1. 引言
在自然语言处理(NLP)中,计算两个文本文档之间的相似度是一项常见任务,具有多种实际应用。例如,搜索引擎结果的排序、推荐系统中内容的匹配等,都依赖于这种能力。
由于“文本相似度”本身是一个模糊的概念,我们首先需要为本文定义一个适用范围。随后,我们将探讨两种主流的相似度计算方法,并分析它们的优缺点。
2. 什么是文本相似度?
要定义文本相似度,我们可以从两个例子入手。
考虑以下两个句子:
- The teacher gave his speech to an empty room
- There was almost nobody when the professor was talking
虽然它们的表达方式完全不同,但含义非常相近,仅共享一个词 "the"。理想情况下,我们希望相似度算法对这对句子返回一个较高的得分。
再看一个略微改动的版本:
- The teacher gave his speech to an empty a full room
- There was almost nobody when the professor was talking
仅改动了两个词,但语义变成了相反。这种基于语义的相似度称为 语义相似度(Semantic Similarity),是当前NLP研究的热点之一。
而传统的文本相似度方法仅基于词法层面(lexical level),即只考虑词的出现频率,不考虑语义。这些方法在深度学习兴起前发展成熟,至今仍广泛使用,尤其适合对性能要求较高的场景。
3. 文档向量(Document Vectors)
传统方法计算文档相似度的核心是将文档转化为实数向量,从而可以使用线性代数中的相似度计算方法。这种方法称为 向量空间模型(Vector Space Model)。
实现该模型需要两个关键步骤:
- 将文本转化为向量
- 选择合适的向量相似度计算方式
3.1 文档向量示例
最简单的文本向量化方法是使用词频(word counts)。
我们以三个句子为例:
- We went to the pizza place and you ate no pizza at all
- I ate pizza with you yesterday at home
- There’s no place like home
对每个句子统计词频,得到如下结果:
| Document 1 | Document 2 | Document 3 |
|---|---|---|
| we: 1 | I: 1 | there’s: 1 |
| went: 1 | ate: 1 | no: 1 |
| to: 1 | pizza: 1 | place: 1 |
| the: 1 | with: 1 | like: 1 |
| pizza: 2 | you: 1 | home: 1 |
| place: 1 | yesterday:1 | |
| and: 1 | at: 1 | |
| you: 1 | home: 1 | |
| ate: 1 | ||
| no: 1 | ||
| at: 1 | ||
| all: 1 |
✅ 通常还会对词进行词干提取(stemming)或词形还原(lemmatization),以减少稀疏性。
得到词频向量后,我们可以使用 余弦相似度(Cosine Similarity) 来计算文档之间的相似度。公式如下:
$$ \cos(a, b) = \frac{\sum_{i=1}^{n} a_i b_i}{\sqrt{\sum_{i=1}^{n}a_i^2}\sqrt{\sum_{i=1}^{n}b_i^2}} $$
将上述三个文档两两比较,得到的余弦相似度为:
- cos(doc1, doc2) = 0.45
- cos(doc1, doc3) = 0.23
- cos(doc2, doc3) = 0.15
可以看出,前两个文档相似度最高,因为它们共享了“pizza”、“ate”、“you”、“at”等词,而“pizza”出现了两次,因此对相似度贡献更大。
4. TF-IDF 向量
上述示例使用的是简单的词频统计,但在实际应用中,这种方法存在明显缺陷。
最明显的问题是:常见词(如“the”、“is”)往往并不重要,但却会显著影响相似度结果。这类词通常被称为“停用词(stopwords)”,可以在预处理阶段过滤掉。
更高级的做法是使用 TF-IDF(Term Frequency - Inverse Document Frequency) 方法,它会自动降低高频词的权重,从而提升稀有词的影响力。
TF-IDF 的公式如下:
$$ \text{TF-IDF}(word) = \text{frequency}(word) \cdot \log\left(\frac{N}{|{d \in C : word \in d}|}\right) $$
其中:
- $ N $:语料库中文档总数
- $ |{d \in C : word \in d}| $:包含该词的文档数量
举个例子,假设我们以上面三个句子作为语料库:
“pizza” 出现在两个文档中,IDF 为:
$$ \log\left(\frac{3}{2}\right) \approx 0.40 $$“yesterday” 只出现在一个文档中,IDF 为: $$ \log\left(\frac{3}{1}\right) \approx 1.10 $$
可以看出,稀有词的权重更高,这正是我们想要的效果。
4.1 TF-IDF 的优缺点
✅ 优点:
- 权重机制更合理,避免高频词主导结果
- 不仅适用于停用词处理,也适用于主题相关词的权重调整
- 在搜索引擎、推荐系统等场景中表现良好
❌ 缺点:
- 无法捕捉语义信息,如“teacher”和“professor”会被视为完全不同的词
- 对长文档效果有限,容易忽略词序和上下文关系
尽管如此,TF-IDF 仍是目前最常用、最高效的文本表示方法之一,尤其适合对性能要求高、语义要求不高的场景。
5. 词嵌入(Word Embeddings)
词嵌入是一种将词语映射到高维向量空间的技术,通常通过无监督学习从大量文本中训练得到。这些向量能够捕捉词语之间的语义关系,例如:
- “teacher” 和 “professor” 的向量距离较近
- “king” - “man” + “woman” ≈ “queen”
这种语义上的相似性使词嵌入在计算文本相似度时具有明显优势。
5.1 文档中心向量(Document Centroid Vector)
最简单的词嵌入应用方法是计算文档中所有词向量的平均值,称为 文档中心向量(Document Centroid Vector)。
由于每个词嵌入是固定维度,因此每个文档最终也会得到一个固定维度的向量,可以用于余弦相似度计算。
例如:
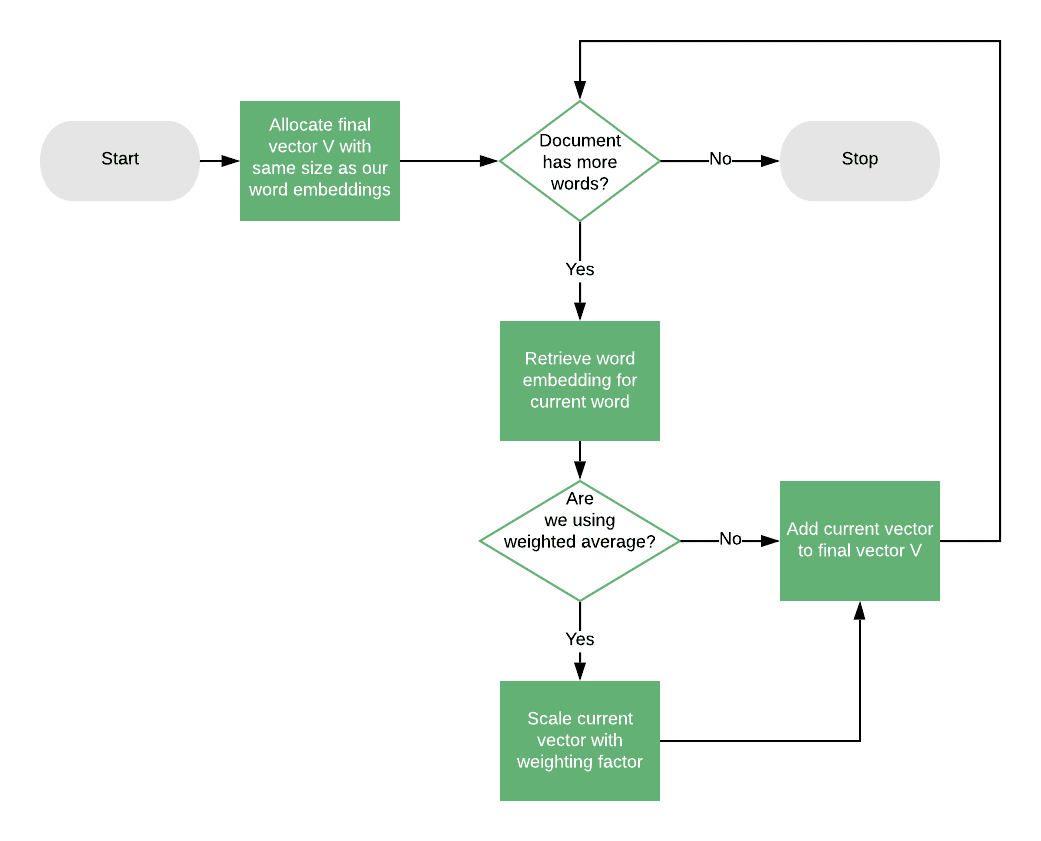
该方法适用于短文档,但对长文档来说,平均操作会丢失很多信息。为提升效果,可以结合 TF-IDF 加权平均词向量:
$$ \text{Centroid} = \frac{\sum_{w \in d} \text{TF-IDF}(w) \cdot \text{Embedding}(w)}{\sum_{w \in d} \text{TF-IDF}(w)} $$
5.2 词嵌入的优缺点
✅ 优点:
- 捕捉语义信息,处理同义词、近义词更有效
- 可结合 TF-IDF 提升效果
❌ 缺点:
- 需要额外训练或加载预训练模型
- 对长文档效果有限
- 增加计算成本,可能不适合实时场景
6. 总结
文本相似度是一个活跃的研究领域,技术不断演进。本文介绍了两种主流方法:
- TF-IDF:适用于快速实现、性能敏感的场景,但无法捕捉语义信息
- 词嵌入:引入语义信息,但增加复杂度和计算开销
选择方法时,应根据实际需求权衡:
- 是否需要语义理解?
- 是否对性能敏感?
- 是否有资源训练或加载词嵌入?
在大多数工程实践中,TF-IDF 仍然是首选方法,除非明确需要语义层面的相似度判断。词嵌入更适合于内容理解、推荐系统等需要语义建模的场景。