1. 简介
多任务学习(Multi-task Learning)是一种典型的迁移学习(Transfer Learning)方法,其核心思想是:通过一个模型同时学习并解决多个任务。这种训练方式通常是并行进行的,但也可以是顺序进行的。在顺序训练中,一个任务可能在后续再次出现,这就要求模型不能遗忘之前学到的知识。这种学习范式非常贴近人类的学习方式,但在实际应用中,要充分发挥其潜力并不容易。
Rich Caruana 在其博士论文中给出的经典定义是:“多任务学习是一种归纳迁移方法,通过利用多个相关任务训练信号中包含的领域信息作为归纳偏置,从而提升模型的泛化能力。”
在本文中,我们将深入解析这一定义,并探讨在实际项目中是否采用多任务学习时需要考虑的关键因素。从任务顺序、模型结构到损失函数设计,再到对模型目标的理解,我们将逐一分析。
2. 为什么要使用多任务学习?
在深度学习领域,面对复杂问题时,单任务模型往往需要大量数据和训练时间。而多任务学习提供了一种更高效、更通用的解决方案:
✅ 提升训练效率与泛化能力:多个任务共享一个骨干网络(backbone),可以从不同任务中获取训练信号,从而增强整体学习信号,加快学习速度。
✅ 辅助复杂任务的学习:一些困难任务可以通过先学习相关但更简单的任务来获得帮助。这种跨任务的知识迁移是多任务学习的重要优势之一。
多任务学习可以采用并行或顺序训练方式,具体选择取决于实际应用场景。
2.1 实现方式
我们以二分类任务为例说明多任务学习的基本结构。
在标准机器学习任务中,我们有一个数据集  ,其中包含
,其中包含  个输入向量
个输入向量  和对应的预测目标
和对应的预测目标  ,其中
,其中  是一个
是一个  维向量。
维向量。
标准的二分类交叉熵损失函数如下:
$$ \frac{1}{N}\sum^{N}_{i=1} (y_i)log(p(y_i)) + (1-y_i)log(1 - p(y_i)) $$
在多任务学习中, 变为一个  维矩阵,其中
维矩阵,其中  表示任务数量。此时,损失函数变为:
表示任务数量。此时,损失函数变为:
$$ \frac{1}{N}\sum^{N}{i=1} \sum^{T}{j=1}(y_j^ilog(p(y_j)) + (1-y_j^i)log(1 - p(y_j^i)) $$
也就是说,我们将每个任务的损失加总起来,进行统一优化。
下图展示了标准单任务学习与多任务学习模型结构的对比:
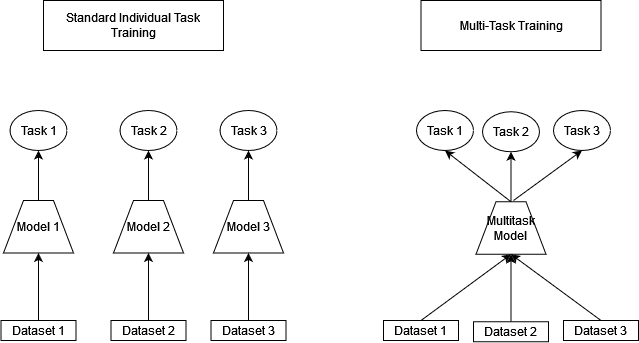
3. 实施多任务学习需要考虑哪些问题?
要真正从多任务学习中获益,以下几个关键点必须慎重考虑:
- 任务之间的相关性:不是所有任务都相互有益,有些任务之间甚至会产生负迁移(Negative Transfer),反而影响模型性能。
- 任务训练顺序:是并行训练还是顺序训练?是否需要冻结部分网络?
- 任务权重设计:如何平衡不同任务的损失函数?
- 网络共享程度:哪些层共享?哪些层任务专用?
3.1 平衡损失函数
当多个任务共存时,它们的损失函数可能具有不同的量纲和优化方向。因此:
✅ 需要对不同任务的损失进行加权:比如分类任务和回归任务的损失差异明显,需要通过缩放其中一个损失值来避免其主导整个训练过程。
✅ 样本数量不平衡:如果某个任务的数据远多于其他任务,也要对损失进行加权平衡,以确保各任务性能均衡。
✅ 采样策略:均匀采样可能造成某些任务训练不足,采用加权采样或动态采样(如偏向于表现较差的任务)有助于提升整体性能。
3.2 网络结构共享程度
✅ 共享骨干网络:在 NLP、CV 等领域,通常采用一个共享的骨干网络(如 Transformer),然后为每个任务添加任务专用的头部(Head)。
✅ 共享与专用的权衡:骨干网络的大小、任务头的设计等都需要根据任务特点进行调整。
⚠️ 踩坑提醒:不要盲目增加共享层的数量,否则可能导致任务之间干扰加剧,反而影响性能。
3.3 软共享(Soft Sharing)
在软共享策略中,模型训练过程中会冻结部分网络参数,以保留已有任务的知识,同时允许其他任务在未冻结部分学习新知识。
✅ 实现方式:例如 Cross-Stitch Networks、Semi-Freddo Nets 等架构允许不同任务共享部分特征空间,同时保留任务特异性。
✅ 优势:可实现模块化学习,提升模型的灵活性与适应性。
4. 强化学习中的多任务学习
在强化学习(Reinforcement Learning)场景中,任务往往不是同时出现的,而是按顺序出现且可能重复。因此,多任务学习在此领域还面临一个挑战:灾难性遗忘(Catastrophic Forgetting)。
✅ 机器人控制是一个典型应用:强化学习通常数据效率低,训练慢,而多任务学习可以通过任务间的经验共享大幅提升性能。
⚠️ 踩坑提醒:在强化学习中引入多任务机制时,务必考虑任务间的依赖关系和训练策略,否则容易出现任务干扰。
5. 何时使用多任务学习?
多任务学习并非万能,其适用场景具有一定的限制。以下情况建议优先考虑使用多任务学习:
✅ 任务之间具有相关性:共享特征越多,效果越好。
✅ 各任务数据量相近:若某个任务数据远多于其他任务,可能会主导训练过程,需谨慎设计损失权重。
✅ 模型容量足够大:大模型能更好捕捉通用特征与任务特异性特征。
✅ 部分样本缺失标签:多任务学习允许部分任务在某些样本上缺失标签,只需在对应任务上跳过损失计算即可。
⚠️ 踩坑提醒:如果任务之间差异较大或数据分布差异显著,强行使用多任务学习可能导致性能下降。
6. 总结
本文系统介绍了多任务学习的基本概念、实现方式以及实际应用中需要注意的问题。
- 多任务学习通过共享模型结构和训练信号,可以提升模型泛化能力和训练效率。
- 任务相关性、损失函数设计、网络共享结构是实施多任务学习的关键。
- 在强化学习、机器人控制等场景中,多任务学习也有广泛应用。
- 实施时应避免任务冲突、样本不平衡、灾难性遗忘等问题。
✅ 适用场景:任务相关性强、数据分布一致、任务数量适中、样本部分缺失。
❌ 不推荐场景:任务差异大、任务数量过多、任务之间存在竞争关系。
多任务学习是一个强大但需谨慎使用的技术,只有在任务间存在潜在共享信息时,才能发挥其最大价值。