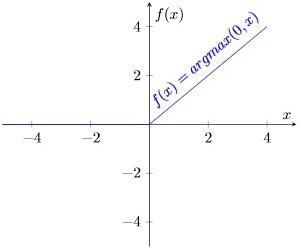
3.2. ReLU 的计算与优势
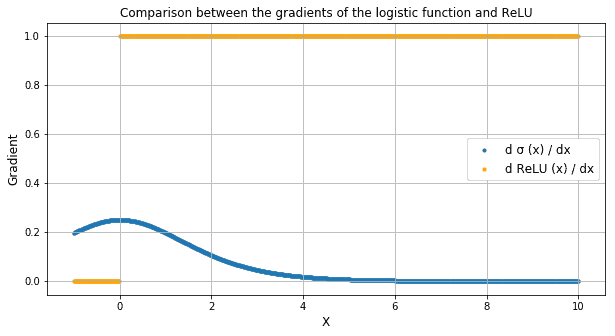
相比 Sigmoid 函数 $\sigma(x)$ 或 Tanh 函数 $\tanh(x)$,ReLU 有以下两个显著优势:
✅ 计算简单:只需判断输入是否大于 0
✅ 导数恒定:输入小于 0 时导数为 0,大于等于 0 时导数为 1
这在训练过程中对反向传播有重要意义:
$$ \text{ReLU}'(x) = \begin{cases} 0, & x < 0 \ 1, & x \geq 0 \end{cases} $$
非线性激活函数如 Sigmoid,其导数会在输入较大时趋于 0,从而导致“梯度消失”问题。而 ReLU 的导数始终保持为 1(当输入大于等于 0 时),使得误差能够持续传播,学习过程不会中断:
4. Dropout 层的作用与实现
另一个 CNN 中常见的设计是 Dropout 层。
✅ Dropout 层的作用是随机“关闭”一部分神经元,使其对下一层的输出没有贡献。它可以作用于输入层(关闭部分输入特征),也可以作用于隐藏层(关闭部分神经元)。
Dropout 层在训练 CNN 时非常重要,因为它可以防止模型在训练数据上过拟合。如果缺少 Dropout 层,模型可能会过度依赖前几个训练样本中出现的特征,从而影响对后续样本中新特征的学习能力:
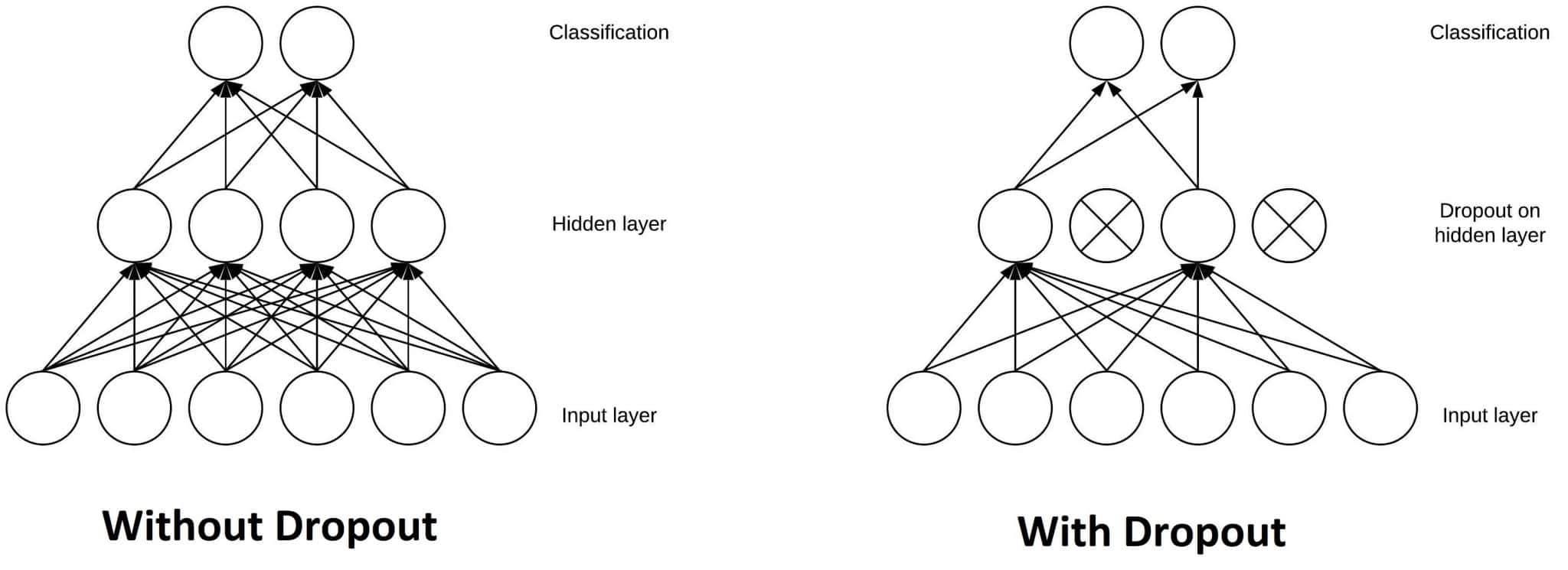
举个例子:如果你连续给 CNN 看十张圆形图片,它可能就不会学习“直线”特征。之后你再给它看正方形图片时,它就会“懵圈”。而加入 Dropout 层可以有效避免这种过拟合现象。
5. 包含 ReLU 与 Dropout 的 CNN 结构示例
下面是一个典型的包含 ReLU 和 Dropout 层的 CNN 架构流程图。这种结构在图像分类任务中非常常见:

6. 总结
本文我们讨论了为什么在输入特征不独立时更倾向于使用 CNN,以及为何选择 ReLU 作为激活函数。
✅ ReLU 计算简单,导数固定,反向传播效率高
✅ Dropout 层通过随机关闭部分神经元防止过拟合
这两个组件在现代 CNN 架构中几乎不可或缺,是构建高性能模型的关键组成部分。在实际项目中合理使用它们,可以显著提升模型的泛化能力和训练效率。