1. 简介
本文将介绍主题建模的基本概念和常见技术,接着概述词嵌入(Word Embedding)和 Word2Vec 算法,最后重点讲解如何基于 Word2Vec 实现主题建模。
2. 主题建模简介
主题建模是一种无监督机器学习技术,用于扫描一组文档,从中提取并聚类相关的词汇和短语。 这些聚类称为“主题”(Topic),每个聚类代表数据集中潜在的一个主题。主题建模是自然语言处理(NLP)中的一个重要问题。
一个常见的例子是自动为客服工单打标签,根据工单内容将它们分配给对应的处理团队。
常见主题建模方法
潜在语义分析(Latent Semantic Analysis, LSA)
- 假设在相同上下文中出现的词是相似的
- 使用 TF-IDF 分数来计算词语频率
潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)
- 假设文档由多个主题构成,每个主题由一组相似词语组成
- 使用狄利克雷分布来建模文档与主题、主题与词语之间的关系
⚠️ 主题建模是无监督任务。如果数据集有标签,就变成了主题分类问题,属于监督学习。
目前最流行的主题建模库是 Gensim,它支持 LDA、LSA 和 Word2Vec 等多种模型。
3. Word2Vec 简介
在介绍 Word2Vec 之前,先了解什么是词嵌入(Word Embedding)。
3.1. 词嵌入
词嵌入是用向量表示词汇的技术。 每个词被映射为一个向量,长度通常等于文档中唯一词汇的数量。这些向量可以用于检测词义、语义相似性、语法相似性或词语之间的关系。
词语之间的相似性通过向量之间的夹角(余弦相似度)来衡量。
词嵌入分为两种:
- 基于频率的嵌入
- 使用统计方法构建词向量,如词频统计、TF-IDF 等
- 基于预测的嵌入
- 使用神经网络学习词向量,Word2Vec 就属于这一类
3.2. Word2Vec
Word2Vec 是 2013 年 Google 提出的一种基于神经网络的词向量学习方法,是目前最流行的预测型词嵌入之一。它本质上是一个两层神经网络,用于从文本语料中学习词向量。
Word2Vec 的核心思想是:上下文相似的词,其向量也应相近。 例如,“man”和“woman”在语义上是相对的,而 Word2Vec 可以通过训练学习到这种关系。
例如,在维基百科语料上训练 Word2Vec 后,它可以学到“man”对应“king”,当输入“woman”时输出“queen”。这种现象被称为“king - man + woman”问题。
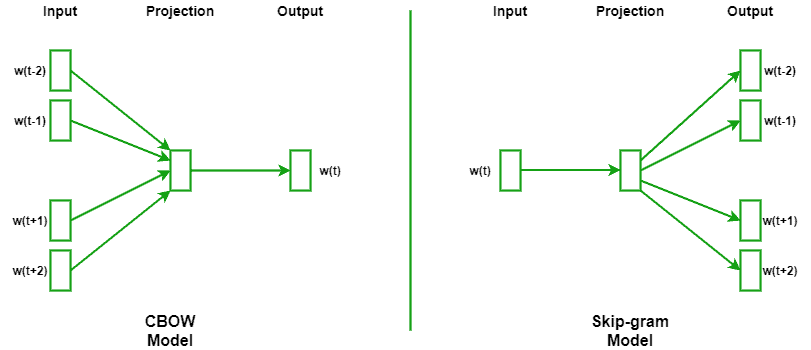
Word2Vec 的两种模型结构
CBOW(Continuous Bag of Words)
- 通过上下文预测当前词
- 更适合大规模数据集,训练速度较快
Skip-gram
- 通过当前词预测上下文
- 更适合小规模数据集,对低频词效果更好
下图展示了 CBOW 和 Skip-gram 的网络结构对比:
4. 使用 Word2Vec 进行主题建模
虽然 Word2Vec 在语义表示方面表现出色,但它本身并不是为“主题建模”设计的。它主要关注词语之间的局部上下文关系,而不是文档层面的主题结构。
Word2Vec 用于主题建模的挑战
- 所有词权重相同:Word2Vec 无法区分哪些词对主题更重要
- 多义词问题:同一词在不同语境下可能代表不同含义,但其向量是固定的
- OOV(Out-of-Vocabulary)问题:无法处理训练时未见过的新词
解决方案:将 Word2Vec 向量用于聚类
一个简单思路是:将 Word2Vec 学到的词向量作为输入,输入到聚类算法中,从而得到主题。但这种方法效果有限,不如 LDA 精准。
4.1. LDA2Vec:结合 LDA 与 Word2Vec
LDA2Vec 是 2016 年由 Chris Moody 提出的一种结合 LDA 和 Word2Vec 的混合模型,用于改进主题建模效果。
LDA 的局限性
- LDA 基于词袋模型(Bag of Words),忽略词语之间的语义关系
- 所有文档向量长度相同,限制了表达能力
LDA2Vec 的优势
- 使用 Word2Vec 学习词向量和文档向量
- 使用修改版 Skip-gram 模型:用“词 + 文档”共同预测上下文
- 生成稀疏文档权重向量(类似 LDA),同时保留词向量的语义信息
✅ 优点总结:
- 结合了 LDA 的主题结构和 Word2Vec 的语义表达
- 支持文档级和词级建模
- 更适合长文本和复杂语义结构
LDA2Vec 的实现资源
5. 总结
本文介绍了主题建模的基本概念和常见方法(LSA、LDA),然后讲解了词嵌入和 Word2Vec 的原理,最后介绍了如何将 Word2Vec 与 LDA 结合,通过 LDA2Vec 实现更高质量的主题建模。
✅ 如果你希望从大量文本中自动提取主题,LDA2Vec 是一个值得尝试的进阶方案,尤其适合语义结构复杂、文档较长的场景。