1. 简介
在机器学习中,我们的目标是构建能够对给定输入数据进行预测的模型。为了实现这一目标,我们通常会对训练好的模型进行调优,并通过评估多个候选模型的性能来选择表现最佳的模型。
然而,选择“最佳模型”并不是一件简单的事情。仅仅选择准确率最高的模型,并不能保证它在未来的预测中不会出错。因此,我们通常会使用 训练集/测试集划分 和 交叉验证 的方式来评估模型在未知数据上的表现。
在本篇文章中,我们将聚焦机器学习中两个关键问题:过拟合(Overfitting) 和 欠拟合(Underfitting)。这两个术语描述了模型在学习输入与输出之间关系时可能出现的两种极端情况,它们都可能导致模型性能不佳。
2. 什么是欠拟合和过拟合
✅ 过拟合(Overfitting)
当一个模型在训练数据上表现得过于“敏感”时,就发生了过拟合。也就是说,它把训练数据中的噪声和细节都“记住”了,导致它在新数据上的泛化能力差。
- 表现:在训练集上表现很好(高准确率),但在验证集或测试集上表现差。
- 原因:模型太复杂,以至于学习了训练数据中的噪音和细节。
- 后果:泛化能力差,预测不可靠。
✅ 欠拟合(Underfitting)
当模型无法从训练数据中学习到足够的信息时,就发生了欠拟合。它既不能很好地拟合训练数据,也不能很好地预测新数据。
- 表现:在训练集和验证集上都表现差。
- 原因:模型太简单,无法捕捉数据中的潜在模式。
- 后果:预测能力差,模型不具备实用价值。
✅ 总结一句话:
我们希望模型既不过于复杂(避免过拟合),也不能过于简单(避免欠拟合),要在两者之间找到一个平衡点。
📈 示例图解
假设我们有一个数据集分布在 S 形曲线上,比如对数曲线:
- 如果我们用一个高阶多项式去完美拟合所有训练点(零误差),这个模型会非常复杂,甚至把噪声也当成了模式。
- 如果我们用一条直线去拟合,误差会很大,模型太简单,无法捕捉曲线的形状。
如下图所示:
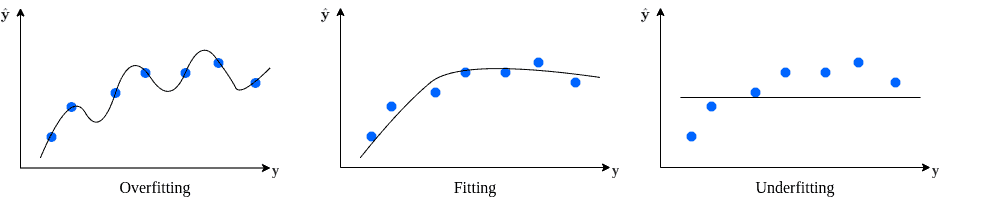
这就引出了一个核心概念:偏差-方差权衡(Bias-Variance Tradeoff)。我们希望找到一个既不过拟合也不欠拟合的模型。
3. 如何检测欠拟合和过拟合?
检测这两种问题的核心在于观察模型在训练集和验证集上的表现。
✅ 观察指标:损失值(Loss)和准确率(Accuracy)
我们通常会绘制训练损失和验证损失的曲线来判断模型是否出现过拟合或欠拟合:
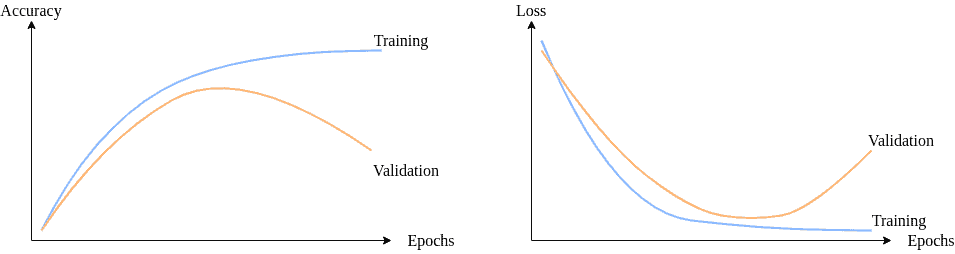
✅ 3.1 检测过拟合
过拟合的一个典型特征是:
- 训练损失持续下降
- 验证损失在某个点后开始上升
这说明模型在训练集上表现越来越好,但对新数据的适应能力却在下降。
如下图所示:
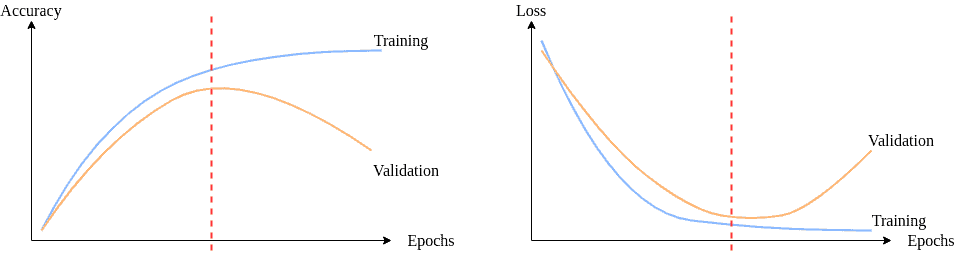
此时应考虑停止训练,或者采取措施降低模型复杂度。
✅ 3.2 检测欠拟合
欠拟合更容易检测:
- 训练损失和验证损失都较高
- 即使不划分验证集,模型在训练集上表现也很差
这说明模型没有学到足够的模式,属于高偏差(High Bias)状态。
如下图所示:
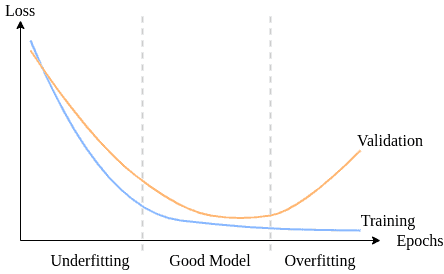
4. 如何解决欠拟合和过拟合?
✅ 4.1 解决过拟合
| 方法 | 描述 |
|---|---|
| 减少模型复杂度 | 减少神经网络的层数或节点数、使用更简单的模型(如从深度树换到浅层树) |
| 特征选择 | 减少输入特征数量,保留最相关的特征 |
| 正则化(Regularization) | 添加 L1/L2 正则项、Dropout(神经网络中) |
| 早停(Early Stopping) | 在验证集表现开始下降时停止训练 |
| 增加训练数据 | 更多数据有助于模型更好地泛化 |
✅ 4.2 解决欠拟合
| 方法 | 描述 |
|---|---|
| 增加模型复杂度 | 增加神经网络层数或节点数、使用更复杂的模型 |
| 数据增强 | 对现有数据进行变换(如旋转、缩放)生成更多样本 |
| 增加训练轮数(Epochs) | 让模型更充分地学习数据 |
| 增加特征维度 | 添加特征组合、多项式特征等 |
| 减少正则化强度 | 如果模型太简单,可以降低正则化参数 |
| 更换模型 | 比如更换 SVM 的核函数以提升模型表达能力 |
5. 总结对比表
| 特征 | 过拟合 | 欠拟合 |
|---|---|---|
| 模型复杂度 | 太高 | 太低 |
| 训练集表现 | 好 | 差 |
| 验证集表现 | 差 | 差 |
| 解决方向 | 降低复杂度 | 提升复杂度 |
| 特征处理 | 减少特征 | 增加特征 |
| 正则化 | 加强 | 减弱 |
| 训练次数 | 减少 | 增加 |
| 数据量 | 增加 | 增加(但效果有限) |
6. 结语
在本文中,我们详细讨论了机器学习中常见的两个问题:过拟合与欠拟合。
- 我们解释了它们的定义和表现形式;
- 分析了如何通过损失和准确率曲线来识别它们;
- 探讨了应对这两种问题的常见策略;
- 最后通过对比表进行了总结。
在实际建模过程中,识别并解决过拟合和欠拟合问题 是提升模型性能的关键环节。掌握这些方法,有助于你构建出既不过拟合也不欠拟合的高质量模型。