1. Introduction
In this tutorial, we’ll study text-to-video generation using a special class of generative models called video diffusers.
With the recent advances in computing, storage, and technical knowledge, we’re witnessing a surge of artificial intelligence generative models across multi-modalities (text, image, video, audio). A video diffuser is a generative diffusion model that can help us create a video using images and text prompts. It works in two passes, wherein the first pass systematically adds noise to the input image. Then, in the second step, it learns the reverse denoising process to generate a new image.
We’ll look at the ModelScope text-to-video diffuser from the Alibaba group hosted on Hugging Face.
2. Text to Video Model
In this section, we’ll look into text-to-video diffusion-based models.
The text-to-video model inputs a simple text prompt and generates a coherent and visually rich video. However, the text-to-video generation task is more complex than the text-to-image generation task because the former involves both spatial and temporal (in time) coherence. Here, we need to get the best visual representation of the text and simultaneously map the movements of our key objects in the video frames based on their actions in time.
Next, we’ll deep dive into ModelScope and back it up with a practical demonstration of running its pipeline to generate a video from a text prompt. But before that, let’s understand the concept of the diffusion model.
3. Diffusion Model
The diffusion model starts from pure Gaussian noise ( ) and creates new output at the current step by denoising the output of the previous step until we reach the end of the steps.
) and creates new output at the current step by denoising the output of the previous step until we reach the end of the steps.
It has two passes, namely the forward process and the backward process.
In the forward pass, we add a small amount of Gaussian noise at each step  using a fixed schedule
using a fixed schedule  . On the shadow side, in the reverse process, we use a neural network such as UNet (denoiser) that reconstructs the output sample by reversing the noising process systematically at each step with
. On the shadow side, in the reverse process, we use a neural network such as UNet (denoiser) that reconstructs the output sample by reversing the noising process systematically at each step with  .
.
So, the forward pass is a simple transformation with no learning. Further, we train the denoiser on reconstruction loss  between the predicted data
between the predicted data  and the actual data
and the actual data  . Here, the training objective is to minimize a variational lower bound (VLB) on the negative log-likelihood of data.
. Here, the training objective is to minimize a variational lower bound (VLB) on the negative log-likelihood of data.
The following figure shows a simple denoising diffusion probabilistic model (DDPM) where we fed an input image and reduced it to noise with 100-time steps in the forward pass. While in a reverse pass, we reconstructed our input image:

Hence, DDPMs also work on video scenes with spatial and temporal components in text-to-video generation, like images. Here, we inject noise in the forward pass in both spatial and temporal components. The model learns the generation of coherent spatial content on each frame and smooth transitions across frames.
4. ModelScope
In this section, we look into the ModelScope model for text-to-video generation.
4.1. Description
ModelScope extends text-to-image generation by adding the temporal domain to produce output, ensuring frame-to-frame coherence and smooth motion transitions. Here, we adapted the latent diffusion model (LDM) from the stable diffusion text to the image model to generate 3D tensors (frames over time) instead of static 2D images by adding spatial and temporal modules to support video synthesis.
It is subdivided into three functional blocks.:
- Text feature extractor,
- Latent-space diffusion model,
- Video encoder and decoder (VQGAN)
The model comprises ~1.7 billion parameters, of which around 0.5 billion are dedicated to handling temporal information via spatio-temporal blocks.
4.2. Key Components
Let’s now focus on its key components. First, a text encoder  (pretrained CLIP ViT-H/14 encoder with frozen weights) maps the input text prompt
(pretrained CLIP ViT-H/14 encoder with frozen weights) maps the input text prompt  into its dense token embeddings
into its dense token embeddings  .
.
Then, we have the VQGAN encoder  that converts a training video,
that converts a training video,  , from high-dimensional visual space to low-dimensional latent space before running the diffusion process. Essentially, it maps each visual frame
, from high-dimensional visual space to low-dimensional latent space before running the diffusion process. Essentially, it maps each visual frame  of height
of height  and width
and width  from high-dimensional visual space (space
from high-dimensional visual space (space  ) into low-dimensional latent space (
) into low-dimensional latent space ( .
.
Next, we have a modified 3D UNet diffusion model with the addition of spatio-temporal blocks. It iteratively predicts and removes noise from latent video frame tensors over a fixed schedule of timesteps  . It has four types of blocks:
. It has four types of blocks:
- Initial blocks that project input to their embedding space
- Upsampling block upsamples the feature map in visual space (pixel level)
- Downsampling block downsamples the feature map in visual space (pixel level)
- Spatio-Temporal Blocks that carry out spatial convolutions, temporal convolutions, spatial attention, and temporal attention to capture frame-to-frame dynamics
Last but not least, we have VQGAN  that maps the denoised and reconstructed latent video frames back to the visual space. Furthermore, we keep both
that maps the denoised and reconstructed latent video frames back to the visual space. Furthermore, we keep both  and frozen.
and frozen.
4.3. Architecture and Training
ModelScope text-to-video is a diffusion model that generates a video from a text prompt:
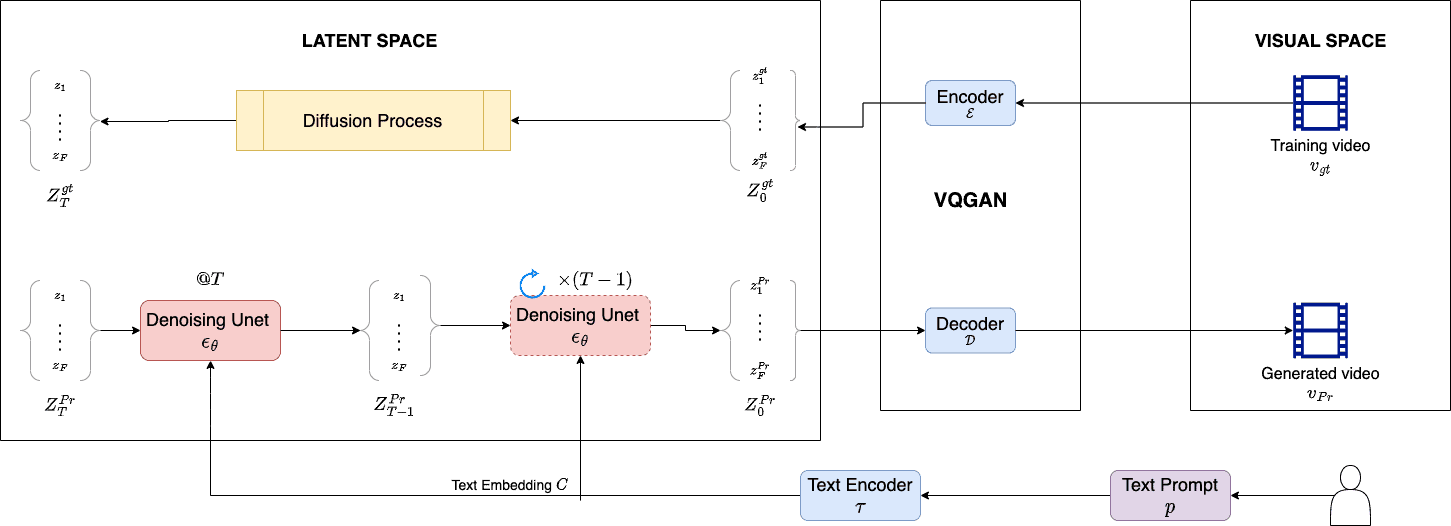
So, in training phase, each training video  is pre-processed and we sample
is pre-processed and we sample  frames
frames  . Then, we feed it to the VQGAN encoder to get its latent representation
. Then, we feed it to the VQGAN encoder to get its latent representation  .
.
In the forward pass, the denoising UNet takes as input  and adds gaussian noise
and adds gaussian noise  for
for  steps to give us
steps to give us  .
.
In the reverse path, we get the text embedding  for prompt using frozen text encoder . Then, we start at time step
for prompt using frozen text encoder . Then, we start at time step  , taking input as
, taking input as  , , and
, , and  and predict the noise
and predict the noise  . We train the denoiser on mean square error loss
. We train the denoiser on mean square error loss  between ground truth
between ground truth  and reconstructed noise :
and reconstructed noise :
(1) ![\begin{align*} \mathcal{L} = \mathbb{E}_{\mathcal{Z}_{\hat{t}},\epsilon^{gt}_{\hat{t}} \sim \mathcal{N}(0,1),\hat{t}} \left [ ||\epsilon^{gt}_{\hat{t}} - \epsilon^{pr}_{\hat{t}} ||_2^2 \right ] \end{align*}](/wp-content/ql-cache/quicklatex.com-f23ebcbb473f380f5902cffb1ae580a7_l3.svg "Rendered by QuickLaTeX.com")
Concluding the section, ModelScope is trained on text-to-image and text-to-video datasets to avoid forgetting image-domain semantics while learning temporal consistency on real video.
5. ModelScope Implementation
Now, we’ll show how to use ModelScope using PyTorch and Huggingface.
5.1. Setup
As a first step, we set up a virtual environment. Here, we can use the pyenv or virtualenv tools to create it. After activating it, we need to install the following libraries:
- torch
- torchvision
- torchaudio
- Transformers
- diffusers
- accelerate
- imageio
- imageio-ffmpeg
5.2. Libraries
Let’s load the necessary modules:
import torch
from diffusers import DiffusionPipeline
from diffusers.utils import export_to_video
Here is our configuration:
HF_TOKEN = <Use your HF token>
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = "damo-vilab/text-to-video-ms-1.7b"
fps = 8
n_seconds = 4
Here, we need to authenticate using our Huggingface token.
5.3. ModelScope Diffuser
Now, we load the ModelScope diffuser onto our available computing device (CPU, GPU, or TPU):
pipe = DiffusionPipeline.from_pretrained(model_name,
token=HF_TOKEN,
use_safetensors=True,
torch_dtype=torch.float16)
pipe = pipe.to(device)
5.4. Text Prompt
Here is our text prompt for this demo:
prompt = "a futuristic city with flying cars at sunset"
Now, let’s generate the video and save it:
video_frames = pipe(prompt, num_frames = fps * n_seconds).frames[0]
video_path = export_to_video(video_frames, output_video_path="generated_video.mp4", fps=8)
print(f"Saved video to: {video_path}")
5.5. Result
Here are a few frames from our generated video:

5.6. Compute and Memory
ModelScope Text-to-video diffusion model has high compute and memory requirements, so we executed this demo on a single GPU (NVIDIA GeForce GTX 1080) with 11 GB of memory. It used around 8.5 GB of GPU memory while generating a 4-second video with eight frames per second.
6. Conclusion
In this article, we’ve studied the fundamentals of text-to-video generation using the ModelScope text-to-video model from the Hugging Face Diffuser library. We went through the basics of diffusion models and explored the concept of latent space. Thereafter, we went deep into the workings of UNet architecture and changed it to ModelScope. Finally, we used a pre-trained ModelScope model to generate a video using a custom text prompt. We also discussed the memory requirement of this model.
Text-to-video generation is one of the most critical research areas in generative artificial intelligence. Each new model pushes the frontier by adapting existing image models for temporal coherence and motion modeling. We foresee future models that generate longer, higher-resolution videos and have fine-grained control over motion and style.