1. 概述
本文将解释机器学习中一个基础但非常重要的概念:朴素贝叶斯分类(Naive Bayes Classification)。
阅读本文后,你将理解为什么在进行科学预测时,了解和处理我们的先验知识(a priori knowledge)是至关重要的。我们还会实现一个简单的贝努利分类器(Bernoulli Classifier),它使用贝叶斯定理作为其预测函数。
最终,你将对统计学中最基本的定理之一有直观的理解,并看到它在算法中的一种实现方式。
2. 贝叶斯定理
贝叶斯定理是所有贝叶斯分类器的基础,它的公式如下:
$$ P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} $$
其中:
- $ P(A) $ 和 $ P(B) $ 是事件 A 和 B 的先验概率(即不考虑其他条件下的独立发生概率)
- $ P(A|B) $ 是在事件 B 发生的前提下,事件 A 发生的条件概率
- $ P(B|A) $ 是在事件 A 发生的前提下,事件 B 发生的条件概率
✅ 关键点:公式中的 $ P(A) $ 和 $ P(B) $ 是所谓的“先验”(a priori)概率,它们是我们对系统行为的假设。
3. 什么是“先验”概率?为什么它重要?
3.1. “先验”的含义
“A priori” 是拉丁语,意思是“未经验证”或“假设的”。在概率论中,它指的是我们在没有观察数据之前,对某个事件发生可能性的主观估计。
3.2. 一个文本分类的小游戏
我们来做个小游戏:你面对一组英文文本,你的任务是判断一个新文本是否谈论“动物(animals)”。
这些文本如下图所示:
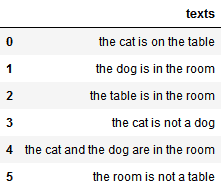
你不会英文,所以不能靠语义判断。你只能根据文本中出现的词语来推测它是否属于“动物”类别。
游戏流程如下:

这种任务在自然语言处理中被称为文本分类(text classification)。
4. 如何用贝叶斯做猜测?
4.1. 没有先验知识能做预测吗?
不能。如果你对类别分布一无所知,就无法做出任何有意义的预测。
❌ 常见误区:有人会说“我随机猜一半是动物,一半不是动物”。但这种做法其实引入了“类别分布是均匀的”这一额外假设,属于引入了先验知识。
4.2. 拥有类别分布的先验知识后
游戏主持人给了你一些信息:每段文本对应的标签。
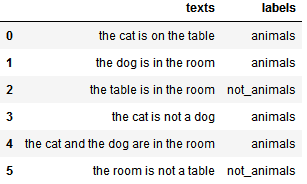
此时你可以做第一个简单猜测:
✅ 猜测1:新文本属于在训练集中出现频率最高的类别。
比如,在6个文本中,4个是动物类,2个不是。那我们可以猜测新文本是动物类的概率是 4/6 = 0.66。
这不需要理解语言,也不需要理解词语,只需要知道类别分布即可。

4.3. 加入词语特征后的猜测
接下来我们考虑文本内容。我们知道,有些词更可能出现在动物类文本中。
✅ 猜测2:如果一个词曾经出现在动物类文本中,那么包含这个词的新文本更可能属于动物类。
我们以第一个词“the”为例,看看它是否有助于分类:
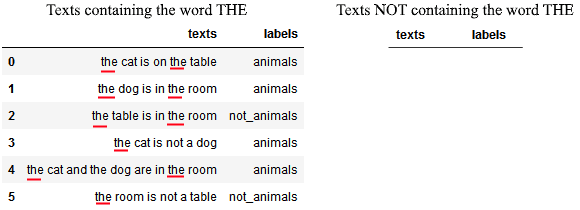
我们计算:
$$ P(animals | THE) = \frac{P(THE | animals) \cdot P(animals)}{P(THE)} = \frac{1 \cdot 0.66}{1} = 0.66 = P(animals) $$
⚠️ 结果和之前一样。说明“the”这个词并不能提供额外信息。
再看第二个词“cat”:

我们计算:
$$ P(animals | CAT) = \frac{P(CAT | animals) \cdot P(animals)}{P(CAT)} = \frac{0.75 \cdot 0.66}{0.5} = 1 $$
✅ 这个结果非常强,说明只要出现“cat”,几乎可以确定是动物类文本。
我们可以为每个词计算类似条件概率:

5. 对先验知识过于自信的风险
我们可以把上面的条件概率表当作一个“查找表”来用,只要新文本中出现某个词,就判断为动物类。
比如:
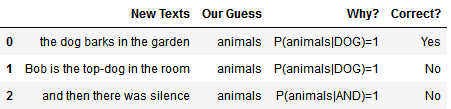
⚠️ 但这种做法风险很大:如果我们对先验知识过于自信,就会忽视与之相矛盾的新证据。这在机器学习中被称为“过拟合”。
6. 对贝叶斯定理的理性解读
6.1. 没有假设就无法预测
这个小游戏告诉我们一个道理:没有大量关于系统行为的先验知识,预测是不可能的。
✅ 贝叶斯定理的理性解释就是:预测依赖于我们的先验假设,预测结果的准确性取决于这些假设的合理性。
6.2. 假设虽好,但不要过度依赖
我们越依赖先验知识,预测可能越准确,但也会导致模型过于拟合训练数据,泛化能力下降。
6.3. 中庸之道才是最佳
✅ 结论:既要相信自己的知识,也要保持开放态度,根据新证据不断更新认知。
这就是贝叶斯分类器的运行机制:在训练阶段,它根据数据不断调整对特征的先验概率估计。
7. 实现一个贝努利朴素贝叶斯分类器
如果你有兴趣自己动手实现一个朴素贝叶斯分类器,可以使用 Python 和 scikit-learn:
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import BernoulliNB
corpus = [
'the cat is on the table',
'the dog is in the room',
'the table is in the room',
'the cat is not a dog',
'the cat and the dog are in the room',
'the room is not a table'
]
labels = ['animals', 'animals', 'not_animals', 'animals', 'animals', 'not_animals']
df = pd.DataFrame({'Texts': corpus, 'Labels': labels})
cv = CountVectorizer(token_pattern='\w+')
BoW = cv.fit_transform(df['Texts'])
classifier = BernoulliNB()
classifier.fit(BoW, df['Labels'])
predictions = classifier.predict(BoW)
df['Predictions'] = predictions
print(df)
运行结果如下:
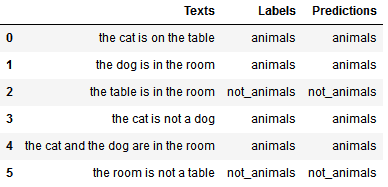
8. 总结
贝叶斯定理告诉我们:所有概率本质上都是基于某些先验假设的条件概率。
✅ 关键结论:
- 没有未经验证的假设,就无法做出预测
- 对先验知识过于自信会阻碍学习新知识
- 最佳策略是保持对已有知识的一定信任,同时根据新证据不断更新认知
朴素贝叶斯分类器正是基于这一理念实现的:它在训练过程中不断调整对特征的先验概率估计,从而提升预测准确性。