1. 概述
在计算机科学中,存在多种可以在多处理器计算机上运行的并行算法,例如多线程算法。
在本教程中,我们将了解这种并行计算模型的含义,并通过一个具体示例来加深理解。
2. 动态多线程概念
多线程是现代计算中一个关键主题。并行计算模型有多种,彼此之间存在显著差异。例如,内存可以是共享的,也可以是分布式的。由于多核处理器已经普及,我们主要关注基于共享内存的并行计算模型。
2.1 动态与静态多线程
- 静态多线程:程序员需要在程序执行的每个阶段预先指定使用多少处理器。这种方式在面对动态变化的条件时缺乏灵活性。
- 动态多线程:程序员只需指出潜在的并行机会,而具体的线程调度由并发平台自动管理。
2.2 并发构造
并发平台是一个软件层,负责调度、管理和协调并行计算资源。我们使用一个简单的串行编程模型扩展来反映当前的并行实践:
- spawn:父线程可以与子线程并行执行,而不是等待子线程完成
- sync:线程必须等待所有 spawned 子线程完成后再继续执行
- parallel:用于指示每个迭代都可以并行执行(如
parallel for)
⚠️ 注意:parallel 和 spawn 关键字并不代表强制并行,而是表示“逻辑并行性”。当使用并行性时,必须尊重 sync。每个过程在末尾都有一个隐式的 sync,以确保安全性。
3. 示例:并行斐波那契数列计算
我们来看一个原本效率较低的斐波那契数列计算算法,并尝试将其并行化。
斐波那契数列定义如下:
$$ \begin{cases} F_{0} = 0 \ F_{1} = 1 \ F_{i} = F_{i-1} + F_{i-2}, \text{ for } i \geq 2 \end{cases} $$
以下是基于该定义的非并行算法:
algorithm FIB(n):
if n <= 1:
return n
else:
x <- FIB(n - 1)
y <- FIB(n - 2)
return x + y
这是该算法的递归调用树:
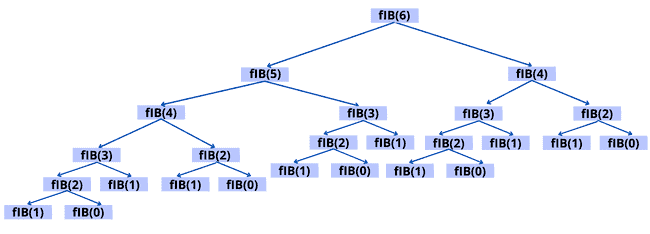
如果我们使用并发关键字来并行执行两个递归调用,可以得到如下改进版本:
algorithm P-FIB(n):
if n <= 1:
return n
else:
x <- spawn P-FIB(n - 1) // 并行执行
y <- spawn P-FIB(n - 2) // 并行执行
sync // 等待结果
return x + y
4. 动态多线程建模
为了更好地描述并行计算过程,我们需要一个形式化的模型。
4.1 计算 DAG(有向无环图)
我们可以使用计算 DAG(Directed Acyclic Graph)来建模多线程计算 $ G = (V, E) $:
- 顶点(V):代表指令。为简化模型,我们把每个顶点视为一个“strand”(不包含并行控制语句的指令序列)
- 边(E):代表指令之间的依赖关系。边 $ (u, v) \in E $ 表示指令 $ u $ 必须在 $ v $ 之前执行
如果两个线程之间有边,则它们是串行关系;否则是并行关系。
4.2 边的分类
- 延续边(Continuation edge):表示同一个过程中的指令顺序执行
- spawn 边(Spawn edge):表示一个线程 spawn 了另一个线程
- 返回边(Return edge):表示子线程执行完毕后返回到调用线程
4.3 模型可视化
我们来看一下使用线程的并行斐波那契算法:
algorithm P-FIB(n):
if n <= 1:
return n // Thread A
else:
x <- spawn P-FIB(n - 1) // Thread A continues
y <- spawn P-FIB(n - 2) // Thread B
sync // wait for results
return x + y // Thread C combines results
这是 P-FIB(4) 的 DAG 模型图:
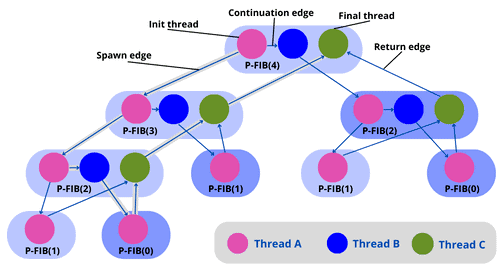
如图所示,线程 4 spawn 线程 3,线程 3 spawn 线程 2,线程 2 spawn 线程 1,之后通过返回边依次返回结果,最终合并到线程 4。
5. 多线程性能度量
接下来我们介绍几个衡量动态多线程性能的重要指标。
5.1 Work(工作量)
Work 表示整个计算在单个处理器上执行所需的总时间。它等于所有线程执行时间的总和。
在一个拥有 $ P $ 个处理器的理想并行计算机上,单位时间内最多可完成 $ P $ 单位的工作。因此:
$$ T_P \geq \frac{T_1}{P} $$
这就是所谓的工作定律。
5.2 Span(跨度)
Span 是计算 DAG 中最长路径的执行时间,即从起点到终点所需的最大时间。
理想并行计算机无法比无限处理器机器运行得更快。因此:
$$ T_P \geq T_\infty $$
这就是所谓的跨度定律。
5.3 加速比与并行度
- 加速比:$ \frac{T_1}{T_P} $,表示在 $ P $ 个处理器上比单个处理器快多少
- 并行度:$ \frac{T_1}{T_\infty} $,表示平均每个并行执行步骤可以完成多少工作
根据工作定律,理想并行计算机的加速比不能超过处理器数量。
5.4 松弛度(Slackness)
松弛度定义为:
$$ \text{Slackness} = \frac{T_1 / T_\infty}{P} $$
它表示在给定处理器数量下,并行性是否被充分利用。
5.5 性能度量示例
以 P-FIB(4) 为例,DAG 中有 17 个线程(顶点),最长路径上有 8 个线程(红色路径)。
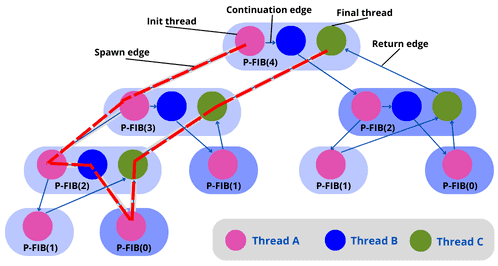
假设每个线程执行时间为 1 单位:
- Work:17 单位
- Span:8 单位
进一步分析:
- **Work $ T_1 $**:$ \theta\left(\left(\frac{1+\sqrt{5}}{2}\right)^n\right) $
- **Span $ T_\infty $**:$ \theta(n) $
- 并行度:$ \theta\left(\frac{(\frac{1+\sqrt{5}}{2})^n}{n}\right) $,随着 $ n $ 增大迅速增长
6. 其他并行算法示例
6.1 并行矩阵乘法算法
使用嵌套的 parallel for 来并行化矩阵乘法:
algorithm P-Matrix-Multiply(A, B):
n <- number of rows in A
C <- initialize an empty n x n matrix
parallel for i <- 1 to n:
parallel for j <- 1 to n:
c[i, j] <- 0
for k <- 1 to n:
c[i, j] <- c[i, j] + a[i, k] * b[k, j]
return C
- Work:$ \theta(n^3) $
- Span:$ \theta(n) $
- 并行度:$ \theta(n^2) $
6.2 并行归并排序算法
归并排序非常适合并行化,因为其分治结构天然支持子问题并行:
algorithm Merge-Sort(a, p, r):
if p < r:
q <- (p + r) / 2
spawn Merge-Sort(a, p, q)
Merge-Sort(a, q+1, r)
sync
Merge(a, p, q, r)
- Work:$ \theta(n \log n) $
- Span:$ \theta(n) $
- 并行度:$ \theta(\log n) $
⚠️ 踩坑提醒:归并操作是串行的,这限制了整体并行度。若想提升性能,可以尝试并行化归并步骤。
7. 多线程应用场景
多线程技术广泛应用于以下场景:
- ✅ 数据集的并发访问
- ✅ Web 服务器在监听端口的同时处理新连接
- ✅ 在后台线程加密文件,同时主线程保持应用运行
8. 小结
在本教程中,我们通过斐波那契数列和矩阵乘法等示例,介绍了动态多线程算法的基本概念和建模方法(DAG)。我们还分析了 Work、Span、加速比、并行度等性能指标,并讨论了它们在实际应用中的意义。
如果你正在开发高性能并行系统,理解这些概念将帮助你更好地设计算法、评估性能瓶颈,并做出更优的架构决策。